Sistema de recomendación es un sistema que busca predecir o filtrar las preferencias según las elecciones del usuario. Los sistemas de recomendación se utilizan en una variedad de áreas que incluyen películas, música, noticias, libros, artículos de investigación, consultas de búsqueda, etiquetas sociales y productos en general.
Los sistemas de recomendación producen una lista de recomendaciones en cualquiera de las dos formas:
- Filtrado colaborativo: los enfoques de filtrado colaborativo construyen un modelo a partir del comportamiento anterior del usuario (es decir, artículos comprados o buscados por el usuario), así como decisiones similares tomadas por otros usuarios. Luego, este modelo se usa para predecir elementos (o calificaciones de elementos) en los que los usuarios pueden estar interesados.
- Filtrado basado en contenido: los enfoques de filtrado basados en contenido utilizan una serie de características discretas de un elemento para recomendar elementos adicionales con propiedades similares. Los métodos de filtrado basados en el contenido se basan totalmente en una descripción del elemento y un perfil de las preferencias del usuario. Recomienda elementos basados en las preferencias anteriores del usuario.
Desarrollemos un sistema de recomendación básico usando Python y Pandas.
Centrémonos en proporcionar un sistema de recomendación básico sugiriendo artículos que son más similares a un artículo en particular, en este caso, películas. Simplemente indica qué películas/elementos son más similares a la elección de películas del usuario.
Para descargar los archivos, haga clic en los enlaces: archivo .tsv , Movie_Id_Titles.csv .
Importe el conjunto de datos con el delimitador «\t» ya que el archivo es un archivo tsv (archivo separado por tabuladores).
Python3
# import pandas library import pandas as pd # Get the data column_names = ['user_id', 'item_id', 'rating', 'timestamp'] path = 'https://media.geeksforgeeks.org/wp-content/uploads/file.tsv' df = pd.read_csv(path, sep='\t', names=column_names) # Check the head of the data df.head()
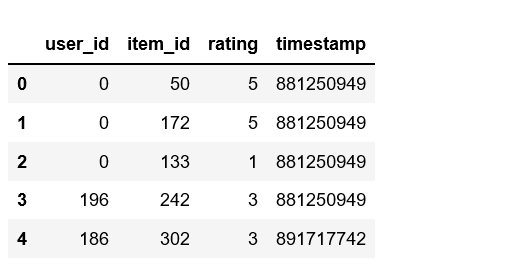
Python3
# Check out all the movies and their respective IDs
movie_titles = pd.read_csv('https://media.geeksforgeeks.org/wp-content/uploads/Movie_Id_Titles.csv')
movie_titles.head()
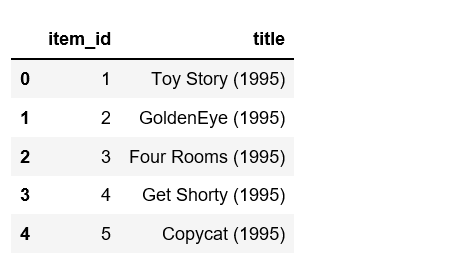
Python3
data = pd.merge(df, movie_titles, on='item_id') data.head()
Python3
# Calculate mean rating of all movies
data.groupby('title')['rating'].mean().sort_values(ascending=False).head()

Python3
# Calculate count rating of all movies
data.groupby('title')['rating'].count().sort_values(ascending=False).head()

Python3
# creating dataframe with 'rating' count values
ratings = pd.DataFrame(data.groupby('title')['rating'].mean())
ratings['num of ratings'] = pd.DataFrame(data.groupby('title')['rating'].count())
ratings.head()
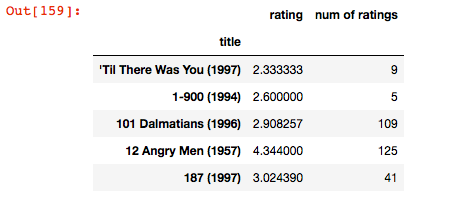
Importaciones de visualización:
Python3
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('white')
%matplotlib inline
Python3
# plot graph of 'num of ratings column' plt.figure(figsize =(10, 4)) ratings['num of ratings'].hist(bins = 70)
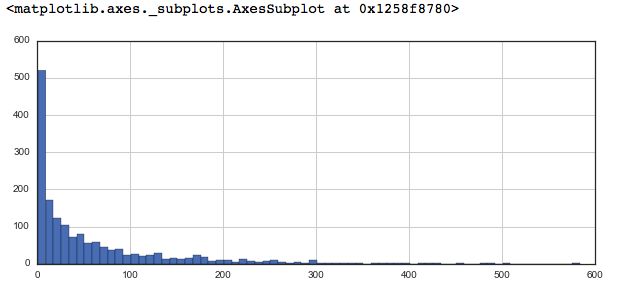
Python3
# plot graph of 'ratings' column plt.figure(figsize =(10, 4)) ratings['rating'].hist(bins = 70)
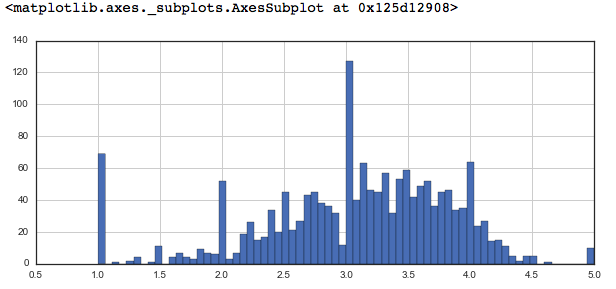
Python3
# Sorting values according to
# the 'num of rating column'
moviemat = data.pivot_table(index ='user_id',
columns ='title', values ='rating')
moviemat.head()
ratings.sort_values('num of ratings', ascending = False).head(10)
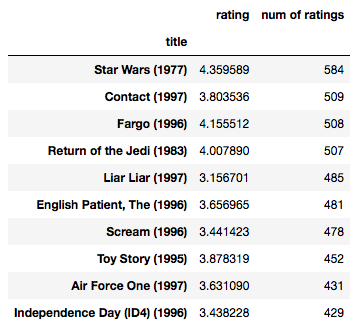
Python3
# analysing correlation with similar movies starwars_user_ratings = moviemat['Star Wars (1977)'] liarliar_user_ratings = moviemat['Liar Liar (1997)'] starwars_user_ratings.head()

Python3
# analysing correlation with similar movies similar_to_starwars = moviemat.corrwith(starwars_user_ratings) similar_to_liarliar = moviemat.corrwith(liarliar_user_ratings) corr_starwars = pd.DataFrame(similar_to_starwars, columns =['Correlation']) corr_starwars.dropna(inplace = True) corr_starwars.head()
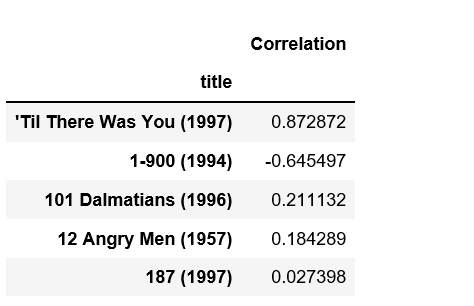
Python3
# Similar movies like starwars
corr_starwars.sort_values('Correlation', ascending = False).head(10)
corr_starwars = corr_starwars.join(ratings['num of ratings'])
corr_starwars.head()
corr_starwars[corr_starwars['num of ratings']>100].sort_values('Correlation', ascending = False).head()
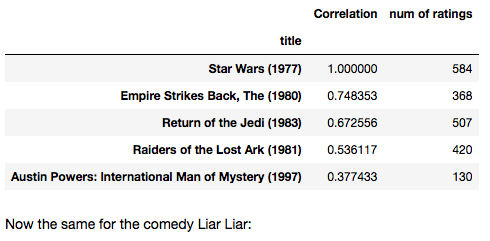
Python3
# Similar movies as of liarliar
corr_liarliar = pd.DataFrame(similar_to_liarliar, columns =['Correlation'])
corr_liarliar.dropna(inplace = True)
corr_liarliar = corr_liarliar.join(ratings['num of ratings'])
corr_liarliar[corr_liarliar['num of ratings']>100].sort_values('Correlation', ascending = False).head()
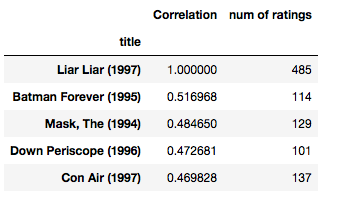
Publicación traducida automáticamente
Artículo escrito por aishwarya.27 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA