El lenguaje Python es uno de los lenguajes de programación más populares, ya que es más dinámico que otros. Python es un lenguaje simple de alto nivel y de código abierto que se utiliza para la programación de propósito general. Tiene muchas bibliotecas de código abierto y Pandas es una de ellas. Pandas es una biblioteca de código abierto potente, rápida y flexible que se utiliza para el análisis de datos y la manipulación de marcos de datos/conjuntos de datos. Pandas se puede usar para leer y escribir datos en un conjunto de datos de diferentes formatos como CSV (valores separados por comas), txt, xls (Microsoft Excel), etc.
En esta publicación, aprenderá sobre varias características de Pandas en Python y cómo usar para practicar.
Prerrequisitos: Conocimientos básicos sobre codificación en Python.
Instalación:
Entonces, si es nuevo en la práctica de Pandas, primero debe instalar Pandas en su sistema.
Vaya al símbolo del sistema y ejecútelo como administrador. Asegúrese de estar conectado con una conexión a Internet para descargarlo e instalarlo en su sistema.
Luego escriba » pip install pandas «, luego presione la tecla Intro.

Descargue el conjunto de datos «Iris.csv» desde aquí El conjunto de
datos de Iris es el Hola Mundo para la ciencia de datos, por lo que si ha comenzado su carrera en ciencia de datos y aprendizaje automático, practicará algoritmos básicos de ML en este famoso conjunto de datos. El conjunto de datos de Iris contiene cinco columnas, como Longitud de pétalo, Ancho de pétalo, Longitud de sépalo, Ancho de sépalo y Tipo de especie.
Iris es una planta con flores, los investigadores midieron varias características de las diferentes flores de iris y las registraron digitalmente.
Comenzando con Pandas:
Código: Importación de pandas para usar en nuestro código como pd.
Python3
import pandas as pd
Código: Lectura del conjunto de datos “Iris.csv”.
Python3
data = pd.read_csv("your downloaded dataset location ")

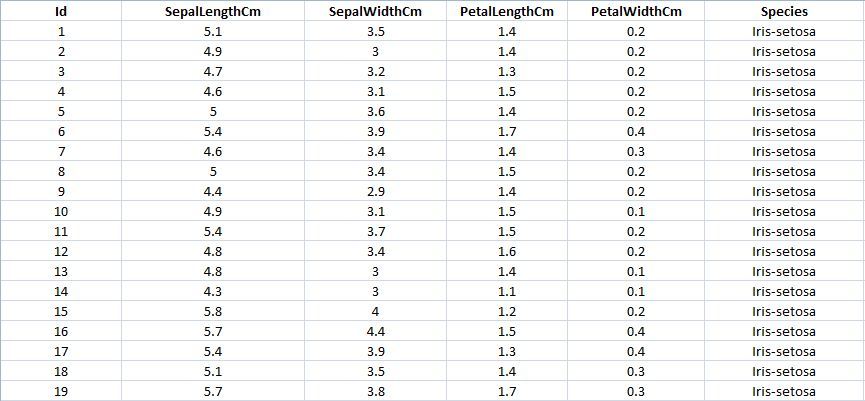
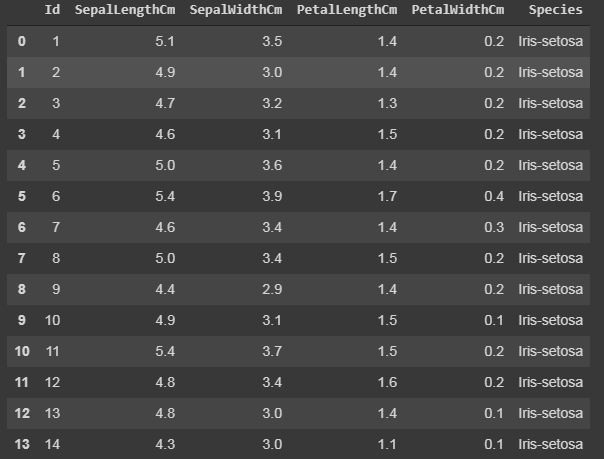
Código: Mostrar las filas superiores del conjunto de datos con sus columnas
La función head() mostrará las filas superiores del conjunto de datos, el valor predeterminado de esta función es 5, es decir, mostrará las 5 filas superiores cuando no se proporcione ningún argumento para eso.
Python3
data.head()
Producción:
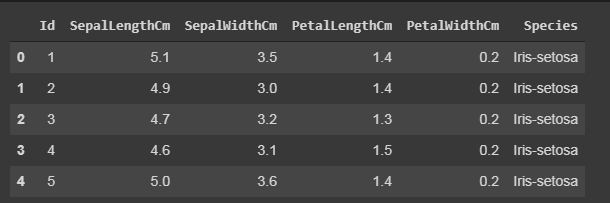
Mostrar el número de filas al azar.
En la función sample(), también mostrará las filas de acuerdo con los argumentos dados, pero mostrará las filas al azar.
Python3
data.sample(10)
Producción:
Código: Visualización del número de columnas y nombres de las columnas.
La función column() imprime todas las columnas del conjunto de datos en forma de lista.
Python3
data.columns
Producción:

Código: Mostrar la forma del conjunto de datos.
La forma del conjunto de datos significa imprimir el número total de filas o entradas y el número total de columnas o características de ese conjunto de datos en particular.
Python3
#The first one is the number of rows and # the other one is the number of columns. data.shape
Producción:

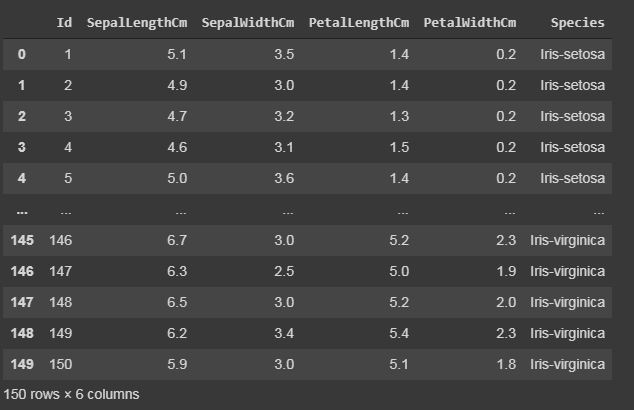
Código: muestra todo el conjunto de datos
Python3
print(data)
Producción:
Código: Cortar las filas.
Cortar significa si desea imprimir o trabajar en un grupo particular de líneas que va desde la fila 10 a la fila 20.
Python3
#data[start:end] #start is inclusive whereas end is exclusive print(data[10:21]) # it will print the rows from 10 to 20. # you can also save it in a variable for further use in analysis sliced_data=data[10:21] print(sliced_data)
Producción:
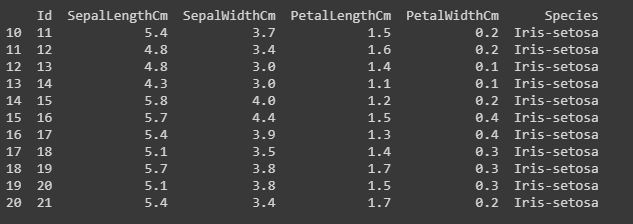
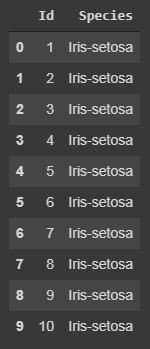
Código: Mostrar solo columnas específicas.
En cualquier conjunto de datos, a veces es necesario trabajar solo con características o columnas específicas, por lo que podemos hacerlo con el siguiente código.
Python3
#here in the case of Iris dataset #we will save it in a another variable named "specific_data" specific_data=data[["Id","Species"]] #data[["column_name1","column_name2","column_name3"]] #now we will print the first 10 columns of the specific_data dataframe. print(specific_data.head(10))
Producción:
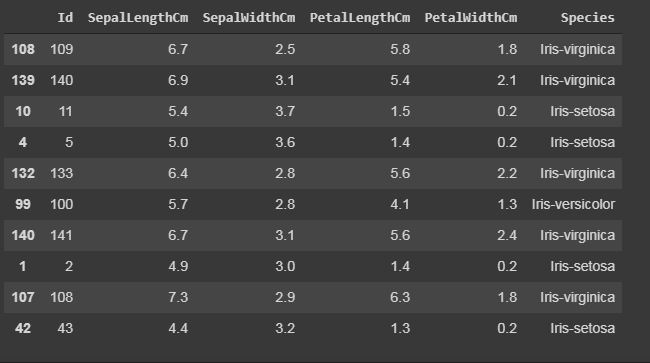
Filtrado: Visualización de filas específicas utilizando las funciones «iloc» y «loc».
Las funciones «loc» usan el nombre de índice de la fila para mostrar la fila particular del conjunto de datos.
Las funciones «iloc» usan el índice entero de la fila, lo que brinda información completa sobre la fila.
Código:
Python3
#here we will use iloc data.iloc[5] #it will display records only with species "Iris-setosa". data.loc[data["Species"] == "Iris-setosa"]
Producción:
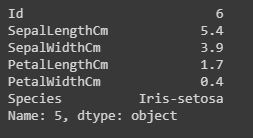
iloc()[/título]
ubicación()
Código: contar el número de conteos de valores únicos usando “value_counts()”.
La función value_counts() cuenta el número de veces que ha ocurrido una instancia o datos en particular.
Python3
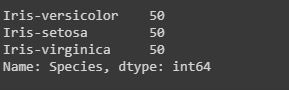
#In this dataset we will work on the Species column, it will count number of times a particular species has occurred. data["Species"].value_counts() #it will display in descending order.
Producción:
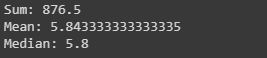
Cálculo de la suma, la media y la moda de una columna en particular.
También podemos calcular la suma, la media y la moda de cualquier columna de enteros como lo he hecho en el siguiente código.
Python3
# data["column_name"].sum()
sum_data = data["SepalLengthCm"].sum()
mean_data = data["SepalLengthCm"].mean()
median_data = data["SepalLengthCm"].median()
print("Sum:",sum_data, "\nMean:", mean_data, "\nMedian:",median_data)
Producción:
Código: Extracción de mínimo y máximo de una columna.
La identificación del número entero mínimo y máximo, de una columna o fila en particular, también se puede hacer en un conjunto de datos.
Python3
min_data=data["SepalLengthCm"].min()
max_data=data["SepalLengthCm"].max()
print("Minimum:",min_data, "\nMaximum:", max_data)
Producción:

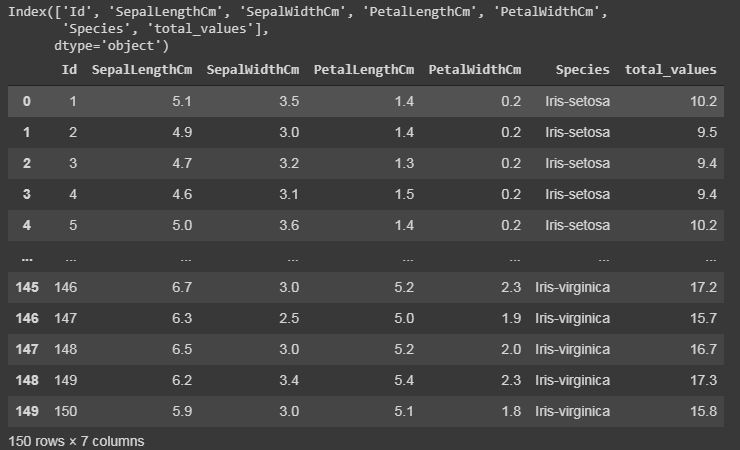
Código: agregar una columna al conjunto de datos.
Si desea agregar una nueva columna en nuestro conjunto de datos, ya que estamos haciendo cálculos o extrayendo información del conjunto de datos, y si desea guardarlo en una nueva columna. Esto se puede hacer con el siguiente código tomando un caso en el que hemos agregado todos los valores enteros de todas las columnas.
Python3
# For example, if we want to add a column let say "total_values", # that means if you want to add all the integer value of that particular # row and get total answer in the new column "total_values". # first we will extract the columns which have integer values. cols = data.columns # it will print the list of column names. print(cols) # we will take that columns which have integer values. cols = cols[1:5] # we will save it in the new dataframe variable data1 = data[cols] # now adding new column "total_values" to dataframe data. data["total_values"]=data1[cols].sum(axis=1) # here axis=1 means you are working in rows, # whereas axis=0 means you are working in columns.
Producción:
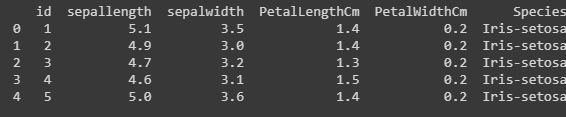
Código: Cambio de nombre de las columnas.
También es posible cambiar el nombre de nuestras columnas en las bibliotecas de python pandas. Hemos utilizado la función de cambio de nombre(), donde hemos creado un diccionario «newcols» para actualizar nuestros nuevos nombres de columna. El siguiente código ilustra eso.
Python3
newcols={
"Id":"id",
"SepalLengthCm":"sepallength"
"SepalWidthCm":"sepalwidth"}
data.rename(columns=newcols,inplace=True)
print(data.head())
Producción:
Formato y estilo:
el formato condicional se puede aplicar a su marco de datos mediante el uso de la función Dataframe.style. El estilo se usa para visualizar sus datos, y la forma más conveniente de visualizar su conjunto de datos es en forma tabular.
Aquí resaltaremos el mínimo y el máximo de cada fila y columna.
Python3
#this is an example of rendering a datagram, which is not visualised by any styles. data.style
Producción:
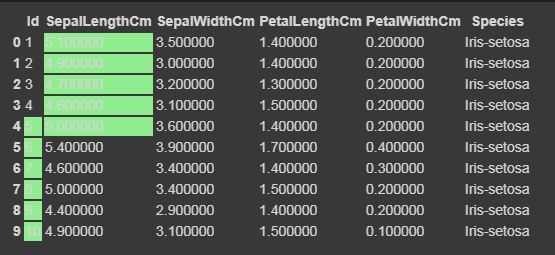
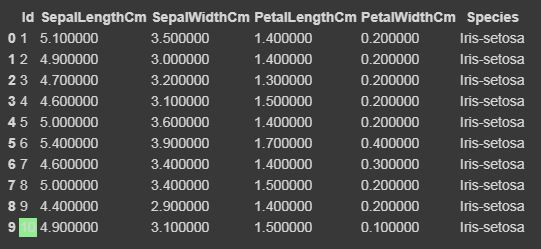
Ahora resaltaremos el máximo y el mínimo en forma de columna, en forma de fila y en todo el marco de datos utilizando la función Styler.apply. La función Styler.apply pasa cada columna o fila del marco de datos según el eje del argumento de la palabra clave. Para la columna, use el eje = 0, la fila, use el eje = 1, y para toda la tabla a la vez, use el eje = Ninguno.
Python3
# we will here print only the top 10 rows of the dataset, # if you want to see the result of the whole dataset remove #.head(10) from the below code data.head(10).style.highlight_max(color='lightgreen', axis=0) data.head(10).style.highlight_max(color='lightgreen', axis=1) data.head(10).style.highlight_max(color='lightgreen', axis=None)
Producción:
para eje=0
para eje=1
para eje=Ninguno
Código: limpieza y detección de valores faltantes
En este conjunto de datos, ahora intentaremos encontrar los valores faltantes, es decir, NaN, que pueden ocurrir debido a varias razones.
Python3
data.isnull() #if there is data is missing, it will display True else False.
Producción:
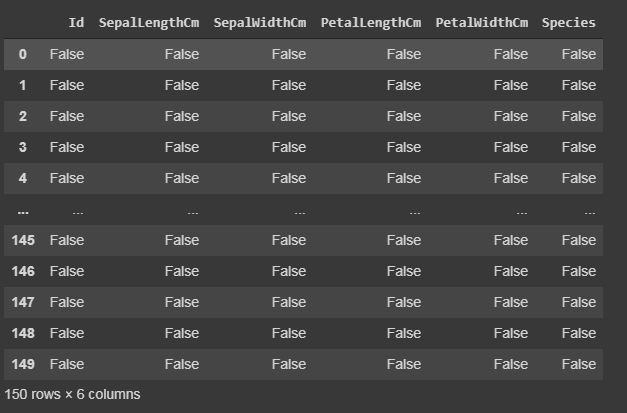
es nulo()
Código: Resumen de los valores faltantes.
Mostraremos cuántos valores faltantes están presentes en cada columna.
Python3
data.isnull.sum()
Producción:
Mapa de calor: Importación de Seaborn
El mapa de calor es una técnica de visualización de datos que se utiliza para analizar el conjunto de datos como colores en dos dimensiones. Básicamente, muestra la correlación entre todas las variables numéricas en el conjunto de datos. Heatmap es un atributo de la biblioteca Seaborn.
Código:
Python3
import seaborn as sns
iris = sns.load_dataset("iris")
sns.heatmap(iris.corr(),camp = "YlGnBu", linecolor = 'white', linewidths = 1)
Producción:

Código: anote cada celda con el valor numérico utilizando el formato de entero
Python3
sns.heatmap(iris.corr(),camp = "YlGnBu", linecolor = 'white', linewidths = 1, annot = True )
Producción:
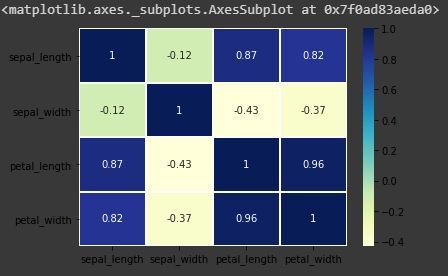
mapa de calor con annot=True
Correlación de marco de datos de Pandas: la
correlación de Pandas se utiliza para determinar la correlación por pares de todas las columnas del conjunto de datos. En dataframe.corr(), los valores faltantes se excluyen y las columnas no numéricas también se ignoran.
Código:
Python3
data.corr(method='pearson')
Producción:
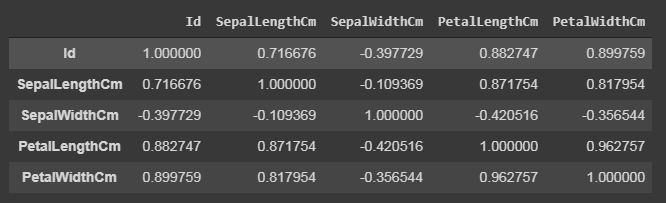
datos.corr()
El marco de datos de salida se puede ver como para cualquier celda, la correlación de la variable de fila con la variable de columna es el valor de la celda. La correlación de una variable consigo misma es 1. Por eso, todos los valores de la diagonal son 1.00.
Análisis multivariante:
el gráfico de pares se utiliza para visualizar la relación entre cada tipo de variable de columna. Se implementa solo mediante un código de línea, que es el siguiente:
Código:
Python3
g = sns.pairplot(data,hue="Species")
Producción:
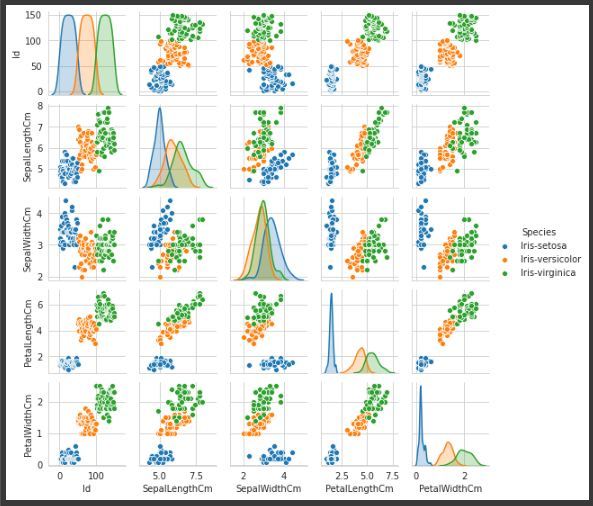
Pairplot de la variable “Species”, para hacerlo más comprensible.
Publicación traducida automáticamente
Artículo escrito por kashishlohiya5 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA