1. Descarga, instalación e inicio de Python SciPy
Obtenga la plataforma Python y SciPy instalada en su sistema si aún no lo está. Uno puede seguir fácilmente la guía de instalación para ello.
1.1 Instalar bibliotecas SciPy:
Trabajando en Python versión 2.7 o 3.5+.
Hay 5 bibliotecas clave que necesitará instalar. A continuación se muestra una lista de las bibliotecas de Python SciPy requeridas para este tutorial:
- espía
- entumecido
- matplotlib
- pandas
- aprender
1.2 Inicie Python y verifique las versiones:
Es una buena idea asegurarse de que su entorno de Python se instaló correctamente y funciona como se esperaba.
La siguiente secuencia de comandos ayudará a probar el entorno. Importa cada biblioteca requerida en este tutorial e imprime la versión.
Escriba o copie y pegue el siguiente script:
Python3
# Check the versions of libraries
# Python version
import sys
print('Python: {}'.format(sys.version))
# scipy
import scipy
print('scipy: {}'.format(scipy.__version__))
# numpy
import numpy
print('numpy: {}'.format(numpy.__version__))
# matplotlib
import matplotlib
print('matplotlib: {}'.format(matplotlib.__version__))
# pandas
import pandas
print('pandas: {}'.format(pandas.__version__))
# scikit-learn
import sklearn
print('sklearn: {}'.format(sklearn.__version__))
Si surge un error, deténgase. Ahora es el momento de arreglarlo.
2. Cargue los datos:
Conjunto de datos: datos de iris
Son datos famosos utilizados como el conjunto de datos «hola mundo» en el aprendizaje automático y las estadísticas por casi todo el mundo.
El conjunto de datos contiene 150 observaciones de flores de iris. Hay cuatro columnas de medidas de las flores en centímetros. La quinta columna es la especie de la flor observada. Todas las flores observadas pertenecen a una de tres especies.
2.1 Importar bibliotecas:
Primero, importemos todos los módulos, funciones y objetos que se utilizarán.
Python3
# Load libraries import pandas from pandas.plotting import scatter_matrix import matplotlib.pyplot as plt from sklearn import model_selection from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.naive_bayes import GaussianNB from sklearn.svm import SVC
Se requiere un entorno SciPy que funcione antes de continuar.
2.2 Cargar conjunto de datos
Los datos se pueden cargar directamente en el repositorio de aprendizaje automático de UCI.
Usar pandas para cargar los datos y explorar estadísticas descriptivas y visualización de datos.
Nota: Los nombres de cada columna se especifican al cargar los datos. Esto ayudará más adelante a la hora de explorar los datos.
Python3
url = "https://raw.githubusercontent.com / jbrownlee / Datasets / master / iris.csv" names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class'] dataset = pandas.read_csv(url, names = names)
Si tiene problemas de red, puede descargar el archivo iris.csv en su directorio de trabajo y cargarlo usando el mismo método, cambiando la URL al nombre del archivo local.
3. Resuma el conjunto de datos:
Ahora es el momento de echar un vistazo a los datos.
Pasos para ver los datos de diferentes maneras:
- Dimensiones del conjunto de datos.
- Eche un vistazo a los datos en sí.
- Resumen estadístico de todos los atributos.
- Desglose de los datos por la variable de clase.
3.1 Dimensiones del conjunto de datos
Python3
# shape print(dataset.shape)
(150, 5)
3.2 Eche un vistazo a los datos
Python3
# head print(dataset.head(20))
sepal-length sepal-width petal-length petal-width class 0 5.1 3.5 1.4 0.2 Iris-setosa 1 4.9 3.0 1.4 0.2 Iris-setosa 2 4.7 3.2 1.3 0.2 Iris-setosa 3 4.6 3.1 1.5 0.2 Iris-setosa 4 5.0 3.6 1.4 0.2 Iris-setosa 5 5.4 3.9 1.7 0.4 Iris-setosa 6 4.6 3.4 1.4 0.3 Iris-setosa 7 5.0 3.4 1.5 0.2 Iris-setosa 8 4.4 2.9 1.4 0.2 Iris-setosa 9 4.9 3.1 1.5 0.1 Iris-setosa 10 5.4 3.7 1.5 0.2 Iris-setosa 11 4.8 3.4 1.6 0.2 Iris-setosa 12 4.8 3.0 1.4 0.1 Iris-setosa 13 4.3 3.0 1.1 0.1 Iris-setosa 14 5.8 4.0 1.2 0.2 Iris-setosa 15 5.7 4.4 1.5 0.4 Iris-setosa 16 5.4 3.9 1.3 0.4 Iris-setosa 17 5.1 3.5 1.4 0.3 Iris-setosa 18 5.7 3.8 1.7 0.3 Iris-setosa 19 5.1 3.8 1.5 0.3 Iris-setosa
3.3 Resumen estadístico
Esto incluye el recuento, la media, los valores mínimo y máximo, así como algunos percentiles.
Python3
# descriptions print(dataset.describe())
Se ve claramente que todos los valores numéricos tienen la misma escala (centímetros) y rangos similares entre 0 y 8 centímetros.
sepal-length sepal-width petal-length petal-width count 150.000000 150.000000 150.000000 150.000000 mean 5.843333 3.054000 3.758667 1.198667 std 0.828066 0.433594 1.764420 0.763161 min 4.300000 2.000000 1.000000 0.100000 25% 5.100000 2.800000 1.600000 0.300000 50% 5.800000 3.000000 4.350000 1.300000 75% 6.400000 3.300000 5.100000 1.800000 max 7.900000 4.400000 6.900000 2.500000
3.4 Distribución de clases
Python3
# class distribution
print(dataset.groupby('class').size())
class Iris-setosa 50 Iris-versicolor 50 Iris-virginica 50
4. Visualización de datos
Usando dos tipos de parcelas:
- Gráficas univariadas para comprender mejor cada atributo.
- Gráficas multivariadas para comprender mejor las relaciones entre los atributos.
4.1 Gráficas univariadas
Gráficas univariadas: gráficas de cada variable individual.
Dado que las variables de entrada son numéricas, podemos crear diagramas de caja y bigotes de cada una.
Python3
# box and whisker plots dataset.plot(kind ='box', subplots = True, layout =(2, 2), sharex = False, sharey = False) plt.show()
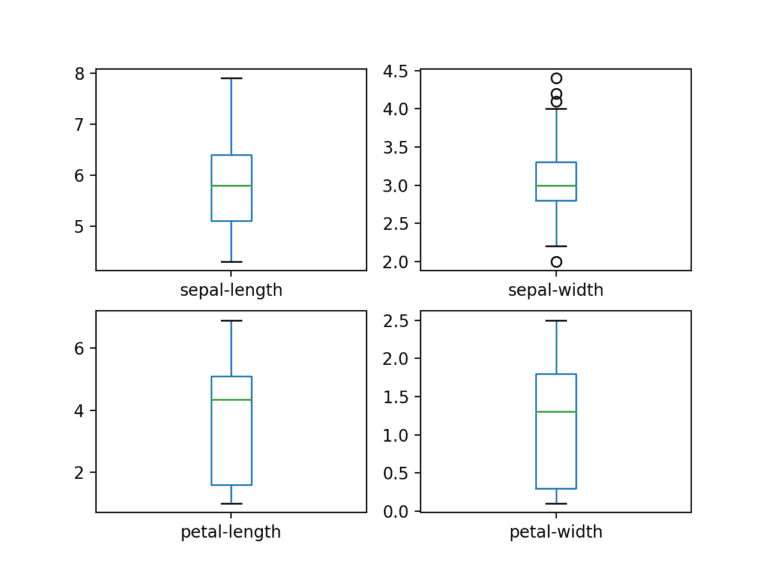
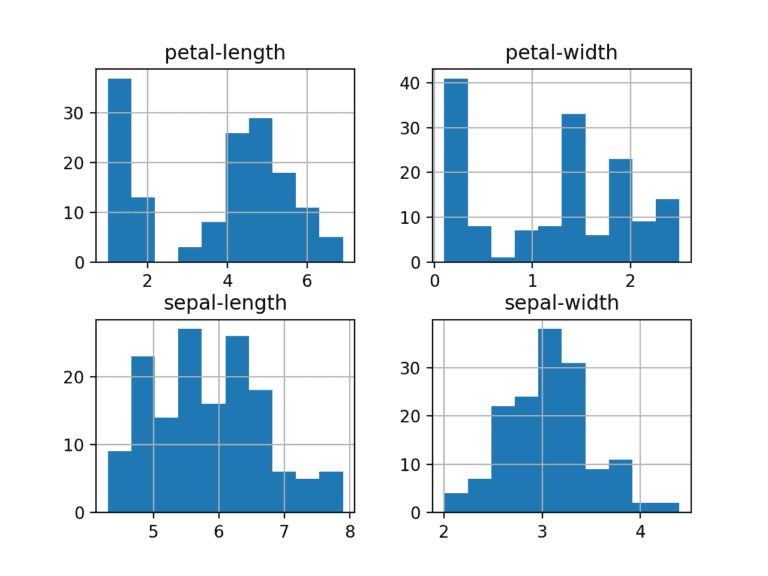
Crear un histograma de cada variable de entrada para tener una idea de la distribución.
Python3
# histograms dataset.hist() plt.show()
Parece que quizás dos de las variables de entrada tienen una distribución gaussiana. Es útil tener en cuenta que podemos usar algoritmos que pueden explotar esta suposición.
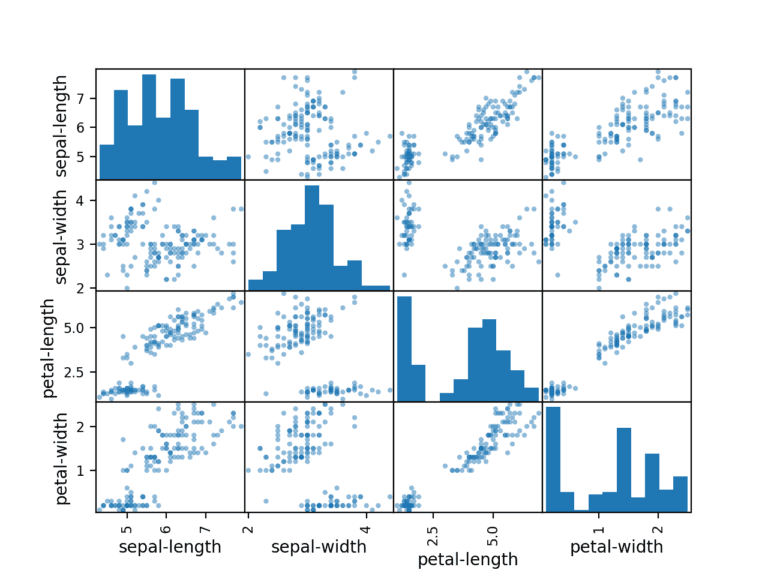
4.2 Gráficas multivariadas
Interacciones entre las variables.
Primero, veamos los diagramas de dispersión de todos los pares de atributos. Esto puede ser útil para detectar relaciones estructuradas entre variables de entrada.
Python3
# scatter plot matrix scatter_matrix(dataset) plt.show()
Tenga en cuenta la agrupación diagonal de algunos pares de atributos. Esto sugiere una alta correlación y una relación predecible.
5. Evaluar algunos algoritmos
Crear algunos modelos de los datos y estimar su precisión en datos no vistos.
- Separe un conjunto de datos de validación.
- Configure el arnés de prueba para usar una validación cruzada de 10 veces.
- Construya 5 modelos diferentes para predecir especies a partir de medidas de flores
- Seleccione el mejor modelo.
5.1 Crear un conjunto de datos de validación
Usar métodos estadísticos para estimar la precisión de los modelos que creamos en datos no vistos. Se toma una estimación concreta de la precisión del mejor modelo en datos no vistos evaluándolo en datos no vistos reales.
Algunos datos se usan como datos de prueba que los algoritmos no podrán ver y estos datos se usan para obtener una segunda idea independiente de qué tan preciso podría ser realmente el mejor modelo.
Los datos de prueba se dividen en dos, el 80 % de los cuales usaremos para entrenar nuestros modelos y el 20 % que retendremos como conjunto de datos de validación.
Python3
# Split-out validation dataset array = dataset.values X = array[:, 0:4] Y = array[:, 4] validation_size = 0.20 seed = 7 X_train, X_validation, Y_train, Y_validation = model_selection.train_test_split( X, Y, test_size = validation_size, random_state = seed)
X_train e Y_train son los datos de entrenamiento para preparar modelos y los conjuntos X_validation e Y_validation se pueden usar más adelante.
5.2 Arnés de prueba
Uso de validación cruzada de 10 veces para estimar la precisión. Esto dividirá nuestro conjunto de datos en 10 partes, entrenará en 9 y probará en 1 y repetirá para todas las combinaciones de divisiones de prueba de entrenamiento.
Python3
# Test options and evaluation metric seed = 7 scoring = 'accuracy'
La métrica de «precisión» se utiliza para evaluar los modelos. Es la proporción del número de instancias pronosticadas correctamente dividido por el número total de instancias en el conjunto de datos multiplicado por 100 para dar un porcentaje (por ejemplo, 95 % de precisión).
5.3 Construir modelos
No se sabe qué algoritmos serían buenos para este problema o qué configuraciones usar. Entonces, se toma una idea de las gráficas de que algunas de las clases son parcialmente separables linealmente en algunas dimensiones.
Evaluación de 6 algoritmos diferentes:
- Regresión Logística (LR)
- Análisis Discriminante Lineal (LDA)
- K-vecinos más cercanos (KNN).
- Árboles de Clasificación y Regresión (CART).
- Gaussian Naive Bayes (NB).
- Máquinas de vectores de soporte (SVM).
Los algoritmos elegidos son una mezcla de algoritmos lineales (LR y LDA) y no lineales (KNN, CART, NB y SVM). Las semillas de números aleatorios se restablecen antes de cada ejecución para garantizar que la evaluación de cada algoritmo se realice utilizando exactamente las mismas divisiones de datos. Garantiza que los resultados sean directamente comparables.
Construcción y evaluación de los modelos:
Python3
# Spot Check Algorithms
models = []
models.append(('LR', LogisticRegression(solver ='liblinear', multi_class ='ovr')))
models.append(('LDA', LinearDiscriminantAnalysis()))
models.append(('KNN', KNeighborsClassifier()))
models.append(('CART', DecisionTreeClassifier()))
models.append(('NB', GaussianNB()))
models.append(('SVM', SVC(gamma ='auto')))
# evaluate each model in turn
results = []
names = []
for name, model in models:
kfold = model_selection.KFold(n_splits = 10, random_state = seed)
cv_results = model_selection.cross_val_score(
model, X_train, Y_train, cv = kfold, scoring = scoring)
results.append(cv_results)
names.append(name)
msg = "% s: % f (% f)" % (name, cv_results.mean(), cv_results.std())
print(msg)
5.4 Seleccione el mejor modelo
Comparar los modelos entre sí y seleccionar el más preciso. Ejecutando el ejemplo anterior para obtener los siguientes resultados sin procesar:
LR: 0.966667 (0.040825) LDA: 0.975000 (0.038188) KNN: 0.983333 (0.033333) CART: 0.975000 (0.038188) NB: 0.975000 (0.053359) SVM: 0.991667 (0.025000)
Support Vector Machines (SVM) tiene la mayor puntuación de precisión estimada.
Se crea la gráfica de los resultados de la evaluación del modelo y se compara la dispersión y la precisión media de cada modelo. Hay una población de medidas de precisión para cada algoritmo porque cada algoritmo se evaluó 10 veces (validación cruzada de 10 veces).
Python3
# Compare Algorithms
fig = plt.figure()
fig.suptitle('Algorithm Comparison')
ax = fig.add_subplot(111)
plt.boxplot(results)
ax.set_xticklabels(names)
plt.show()
Los diagramas de caja y bigotes se aplastan en la parte superior del rango, y muchas muestras logran una precisión del 100%.
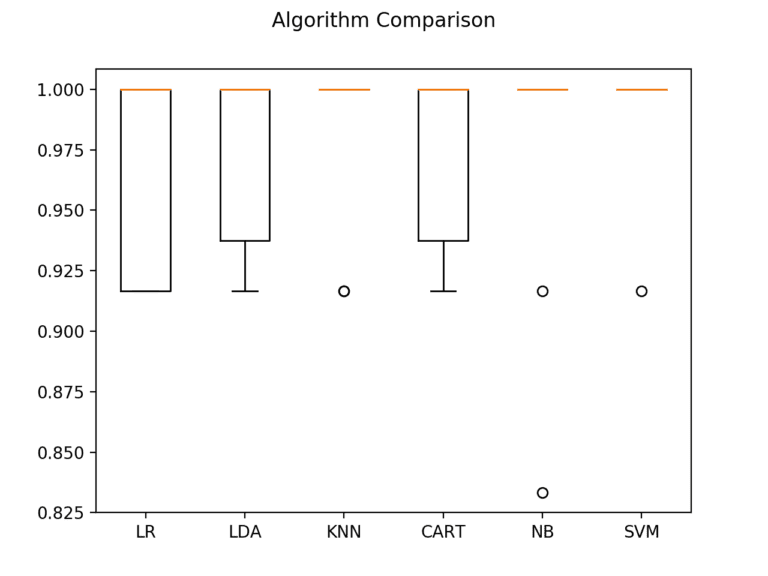
6. Haz predicciones
El algoritmo KNN es muy simple y fue un modelo preciso basado en nuestras pruebas.
Ejecutar el modelo KNN directamente en el conjunto de validación y resumir los resultados como una puntuación de precisión final, una array de confusión y un informe de clasificación.
Python3
# Make predictions on validation dataset knn = KNeighborsClassifier() knn.fit(X_train, Y_train) predictions = knn.predict(X_validation) print(accuracy_score(Y_validation, predictions)) print(confusion_matrix(Y_validation, predictions)) print(classification_report(Y_validation, predictions))
La precisión es 0,9 o 90%. La array de confusión proporciona una indicación de los tres errores cometidos. Finalmente, el informe de clasificación proporciona un desglose de cada clase por precisión, recuperación, puntaje f1 y soporte que muestra excelentes resultados (dado que el conjunto de datos de validación era pequeño).
0.9
[[ 7 0 0]
[ 0 11 1]
[ 0 2 9]]
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 7
Iris-versicolor 0.85 0.92 0.88 12
Iris-virginica 0.90 0.82 0.86 11
micro avg 0.90 0.90 0.90 30
macro avg 0.92 0.91 0.91 30
weighted avg 0.90 0.90 0.90 30
Publicación traducida automáticamente
Artículo escrito por RituRajSingh7 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA