R-CNN y YOLO más rápidos son buenos para detectar objetos en la imagen de entrada. También tienen un tiempo de detección muy bajo y se pueden utilizar en sistemas en tiempo real. Sin embargo, hay un desafío que no se puede abordar con la detección de objetos, el cuadro delimitador generado por YOLO y Faster R-CNN no brinda ninguna indicación sobre la forma del objeto.
Segmentación de instancias:
esta segmentación identifica cada instancia (ocurrencia de cada objeto presente en la imagen y los colorea con píxeles diferentes). Básicamente funciona para clasificar la ubicación de cada píxel y generar la máscara de segmentación para cada uno de los objetos de la imagen. Este enfoque da más idea sobre los objetos en la imagen porque preserva la seguridad de esos objetos mientras los reconoce.![]()

Segmentación de instancias (Fuente: Enlace )
Arquitectura Mask R-CNN: Mask R-CNN fue propuesta por Kaiming He et al. en 2017. Es muy similar a Faster R-CNN excepto que hay otra capa para predecir segmentada. La etapa de generación de propuesta de región es la misma tanto en la arquitectura como en la segunda etapa, que funciona en clase de predicción paralela, genera un cuadro delimitador y genera una máscara binaria para cada RoI.

Se compone de –
- Red troncal
- Región Propuesta Red
- Representación de máscara
- Alineación de retorno de la inversión
Red troncal:
Los autores de Mask R-CNN experimentaron con dos tipos de red troncal. La primera es la arquitectura ResNet estándar (ResNet-C4) y la otra es ResNet con red piramidal de funciones. La arquitectura estándar de ResNet era similar a la de Faster R-CNN pero ResNet-FPN ha propuesto algunas modificaciones. Esto consiste en una generación de RoI multicapa. Esta red piramidal de características de múltiples capas genera un retorno de la inversión de diferente escala, lo que mejora la precisión de la arquitectura ResNet anterior. 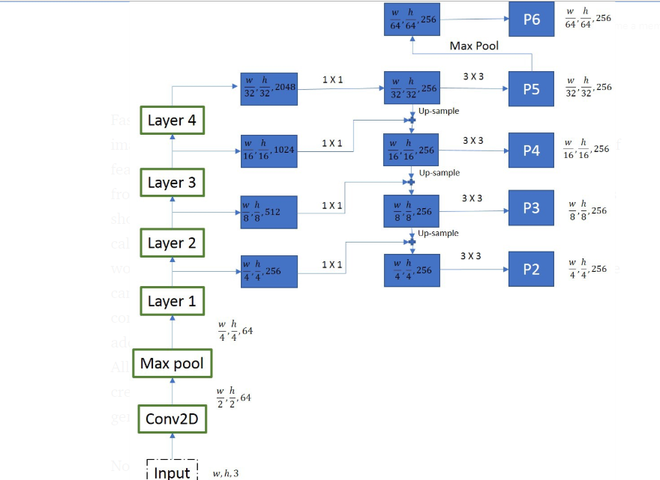
En cada capa, el tamaño de los mapas de características se reduce a la mitad y el número de mapas de características se duplica. Tomamos salida de cuatro capas (capa – 1, 2, 3 y 4) . Para generar mapas de características finales, utilizamos un enfoque llamado vía de arriba hacia abajo. Comenzamos desde el mapa de características superior (w/32, h/32, 256)y nos abrimos camino hacia los más grandes, mediante operaciones de alto nivel. Antes del muestreo ascendente también aplicamos la convolución 1*1 para reducir el número de canales a 256 . Luego, esto se agrega por elementos a la salida muestreada de la iteración anterior. Todas las salidas están sujetas a una capa de convolución de 3 X 3 para crear los 4 mapas de características finales (P2, P3, P4, P5) . El quinto mapa de características (P6) se genera a partir de una operación de agrupación máxima de P5 .
Red de propuesta de región:
todo el mapa de características de convolución generado por la capa anterior se pasa a través de una capa de convolución de 3*3 . La salida de esto luego pasó a dos ramas paralelas que determinan el puntaje de objetividad y retroceden las coordenadas del cuadro delimitador.

Aquí, solo usamos un paso de anclaje y 3 proporciones de anclaje para una pirámide de características (porque ya tenemos mapas de características de diferentes tamaños para buscar objetos de diferentes tamaños).
Representación de máscara:
una máscara contiene información espacial sobre el objeto. Por lo tanto, a diferencia de las capas de regresión de clasificación y cuadro delimitador, no pudimos colapsar la salida a una capa completamente conectada para mejorar, ya que requiere una correspondencia de píxel a píxel de la capa anterior. Mask R-CNN utiliza una red totalmente conectada para predecir la máscara. Esta ConvNet toma un RoI como entrada y genera la representación de la máscara m*m . También ampliamos esta máscara para la inferencia en la imagen de entrada y reducimos los canales a 256 usando 1*1circunvolución. Para generar entradas para esta red totalmente conectada que predice la máscara, usamos RoIAlign. El propósito de RoIAlign es convertir mapas de características de diferentes tamaños generados por la red propuesta de región en un mapa de características de tamaño fijo. El artículo de Mask R-CNN sugirió dos variantes de arquitectura. En una variante, la entrada de CNN de generación de máscara se pasa después de aplicar RoIAlign (ResNet C4), pero en otra variante, la entrada se pasa justo antes de la capa totalmente conectada (Red FPN).

(Fuente: Enlace )
Esta rama de generación de máscaras es una red de convolución completa y genera un K * (m*m) , donde K es el número de clases (una para cada clase) y m=14 para ResNet-C4 y 28 para ResNet_FPN .
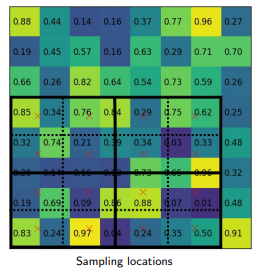
RoI Align:
RoI align tiene el mismo motivo que RoI pool, para generar las regiones de interés de tamaño fijo a partir de propuestas de región. Funciona en los siguientes pasos: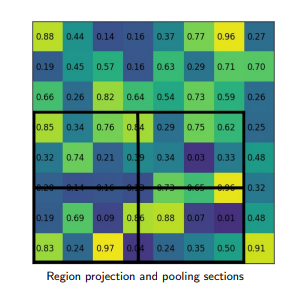
Dado el mapa de características de la capa de Convolución anterior de tamaño h*w , divida este mapa de características en M * N cuadrículas de igual tamaño (NO solo tomaremos un valor entero).
La velocidad de inferencia de la máscara R-CNN es de alrededor de 2 fps , lo cual es bueno teniendo en cuenta la adición de la rama de segmentación en la arquitectura.
Aplicaciones:
debido a su capacidad adicional para generar máscaras segmentadas, se utiliza en muchas aplicaciones de visión por computadora, tales como:
- Estimación de la pose humana
- Coche autónomo
- Mapeo de imágenes de drones, etc.
Referencia: