Clase SplitRule: divide un fragmento según el patrón de división especificado para el propósito. Se especifica como <NN.*>}{<.*>, es decir, dos llaves opuestas rodeadas por un patrón a cada lado.
Clase MergeRule: fusiona dos fragmentos en función del final del primer fragmento y el comienzo del segundo fragmento. Se especifica como <NN.*>{}<.*>, es decir, llaves enfrentadas.
Ejemplo de cómo se realizan los pasos
- Comenzando con el árbol de oraciones .

- Fragmentación de oraciones completas .
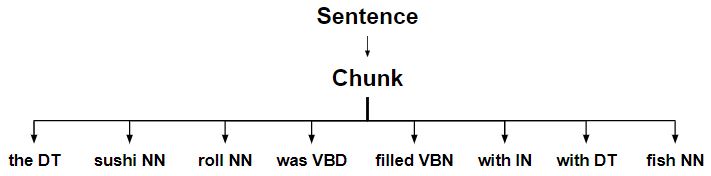
- Los trozos se dividen en varios trozos .
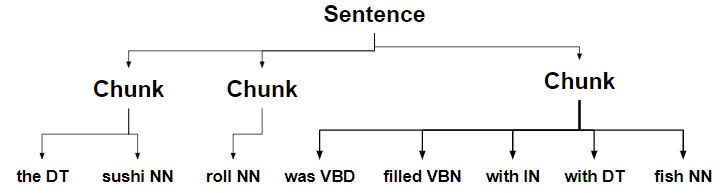
- El fragmento con un determinante se divide en fragmentos separados.
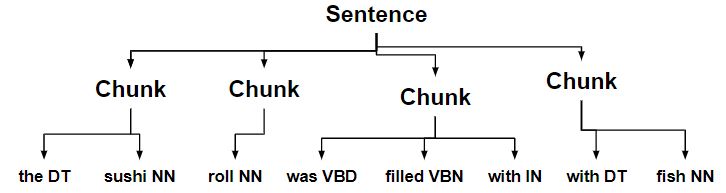
- Los fragmentos que terminan con un sustantivo se fusionan con el siguiente fragmento.
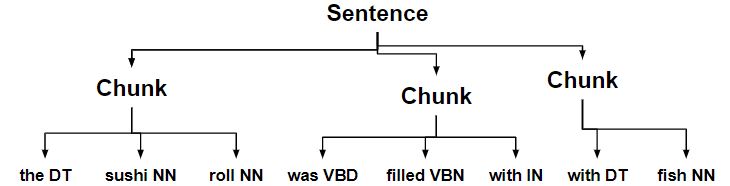
Código n. ° 1: construcción del árbol
from nltk.chunk import RegexpParser
chunker = RegexpParser(r'''
NP:
{<DT><.*>*<NN.*>}
<NN.*>}{<.*>
<.*>}{<DT>
<NN.*>{}<NN.*>
''')
sent = [('the', 'DT'), ('sushi', 'NN'), ('roll', 'NN'), ('was', 'VBD'),
('filled', 'VBN'), ('with', 'IN'), ('the', 'DT'), ('fish', 'NN')]
chunker.parse(sent)
Producción:
Tree('S', [Tree('NP', [('the', 'DT'), ('sushi', 'NN'), ('roll', 'NN')]),
Tree('NP', [('was', 'VBD'), ('filled', 'VBN'), ('with', 'IN')]),
Tree('NP', [('the', 'DT'), ('fish', 'NN')])])
Código n.º 2: dividir y fusionar
# Loading Libraries
from nltk.chunk.regexp import ChunkString, ChunkRule, ChinkRule
from nltk.tree import Tree
from nltk.chunk.regexp import MergeRule, SplitRule
# Chunk String
chunk_string = ChunkString(Tree('S', sent))
print ("Chunk String : ", chunk_string)
# Applying Chunk Rule
ur = ChunkRule('<DT><.*>*<NN.*>', 'chunk determiner to noun')
ur.apply(chunk_string)
print ("\nApplied ChunkRule : ", chunk_string)
# Splitting
sr1 = SplitRule('<NN.*>', '<.*>', 'split after noun')
sr1.apply(chunk_string)
print ("\nSplitting Chunk String : ", chunk_string)
sr2 = SplitRule('<.*>', '<DT>', 'split before determiner')
sr2.apply(chunk_string)
print ("\nFurther Splitting Chunk String : ", chunk_string)
# Merging
mr = MergeRule('<NN.*>', '<NN.*>', 'merge nouns')
mr.apply(chunk_string)
print ("\nMerging Chunk String : ", chunk_string)
# Back to Tree
chunk_string.to_chunkstruct()
Producción:
Chunk String : <DT> <NN> <NN> <VBD> <VBN> <IN> <DT> <NN>
Applied ChunkRule : {<DT> <NN> <NN> <VBD> <VBN> <IN> <DT> <NN>}
Splitting Chunk String : {<DT> <NN>}{<NN>}{<VBD> <VBN> <IN> <DT> <NN>}
Further Splitting Chunk String : {<DT> <NN>}{<NN>}{<VBD> <VBN> <IN>}{<DT> <NN>}
Merging Chunk String : {<DT> <NN> <NN>}{<VBD> <VBN> <IN>}{<DT> <NN>}
Tree('S', [Tree('CHUNK', [('the', 'DT'), ('sushi', 'NN'), ('roll', 'NN')]),
Tree('CHUNK', [('was', 'VBD'), ('filled', 'VBN'), ('with', 'IN')]),
Tree('CHUNK', [('the', 'DT'), ('fish', 'NN')])])
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA