Google introdujo por primera vez Seq2seq para la traducción automática. Antes de eso, la traducción funcionaba de una manera muy ingenua. Cada palabra que usó para escribir se convirtió a su idioma de destino sin tener en cuenta su gramática y estructura de oración. Seq2seq revolucionó el proceso de traducción al hacer uso del aprendizaje profundo. No solo tiene en cuenta la palabra/entrada actual durante la traducción, sino también su vecindario.
Hoy en día, se utiliza para una variedad de aplicaciones diferentes, como subtítulos de imágenes, modelos conversacionales, resúmenes de texto, etc.
Funcionamiento de Seq2seq:
como sugiere el nombre, seq2seq toma como entrada una secuencia de palabras (oración u oraciones) y genera una secuencia de palabras de salida. Lo hace mediante el uso de la red neuronal recurrente (RNN). Aunque la versión estándar de RNN rara vez se usa, se usa su versión más avanzada, es decir, LSTM o GRU. Esto se debe a que RNN sufre el problema del gradiente de fuga. LSTM se utiliza en la versión propuesta por Google. Desarrolla el contexto de la palabra tomando 2 entradas en cada momento. Uno del usuario y el otro de su salida anterior, de ahí el nombre recurrente (salida va como entrada).
Principalmente tiene dos componentes, es decir, codificador y decodificador , y por lo tanto, a veces se le llama Red de Codificador-Decodificador .
Codificador: utiliza capas de redes neuronales profundas y convierte las palabras de entrada en los vectores ocultos correspondientes. Cada vector representa la palabra actual y el contexto de la palabra.
Decodificador: Es similar al codificador. Toma como entrada el vector oculto generado por el codificador, sus propios estados ocultos y la palabra actual para producir el siguiente vector oculto y finalmente predecir la siguiente palabra.
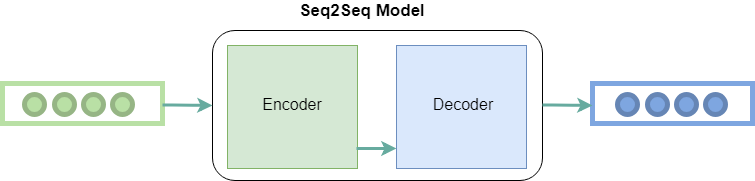
Además de estos dos, muchas optimizaciones deben conducir a otros componentes de seq2seq:
- Atención: La entrada al decodificador es un solo vector que tiene que almacenar toda la información sobre el contexto. Esto se convierte en un problema con secuencias grandes. Por lo tanto, se aplica el mecanismo de atención que permite que el decodificador mire selectivamente la secuencia de entrada.
- Búsqueda de haz: el decodificador selecciona la palabra de mayor probabilidad como salida. Pero esto no siempre produce los mejores resultados, debido al problema básico de los algoritmos codiciosos. Por lo tanto, se aplica la búsqueda de haz que sugiere posibles traducciones en cada paso. Esto se hace creando un árbol de los mejores k-resultados.
- Agrupación: las secuencias de longitud variable son posibles en un modelo seq2seq debido al relleno de 0 que se realiza tanto en la entrada como en la salida. Sin embargo, si la longitud máxima establecida por nosotros es 100 y la oración tiene solo 3 palabras, causa un gran desperdicio de espacio. Así que usamos el concepto de cubetas. Hacemos cubos de diferentes tamaños como (4, 8) (8, 15), y así sucesivamente, donde 4 es la longitud máxima de entrada definida por nosotros y 8 es la longitud máxima de salida definida.
Publicación traducida automáticamente
Artículo escrito por mani.wadhwa y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA