Siempre que pensamos en Machine Learning, lo primero que nos viene a la mente es un conjunto de datos. Si bien hay muchos conjuntos de datos que puede encontrar en sitios web como Kaggle, a veces es útil extraer datos por su cuenta y generar su propio conjunto de datos. Generar su propio conjunto de datos le brinda más control sobre los datos y le permite entrenar su modelo de aprendizaje automático.
En este artículo, generaremos conjuntos de datos aleatorios utilizando la biblioteca Numpy en Python.
Bibliotecas necesarias:
-> Numpy: pip3 install numpy -> Pandas: pip3 install pandas -> Matplotlib: pip3 install matplotlib
Distribución normal:
En la teoría de la probabilidad, la distribución normal o gaussiana es una distribución de probabilidad continua muy común que es simétrica con respecto a la media, lo que muestra que los datos cercanos a la media son más frecuentes que los datos alejados de la media. Las distribuciones normales se usan en estadísticas y se usan a menudo para representar variables aleatorias de valor real.
La distribución normal es el tipo de distribución más común en los análisis estadísticos. La distribución normal estándar tiene dos parámetros: la media y la desviación estándar. La media es la tendencia central de la distribución. La desviación estándar es una medida de la variabilidad. Define el ancho de la distribución normal. La desviación estándar determina qué tan lejos de la media tienden a caer los valores. Representa la distancia típica entre las observaciones y el promedio. se ajusta a muchos fenómenos naturales, por ejemplo, las alturas, la presión arterial, el error de medición y las puntuaciones de coeficiente intelectual siguen la distribución normal.
Gráfico de la distribución normal:
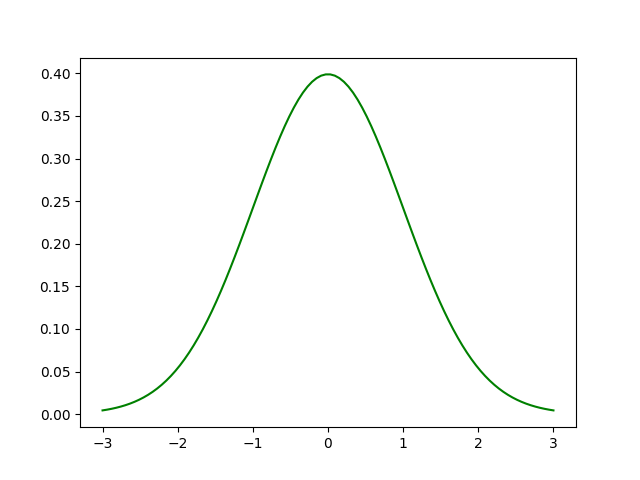
Ejemplo:
PYTHON3
# importing libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt # initialize the parameters for the normal # distribution, namely mean and std. # deviation # defining the mean mu = 0.5 # defining the standard deviation sigma = 0.1 # The random module uses the seed value as a base # to generate a random number. If seed value is not # present, it takes the system’s current time. np.random.seed(0) # define the x co-ordinates X = np.random.normal(mu, sigma, (395, 1)) # define the y co-ordinates Y = np.random.normal(mu * 2, sigma * 3, (395, 1)) # plot a graph plt.scatter(X, Y, color = 'g') plt.show()
Producción :
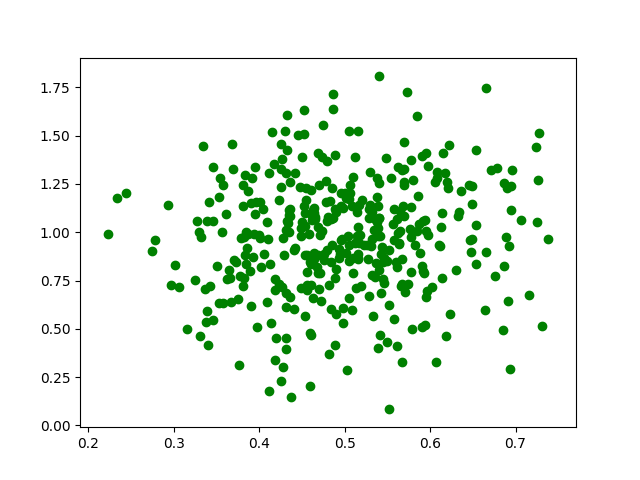
Veamos un mejor ejemplo.
Generaremos un conjunto de datos con 4 columnas. Cada columna en el conjunto de datos representa una característica. La quinta columna del conjunto de datos es la etiqueta de salida. Varía entre 0-3. Este conjunto de datos se puede utilizar para entrenar un clasificador, como un clasificador de regresión logística, un clasificador de red neuronal, máquinas de vectores de soporte, etc.
PYTHON3
# importing libraries
import numpy as np
import pandas as pd
import math
import random
import matplotlib.pyplot as plt
# defining the columns using normal distribution
# column 1
point1 = abs(np.random.normal(1, 12, 100))
# column 2
point2 = abs(np.random.normal(2, 8, 100))
# column 3
point3 = abs(np.random.normal(3, 2, 100))
# column 4
point4 = abs(np.random.normal(10, 15, 100))
# x contains the features of our dataset
# the points are concatenated horizontally
# using numpy to form a feature vector.
x = np.c_[point1, point2, point3, point4]
# the output labels vary from 0-3
y = [int(np.random.randint(0, 4)) for i in range(100)]
# defining a pandas data frame to save
# the data for later use
data = pd.DataFrame()
# defining the columns of the dataset
data['col1'] = point1
data['col2'] = point2
data['col3'] = point3
data['col4'] = point4
# plotting the various features (x)
# against the labels (y).
plt.subplot(2, 2, 1)
plt.title('col1')
plt.scatter(y, point1, color ='r', label ='col1')
plt.subplot(2, 2, 2)
plt.title('Col2')
plt.scatter(y, point2, color = 'g', label ='col2')
plt.subplot(2, 2, 3)
plt.title('Col3')
plt.scatter(y, point3, color ='b', label ='col3')
plt.subplot(2, 2, 4)
plt.title('Col4')
plt.scatter(y, point4, color ='y', label ='col4')
# saving the graph
plt.savefig('data_visualization.jpg')
# displaying the graph
plt.show()
Producción :
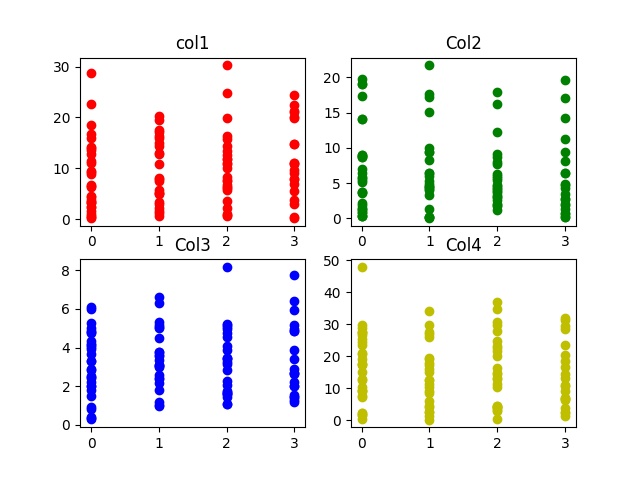
Publicación traducida automáticamente
Artículo escrito por Adith Bharadwaj y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA