Gradient Boosting es un algoritmo de impulso popular. En el aumento de gradiente, cada predictor corrige el error de su predecesor. A diferencia de Adaboost, los pesos de las instancias de entrenamiento no se modifican, sino que cada predictor se entrena utilizando los errores residuales del predecesor como etiquetas.
Existe una técnica llamada Gradient Boosted Trees cuyo alumno base es CART (Classification and Regression Trees).
El siguiente diagrama explica cómo se entrenan los árboles potenciados por gradiente para problemas de regresión.
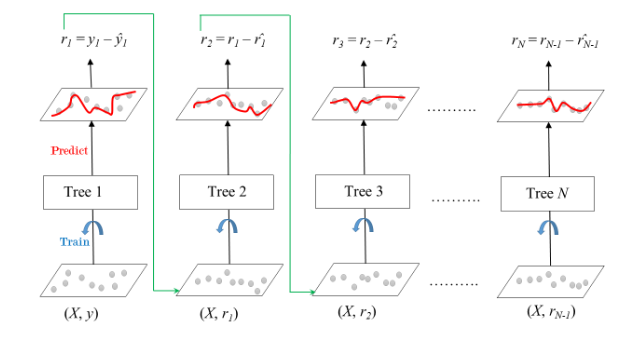
Árboles potenciados por gradiente para regresión
El conjunto consta de N árboles. Tree1 se entrena usando la array de características X y las etiquetas y . Las predicciones etiquetadas como y1(sombrero) se utilizan para determinar los errores residuales r1 del conjunto de entrenamiento . Tree2 luego se entrena usando la array de características X y los errores residuales r1 de Tree1 como etiquetas. Los resultados pronosticados r1(sombrero) se utilizan luego para determinar el residuo r2 . El proceso se repite hasta que se entrenan todos los N árboles que forman el conjunto.
Hay un parámetro importante usado en esta técnica conocido como Contracción .
Contracción
se refiere al hecho de que la predicción de cada árbol en el conjunto se reduce después de que se multiplica por la tasa de aprendizaje (eta) que oscila entre 0 y 1. Existe una compensación entre eta y el número de estimadores, lo que disminuye las necesidades de la tasa de aprendizaje. ser compensado con estimadores crecientes para alcanzar cierto rendimiento del modelo. Dado que todos los árboles están entrenados ahora, se pueden hacer predicciones.
Cada árbol predice una etiqueta y la predicción final viene dada por la fórmula,
y(pred) = y1 + (eta * r1) + (eta * r2) + ....... + (eta * rN)
La clase de la regresión de aumento de gradiente en scikit-learn es GradientBoostingRegressor . Se utiliza un algoritmo similar para la clasificación conocido como GradientBoostingClassifier .
Código: código de Python para Gradient Boosting Regressor
# Import models and utility functions
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE
from sklearn import datasets
# Setting SEED for reproducibility
SEED = 1
# Importing the dataset
bike = datasets.load_bike()
X, y = bike.data, bike.target
# Splitting dataset
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size = 0.3, random_state = SEED)
# Instantiate Gradient Boosting Regressor
gbr = GradientBoostingRegressor(n_estimators = 200, max_depth = 1, random_state = SEED)
# Fit to training set
gbr.fit(train_X, train_y)
# Predict on test set
pred_y = gbr.predict(test_X)
# test set RMSE
test_rmse = MSE(test_y, pred_y) ** (1 / 2)
# Print rmse
print('RMSE test set: {:.2f}'.format(test_rmse))
Producción:
RMSE test set: 4.01