Es muy raro que obtenga datos exactos en la forma en que desea. El preprocesamiento de datos es un primer paso crucial antes de construir e implementar su modelo de aprendizaje automático. Y mientras construye un modelo, no es el caso que siempre obtendrá datos limpios y formateados para trabajar. Es obligatorio limpiar y comprobar los datos antes de su uso. Por lo tanto, utilizamos el preprocesamiento de datos para estos. Veamos algunos pasos antes de construir el modelo que debemos realizar.
- Obtener conjunto de datos
- Importación de bibliotecas
- Importar conjunto de datos
- Encontrar valores perdidos
- Codificación de datos categóricos
- Dividir datos en el conjunto de entrenamiento y prueba
- Escalado de funciones
1. Obtener conjunto de datos
Lo primero que necesitamos es un conjunto de datos, ya que Machine Learning funciona completamente en un conjunto de datos. Los datos recopilados en un formato particular se conocen como DATASET. Es muy necesario comprender bien su conjunto de datos para trabajar. Porque el conjunto de datos puede estar en diferentes formatos para diferentes propósitos. Y necesita conocer bien el conjunto de datos para construir y analizar el modelo. Para usar el conjunto de datos en nuestro código, básicamente lo usamos en formato CSV o formato xlsx (Excel).
2. Importación de bibliotecas
Para realizar el preprocesamiento de datos con Python, necesitamos importar algunas de las bibliotecas de Python predefinidas. Para realizar alguna tarea en particular estas bibliotecas son muy útiles.
- Numpy : la biblioteca Numpy Python se utiliza para realizar cualquier tipo de cálculo científico y matemático en el código.
- Pandas : Pandas es la biblioteca de Python más famosa y útil que se utiliza para importar y administrar el conjunto de datos. Pandas son datos de código abierto que proporcionan una manipulación de datos de alto rendimiento en python.
- Matplotlib : Matplotlib es muy importante para poder visualizar nuestros resultados y tener una mejor vista de los datos. Y con esta biblioteca, necesitamos importar un subpaquete llamado Pyplot . Esta biblioteca se utiliza para trazar cualquier tipo de diagrama o gráfico.
Python
import numpy as np import pandas as pd import matplotlib.pyplot as plt

3. Importación de conjuntos de datos
Ahora es el momento de importar el conjunto de datos que hemos recopilado para el modelo de aprendizaje automático. Antes de importar un conjunto de datos, asegúrese de establecer el directorio actual como directorio de trabajo. Ahora, para importar el conjunto de datos, use read_csv() de la biblioteca de pandas, que se usa para leer un archivo CSV y realizar varias operaciones en él. Hay varias otras opciones disponibles para leer el archivo en diferentes formatos como read_excel() para leer archivos de Excel.
Python
data = pd.read_csv('dataset.csv')
El conjunto de datos es el nombre de la variable que almacena el conjunto de datos cargado como un conjunto de datos en formato CSV. Aquí hay un ejemplo con un conjunto de datos aleatorio conocido como el conjunto de datos del Titanic que puede descargar aquí .
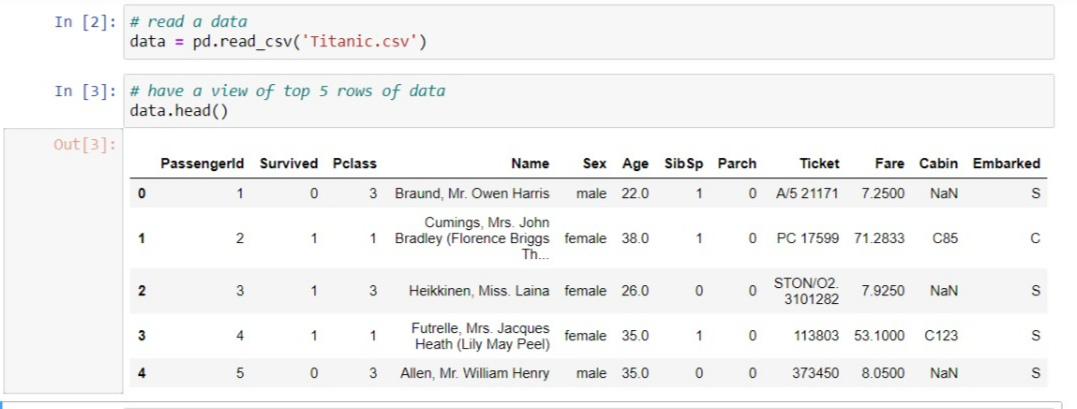
Extracción de variables dependientes e independientes: con un conjunto de datos filtrados explorado, debe crear una array de variables independientes y un vector de variables dependientes. Al principio, debe decidir y confirmar qué columnas o factores está usando como variables independientes (también conocidas como características) para entrenar su modelo que afecta sus variables objetivo. Por ejemplo, si la columna de destino es la última columna de su conjunto de datos, puede crear fácilmente una array de sus variables independientes como:
Python
x = data.iloc[:,:-1].values
Aquí, los primeros dos puntos (:) representan que queremos todas las líneas en nuestro conjunto de datos. :-1 significa que queremos tomar todas las columnas excepto la última. Y .values significa que queremos tomar todos los valores. Y si la variable de destino finalmente no es como en nuestro caso (Sobrevivió), entonces podemos descartarla y tomar todas las demás columnas en el conjunto de trenes. Ejemplo:
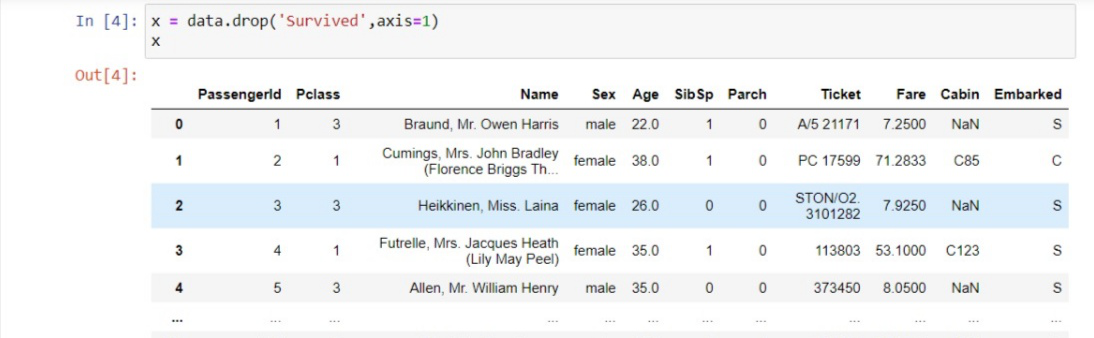
Y para tomar el vector de la variable dependiente, que es simplemente la última columna del conjunto de datos, puede escribir como:
Python
y = data.iloc[:,-1].values
O usa este método,
Python
y = data['Survived']
4. Tratar con valores faltantes
Los datos faltantes pueden crear grandes problemas en los resultados, por lo que es necesario eliminarlos del conjunto de datos. La falta de datos es el problema más común y un paso importante involucrado en la limpieza de datos. Los valores perdidos suelen tener la forma de NaN o NONE . La causa del valor faltante es: a veces, la mayoría de los campos en las columnas están vacíos, lo que debe completarse con los datos correctos y, a veces, hay datos incorrectos o mala calidad de los datos que afecta negativamente a los resultados. Hay varias formas de lidiar con los valores faltantes y completarlos:
- La primera forma de lidiar con valores NULL: simplemente puede eliminar las filas o columnas que tienen valores NULL. Pero la mayoría de las veces esto puede conducir a la pérdida de información, por lo que este método no es tan eficiente.
- Otro método importante es completar los datos en lugar de valores NULL. Puede calcular la media de una fila y una columna específicas y completarla en lugar de valores nulos. Es muy útil el método en el que las columnas tienen datos numéricos como edad, salario, peso, año, etc.
- También puede decidir completar los valores que faltan con cualquier valor que venga directamente después de él en la misma columna.
Las decisiones dependen del tipo de datos y de los resultados que desea obtener con los datos. Si los valores faltantes son menores, entonces es bueno eliminarlos y si falta más del 50% de los valores, entonces debe completarse con los datos correctos.
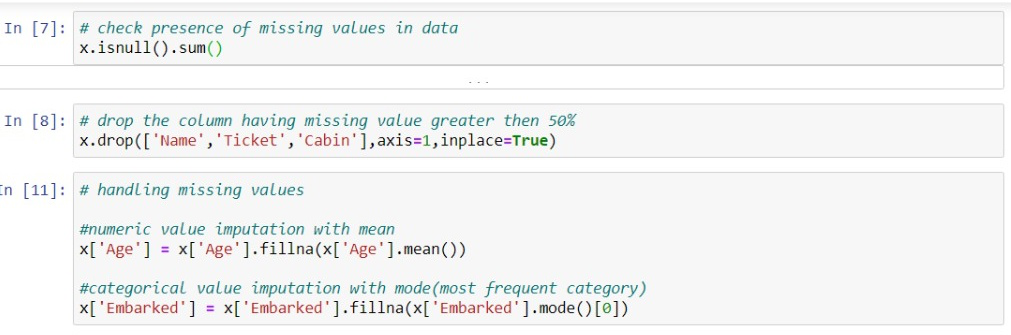
Aquí, la columna de la cabina contiene aproximadamente un 55 % de datos faltantes. El nombre y la columna del boleto no son tan eficientes para predecir la tasa de supervivencia de la persona, por lo tanto, elimine la columna que no es significativa en la predicción; de lo contrario, dañará la precisión de su modelo de aprendizaje automático.
5. Codificación de datos categóricos
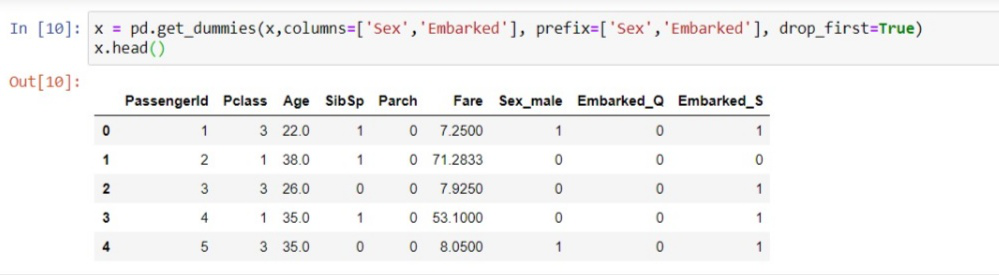
El aprendizaje automático funciona con matemáticas y números (tipo flotante o int). Sin embargo, a menudo sucede que hay algunas columnas en el conjunto de datos que tienen valores categóricos (tipo de string) y queremos usarlos para entrenar nuestro modelo. En ese caso, tenemos que convertir los valores de las categorías en tipos numéricos. Por ejemplo, hay una columna de sexo en un conjunto de datos que contiene valores Masculino y Femenino que deben convertirse a numéricos, luego podemos convertirla simplemente como si pudiéramos asignar 0 a Masculino y 1 a Femenino y entrenar nuestro modelo en él. Suele pasar con muchas columnas como el nombre del Estado, País, Color, etc. Para convertir valores en numéricos simplemente podemos usar SKLEARNbiblioteca de preprocesamiento que tiene el nombre de clase LabelEncoder() . Por ejemplo, tomamos la columna de estado y la convertimos en valores numéricos.
Python
# CATEGORICAL DATA from sklearn.preprocessing import LabelEncoder le_x = LabelEncoder() x['State'] = le_x.fit_transform(x['State'])
En el código anterior, hemos importado la clase LabelEncoder de la biblioteca de preprocesamiento de sklearn. La clase ha codificado con éxito las variables en dígitos. Si hay más dígitos codificados, como 0, 1, 2, el modelo de aprendizaje automático asumirá que existe alguna relación entre esto. Y por estos, los resultados previstos por el modelo serán incorrectos y el rendimiento se reducirá. Entonces, para evitar este problema, usaremos variables ficticias.
Variables ficticias: las variables ficticias son las variables que tienen valor solo 0 y 1. En nuestro conjunto de datos, si tenemos 3 valores como 0, 1 y 2, lo convertirá en 0 y 1. Para esto, usaremos OneHotEncoder ( ) clase de biblioteca de preprocesamiento. se usa cuando las categorías son menores en una columna, como una columna de género que tiene valores como masculino y femenino, entonces se puede codificar como 0,1.
Python
from sklearn.preprocessing import OneHotEncoder onehot_encoder = OneHotEncoder(categorical_features = ['State']) x = onehot_encoder.fit_transform(x).toarray() # or x = pd.get_dummies(x['gender'])
6. Dividir el conjunto de datos en un conjunto de entrenamiento y prueba
El paso crucial del preprocesamiento de datos para dividir el conjunto de datos en conjuntos de entrenamiento y prueba. Al hacer este paso, podemos mejorar el rendimiento y la precisión de nuestro modelo de una manera mejor y más eficiente. Si entrenamos el modelo en los diferentes conjuntos de datos y lo probamos con un conjunto de datos completamente diferente del entrenamiento, creará dificultades para que el modelo estime la creación entre variables independientes y dependientes y la precisión del modelo será muy inferior. Por lo tanto, siempre tratamos de crear un modelo de aprendizaje automático que funcione bien con el conjunto de entrenamiento y con el conjunto de prueba.
- Conjunto de entrenamiento: subconjunto del conjunto de datos para entrenar el modelo, los resultados también los conocemos para el modelo.
- Conjunto de prueba: subconjunto del conjunto de datos para probar el modelo, cuyo modelo predice la salida en función del entrenamiento dado al modelo.
Para esto, usamos la clase train_test_split de la biblioteca model_selection de sklearn .
Python
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, random_state = 0)
- x_train: variables independientes (características) para el conjunto de entrenamiento
- y_train: funciones para probar datos
- x_test: datos de entrenamiento de variables dependientes
- y_test: datos de prueba de variables independientes
En train_test_split() pasamos 4 parámetros en los que dos son arrays y el tercero es test_size que define el tamaño de los datos de prueba. Aquí hemos tomado el 20 % de los datos como prueba, por lo que se da como 0,2 y el 80 % restante se entregará al conjunto de entrenamiento. El último parámetro random_state se usa para establecer una semilla para un generador aleatorio para que siempre obtengas el mismo resultado.
7. Escalado de características
El paso final del modelo de aprendizaje automático es el escalado de características. Es un método para estandarizar el conjunto de datos de entrenamiento en un rango específico. En el escalado de características, todos los valores se mantienen en el mismo rango y en la misma escala para que ninguna variable domine a la otra variable. Por ejemplo, tenemos la edad y el salario en el conjunto de datos de capacitación, entonces no están en la misma escala que la edad es 31 y el salario es 48000. Como el modelo de aprendizaje automático se basa en la distancia euclidiana y si no escalamos la variable, causará una problema en los resultados y el rendimiento.
DISTANCIA EUCLIDEA ENTRE A Y B = ∑[(x 2 – x 1 )² + (y 2 – y 1 )²]
Para el escalado de características, usamos la clase StandardScaler del preprocesamientobiblioteca.
Python
from sklearn.preprocessing import StandardScaler
Ahora, crearemos un objeto de la clase StandardScaler para variables independientes. Y luego ajustaremos y transformaremos el conjunto de datos de entrenamiento. Para el conjunto de datos de prueba, aplicaremos directamente la función de transformación porque ya se ha hecho en el conjunto de datos de entrenamiento.
Python
std_x = StandardScaler() x_train = std_x.fit_transform(x_train) x_test = std_x.transform(x_test)
Como resultado, las variables se escalan entre -1 y 1. Después de realizar estos pasos, ajuste el modelo, prediga e implemente, y luego pruebe la precisión del modelo. Dará resultados exactos y la precisión del modelo siempre estará por encima del 90 por ciento.
Combinando todos los pasos anteriores
Ahora, al final, combinaremos todos los pasos para que el código sea más legible y comprensible.
Python
# Importing libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# import dataset
data = pd.read_csv('datasets/Titanic.csv')
# extract dependent and independent features
x = data.drop('Survived', axis = 1)
y = data['Survived']
# Missing value Imputation
# drop the unrelaven features
x.drop(['Name', 'Ticket', 'Cabin'],
axis = 1, inplace = True)
# numeric value imputation with mean
x['Age'] = x['Age'].fillna(x['Age'].mean())
# categorical value imputation with mode(most frequent category)
x['Embarked'] = x['Embarked'].fillna(x['Embarked'].mode()[0])
# category encoding
x = pd.get_dummies(x, columns = ['Sex', 'Embarked'],
prefix = ['Sex', 'Embarked'],
drop_first = True)
# train-test split
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y,
test_size = 0.2,
random_state = 0)
# feature scaling
from sklearn.preprocessing import StandardScaler
std_x = StandardScaler()
x_train = std_x.fit_transform(x_train)
x_test = std_x.transform(x_test)
En el código anterior, hemos cubierto los pasos necesarios para preparar sus datos o para el preprocesamiento de datos. Pero hay algunas áreas y conjuntos de datos en los que todos los pasos son necesarios y, en esos casos, podemos excluirlos de nuestro código.
Publicación traducida automáticamente
Artículo escrito por raghavagrawal1777 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA