Requisitos previos: creación de un codificador automático
Este artículo demostrará cómo usar un codificador automático para clasificar datos. Los datos que se utilizan a continuación son los datos de las transacciones con tarjeta de crédito para predecir si una determinada transacción es fraudulenta o no. Los datos se pueden descargar desde aquí .
Paso 1: cargando las bibliotecas requeridas
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.linear_model import LogisticRegression from sklearn.svm import SVC from sklearn.metrics import accuracy_score from sklearn.preprocessing import MinMaxScaler from sklearn.manifold import TSNE import matplotlib.pyplot as plt import seaborn as sns from keras.layers import Input, Dense from keras.models import Model, Sequential from keras import regularizers
Paso 2: Cargando los datos
# Changing the working location to the location of the data
cd C:\Users\Dev\Desktop\Kaggle\Credit Card Fraud
# Loading the dataset
df = pd.read_csv('creditcard.csv')
# Making the Time values appropriate for future work
df['Time'] = df['Time'].apply(lambda x : (x / 3600) % 24)
# Separating the normal and fraudulent transactions
fraud = df[df['Class']== 1]
normal = df[df['Class']== 0].sample(2500)
# Reducing the dataset because of machinery constraints
df = normal.append(fraud).reset_index(drop = True)
# Separating the dependent and independent variables
y = df['Class']
X = df.drop('Class', axis = 1)
Paso 3: Exploración de los datos
a)
df.head()

b)
df.info()
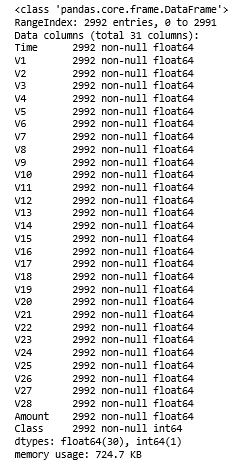
C)
df.describe()
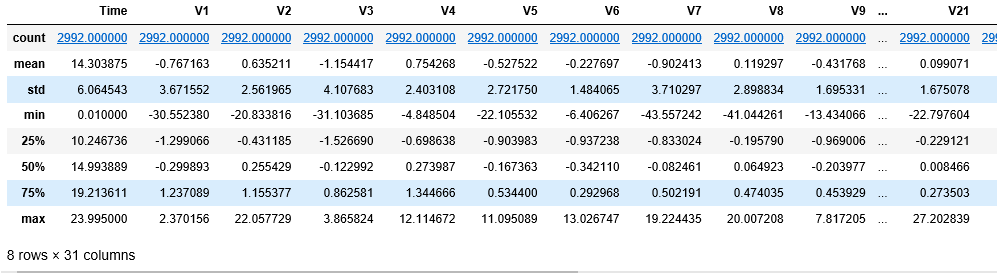
Paso 4: Definición de una función de utilidad para trazar los datos
def tsne_plot(x, y): # Setting the plotting background sns.set(style ="whitegrid") tsne = TSNE(n_components = 2, random_state = 0) # Reducing the dimensionality of the data X_transformed = tsne.fit_transform(x) plt.figure(figsize =(12, 8)) # Building the scatter plot plt.scatter(X_transformed[np.where(y == 0), 0], X_transformed[np.where(y == 0), 1], marker ='o', color ='y', linewidth ='1', alpha = 0.8, label ='Normal') plt.scatter(X_transformed[np.where(y == 1), 0], X_transformed[np.where(y == 1), 1], marker ='o', color ='k', linewidth ='1', alpha = 0.8, label ='Fraud') # Specifying the location of the legend plt.legend(loc ='best') # Plotting the reduced data plt.show()
Paso 5: Visualización de los datos originales
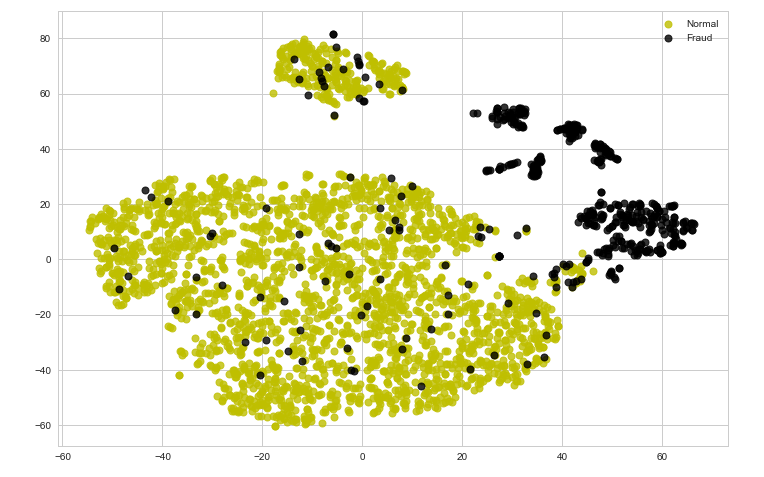
tsne_plot(X, y)
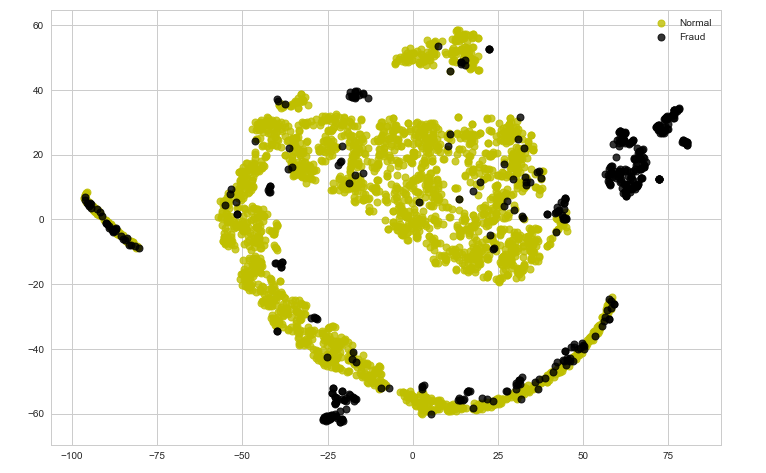
Tenga en cuenta que los datos actualmente no son fácilmente separables. En los siguientes pasos, intentaremos codificar los datos utilizando un codificador automático y analizar los resultados.
Paso 6: limpieza de los datos para que sean adecuados para el codificador automático
# Scaling the data to make it suitable for the auto-encoder X_scaled = MinMaxScaler().fit_transform(X) X_normal_scaled = X_scaled[y == 0] X_fraud_scaled = X_scaled[y == 1]
Paso 7: Creación de la red neuronal del codificador automático
# Building the Input Layer input_layer = Input(shape =(X.shape[1], )) # Building the Encoder network encoded = Dense(100, activation ='tanh', activity_regularizer = regularizers.l1(10e-5))(input_layer) encoded = Dense(50, activation ='tanh', activity_regularizer = regularizers.l1(10e-5))(encoded) encoded = Dense(25, activation ='tanh', activity_regularizer = regularizers.l1(10e-5))(encoded) encoded = Dense(12, activation ='tanh', activity_regularizer = regularizers.l1(10e-5))(encoded) encoded = Dense(6, activation ='relu')(encoded) # Building the Decoder network decoded = Dense(12, activation ='tanh')(encoded) decoded = Dense(25, activation ='tanh')(decoded) decoded = Dense(50, activation ='tanh')(decoded) decoded = Dense(100, activation ='tanh')(decoded) # Building the Output Layer output_layer = Dense(X.shape[1], activation ='relu')(decoded)
Paso 8: Definición y entrenamiento del codificador automático
# Defining the parameters of the Auto-encoder network autoencoder = Model(input_layer, output_layer) autoencoder.compile(optimizer ="adadelta", loss ="mse") # Training the Auto-encoder network autoencoder.fit(X_normal_scaled, X_normal_scaled, batch_size = 16, epochs = 10, shuffle = True, validation_split = 0.20)
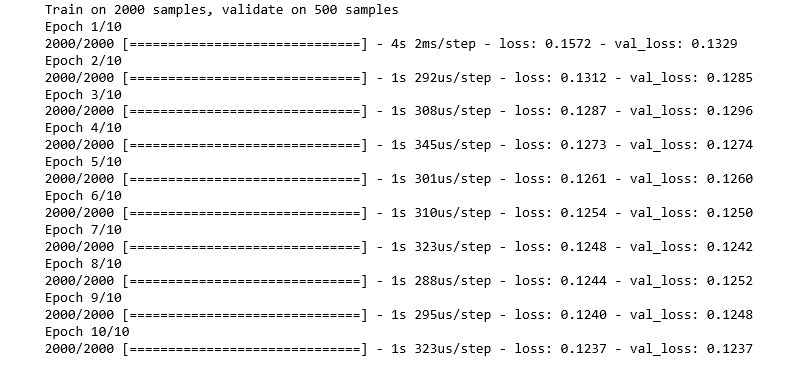
Paso 9: Conservación de la parte del codificador del codificador automático para codificar datos
hidden_representation = Sequential() hidden_representation.add(autoencoder.layers[0]) hidden_representation.add(autoencoder.layers[1]) hidden_representation.add(autoencoder.layers[2]) hidden_representation.add(autoencoder.layers[3]) hidden_representation.add(autoencoder.layers[4])
Paso 10: Codificación de los datos y visualización de los datos codificados
# Separating the points encoded by the Auto-encoder as normal and fraud normal_hidden_rep = hidden_representation.predict(X_normal_scaled) fraud_hidden_rep = hidden_representation.predict(X_fraud_scaled) # Combining the encoded points into a single table encoded_X = np.append(normal_hidden_rep, fraud_hidden_rep, axis = 0) y_normal = np.zeros(normal_hidden_rep.shape[0]) y_fraud = np.ones(fraud_hidden_rep.shape[0]) encoded_y = np.append(y_normal, y_fraud) # Plotting the encoded points tsne_plot(encoded_X, encoded_y)
Observe que después de codificar los datos, los datos se han acercado a ser linealmente separables. Por lo tanto, en algunos casos, la codificación de datos puede ayudar a que el límite de clasificación de los datos sea lineal. Para analizar numéricamente este punto, ajustaremos el modelo de Regresión Logística Lineal sobre los datos codificados y el Clasificador de Vectores Soporte sobre los datos originales.
Paso 11: Dividir los datos originales y codificados en datos de entrenamiento y prueba
# Splitting the encoded data for linear classification X_train_encoded, X_test_encoded, y_train_encoded, y_test_encoded = train_test_split(encoded_X, encoded_y, test_size = 0.2) # Splitting the original data for non-linear classification X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
Paso 12: Construcción del modelo de Regresión Logística y evaluación de su desempeño
# Building the logistic regression model
lrclf = LogisticRegression()
lrclf.fit(X_train_encoded, y_train_encoded)
# Storing the predictions of the linear model
y_pred_lrclf = lrclf.predict(X_test_encoded)
# Evaluating the performance of the linear model
print('Accuracy : '+str(accuracy_score(y_test_encoded, y_pred_lrclf)))
![]()
Paso 13: Construcción del modelo Clasificador de vectores de soporte y evaluación de su rendimiento
# Building the SVM model
svmclf = SVC()
svmclf.fit(X_train, y_train)
# Storing the predictions of the non-linear model
y_pred_svmclf = svmclf.predict(X_test)
# Evaluating the performance of the non-linear model
print('Accuracy : '+str(accuracy_score(y_test, y_pred_svmclf)))
![]()
Por lo tanto, las métricas de rendimiento respaldan el punto mencionado anteriormente de que la codificación de los datos a veces puede ser útil para hacer que los datos sean linealmente separables, ya que el rendimiento del modelo de regresión logística lineal es muy similar al rendimiento del modelo clasificador de vectores de soporte no lineal.
Publicación traducida automáticamente
Artículo escrito por AlindGupta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA