¿Qué son los trozos?
Estos se componen de palabras y los tipos de palabras se definen utilizando las etiquetas de parte del discurso. Incluso se puede definir un patrón o palabras que no pueden ser parte de chuck y esas palabras se conocen como grietas. Una clase ChunkRule especifica qué palabras o patrones incluir y excluir en un fragmento.
Cómo funciona :
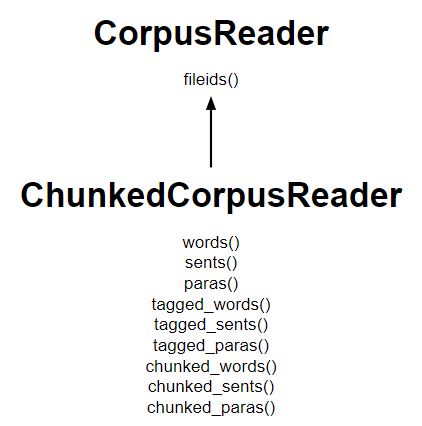
- La clase ChunkedCorpusReader funciona de manera similar a TaggedCorpusReader para obtener tokens etiquetados, además, también proporciona tres métodos nuevos para obtener fragmentos.
- Una instancia de nltk.tree.Tree representa cada fragmento.
- Los árboles de sintagmas nominales se parecen a Tree(‘NP’, […]) mientras que los árboles de nivel Oración se parecen a Tree(‘S’, […]).
- Se obtiene una lista de árboles de oraciones, con cada frase nominal como un subárbol de la oración en n chunked_sents()
- En chunked_words() se obtiene una lista de árboles de frases nominales junto con tokens etiquetados de palabras que no estaban en un fragmento.
Diagrama que enumera los principales métodos:
Código #1: Creando un ChunkedCorpusReader para palabras
Python3
# Using ChunkedCorpusReader
from nltk.corpus.reader import ChunkedCorpusReader
# initializing
x = ChunkedCorpusReader('.', r'.*\.chunk')
words = x.chunked_words()
print ("Words : \n", words)
Producción :
Words :
[Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'),
('moves', 'NNS')]), ('have', 'VBP'), ...]
Código #2: Para oración
Python3
Chunked Sentence = x.chunked_sents()
print ("Chunked Sentence : \n", tagged_sent)
Producción :
Chunked Sentence :
[Tree('S', [Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'),
('moves', 'NNS')]), ('have', 'VBP'), ('trimmed', 'VBN'), ('about', 'IN'),
Tree('NP', [('300', 'CD'), ('jobs', 'NNS')]), (', ', ', '),
Tree('NP', [('the', 'DT'), ('spokesman', 'NN')]), ('said', 'VBD'), ('.', '.')])]
Código #3: Para párrafos
Python3
para = x.chunked_paras()()
print ("para : \n", para)
Producción :
[[Tree('S', [Tree('NP', [('Earlier', 'JJR'), ('staff-reduction',
'NN'), ('moves', 'NNS')]), ('have', 'VBP'), ('trimmed', 'VBN'),
('about', 'IN'),
Tree('NP', [('300', 'CD'), ('jobs', 'NNS')]), (', ', ', '),
Tree('NP', [('the', 'DT'), ('spokesman', 'NN')]), ('said', 'VBD'), ('.', '.')])]]
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA