En este artículo, vamos a discutir una técnica de procesamiento de lenguaje natural de modelado de texto conocida como modelo de bolsa de palabras . Siempre que aplicamos cualquier algoritmo en PNL, funciona en números. No podemos introducir directamente nuestro texto en ese algoritmo. Por lo tanto, el modelo Bolsa de palabras se usa para preprocesar el texto convirtiéndolo en una bolsa de palabras , que lleva un recuento del total de ocurrencias de las palabras más utilizadas.
Este modelo se puede visualizar utilizando una tabla, que contiene el recuento de palabras correspondientes a la palabra misma.
Aplicando el modelo de la Bolsa de Palabras:
Tomemos este párrafo de muestra para nuestra tarea:
Frijoles. Estaba tratando de explicarle a alguien mientras volábamos, eso es maíz. Eso es frijoles. Y quedaron muy impresionados con mis conocimientos agrícolas. Por favor, déjalo por Amaury una vez más por esa excelente introducción. Tengo un montón de buenos amigos aquí hoy, incluido alguien con quien serví, que es uno de los mejores senadores del país, y tenemos suerte de tenerlo, su senador, Dick Durbin, está aquí. También me fijé, por cierto, en el exgobernador Edgar, a quien no había visto en mucho tiempo y, de alguna manera, él no ha envejecido y yo sí. Y es genial verlo, gobernador. Quiero agradecer al presidente Killeen ya todos en U of I System por hacer posible que yo esté aquí hoy. Y me siento profundamente honrado con el premio Paul Douglas que me otorgan. Es alguien que abrió el camino para tanto servicio público destacado aquí en Illinois. Ahora, quiero comenzar dirigiéndome al elefante en la habitación. Sé que la gente todavía se pregunta por qué no hablé en la ceremonia de graduación.
Paso #1: Primero preprocesaremos los datos para:
- Convertir texto a minúsculas.
- Elimina todos los caracteres que no sean palabras.
- Eliminar todos los signos de puntuación.
# Python3 code for preprocessing text import nltk import re import numpy as np # execute the text here as : # text = """ # place text here """ dataset = nltk.sent_tokenize(text) for i in range(len(dataset)): dataset[i] = dataset[i].lower() dataset[i] = re.sub(r'\W', ' ', dataset[i]) dataset[i] = re.sub(r'\s+', ' ', dataset[i])
Producción:
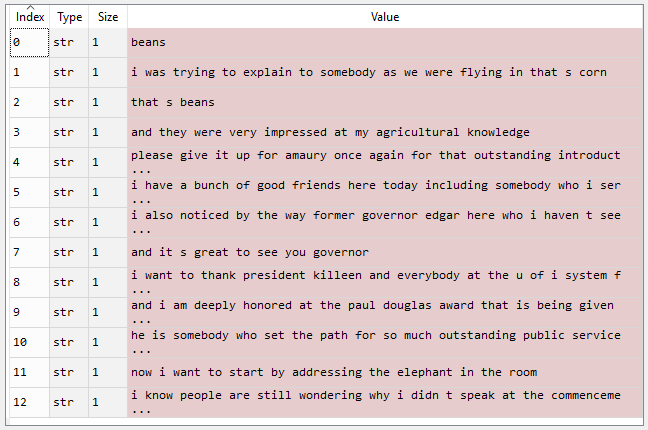
Texto preprocesado
Puede preprocesar aún más el texto para adaptarlo a sus necesidades.
Paso #2: Obtención de las palabras más frecuentes en nuestro texto.
Aplicaremos los siguientes pasos para generar nuestro modelo.
# Creating the Bag of Words modelword2count = {}for data in dataset: words = nltk.word_tokenize(data) for word in words: if word not in word2count.keys(): word2count[word] = 1 else: word2count[word] += 1 |
Producción:
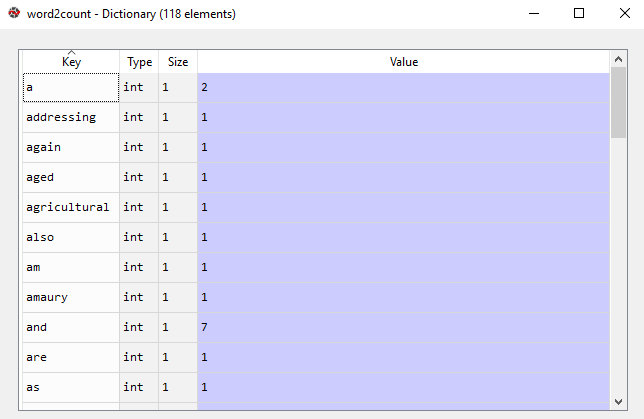
Bolsa de diccionario de palabras
En nuestro modelo, tenemos un total de 118 palabras. Sin embargo, al procesar textos grandes, la cantidad de palabras podría llegar a millones. No necesitamos usar todas esas palabras. Por lo tanto, seleccionamos un número particular de palabras de uso más frecuente. Para implementar esto usamos:
import heapqfreq_words = heapq.nlargest(100, word2count, key=word2count.get) |
donde 100 denota el número de palabras que queremos. Si nuestro texto es grande, ingresamos un número mayor.
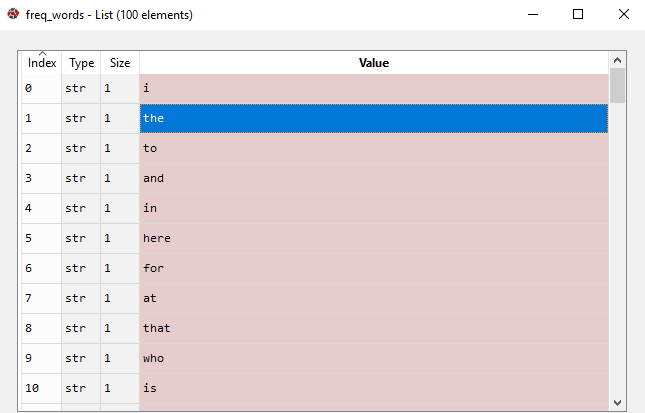
100 palabras más frecuentes
Paso #3: Construyendo el modelo de la Bolsa de Palabras
En este paso construimos un vector, el cual nos diría si una palabra en cada oración es una palabra frecuente o no. Si una palabra en una oración es una palabra frecuente, la establecemos como 1, de lo contrario, la establecemos como 0.
Esto se puede implementar con la ayuda del siguiente código:
X = []for data in dataset: vector = [] for word in freq_words: if word in nltk.word_tokenize(data): vector.append(1) else: vector.append(0) X.append(vector)X = np.asarray(X) |
Producción:
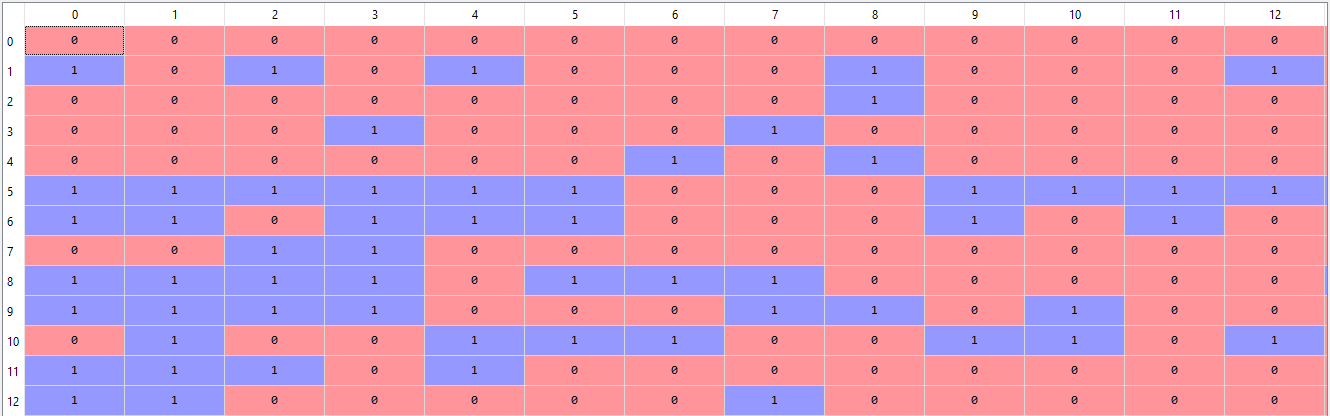
modelo de proa
Publicación traducida automáticamente
Artículo escrito por noob_coders_ka_baap y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA