La operación de agrupación implica deslizar un filtro bidimensional sobre cada canal del mapa de características y resumir las características que se encuentran dentro de la región cubierta por el filtro.
Para un mapa de características que tiene dimensiones n h xn w xn c , las dimensiones de salida obtenidas después de una capa de agrupación son
(nh - f + 1) / s x (nw - f + 1)/s x nc
dónde,
-> nh - height of feature map -> nw - width of feature map -> nc - number of channels in the feature map -> f - size of filter -> s - stride length
Una arquitectura de modelo de CNN común es tener varias capas de convolución y agrupación apiladas una tras otra.
¿Por qué usar Pooling Layers?
- Las capas de agrupación se utilizan para reducir las dimensiones de los mapas de características. Por lo tanto, reduce la cantidad de parámetros a aprender y la cantidad de cómputo realizado en la red.
- La capa de agrupación resume las características presentes en una región del mapa de características generado por una capa de convolución. Por lo tanto, se realizan más operaciones en características resumidas en lugar de características posicionadas con precisión generadas por la capa de convolución. Esto hace que el modelo sea más resistente a las variaciones en la posición de las características en la imagen de entrada.
Tipos de capas de agrupación:
Agrupación máxima
- La agrupación máxima es una operación de agrupación que selecciona el elemento máximo de la región del mapa de características cubierto por el filtro. Por lo tanto, la salida después de la capa de agrupación máxima sería un mapa de características que contiene las características más destacadas del mapa de características anterior.

- Esto se puede lograr usando la capa MaxPooling2D en keras de la siguiente manera:
Código n.º 1: realizar Max Pooling usando keras
Python3
import numpy as np from keras.models import Sequential from keras.layers import MaxPooling2D # define input image image = np.array([[2, 2, 7, 3], [9, 4, 6, 1], [8, 5, 2, 4], [3, 1, 2, 6]]) image = image.reshape(1, 4, 4, 1) # define model containing just a single max pooling layer model = Sequential( [MaxPooling2D(pool_size = 2, strides = 2)]) # generate pooled output output = model.predict(image) # print output image output = np.squeeze(output) print(output)
- Producción:
[[9. 7.] [8. 6.]]
Agrupación promedio
- La agrupación promedio calcula el promedio de los elementos presentes en la región del mapa de características cubierto por el filtro. Por lo tanto, mientras que la agrupación máxima brinda la característica más destacada en un parche particular del mapa de características, la agrupación promedio brinda el promedio de las características presentes en un parche.
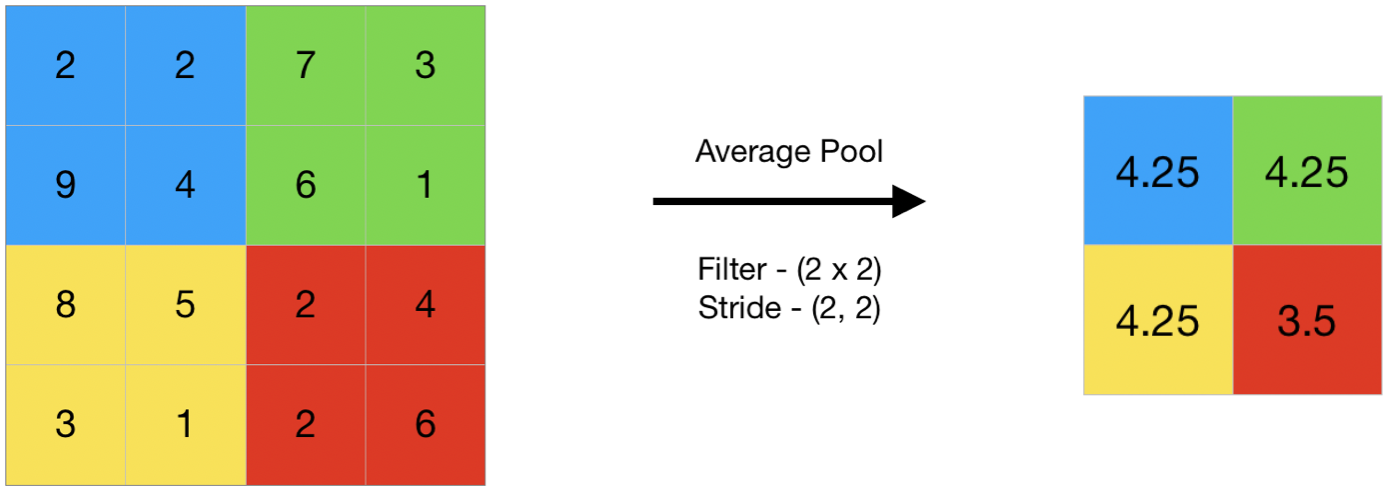
- Código n.º 2: Realización de agrupación promedio usando keras
Python3
import numpy as np from keras.models import Sequential from keras.layers import AveragePooling2D # define input image image = np.array([[2, 2, 7, 3], [9, 4, 6, 1], [8, 5, 2, 4], [3, 1, 2, 6]]) image = image.reshape(1, 4, 4, 1) # define model containing just a single average pooling layer model = Sequential( [AveragePooling2D(pool_size = 2, strides = 2)]) # generate pooled output output = model.predict(image) # print output image output = np.squeeze(output) print(output)
- Producción:
[[4.25 4.25] [4.25 3.5 ]]
Agrupación global
- La agrupación global reduce cada canal en el mapa de características a un solo valor. Por lo tanto, un mapa de características de n h xn w xn c se reduce a un mapa de características de 1 x 1 xn c . Esto es equivalente a usar un filtro de dimensiones n h x n w , es decir, las dimensiones del mapa de características.
Además, puede ser una agrupación máxima global o una agrupación promedio global.
Código n.º 3: Realización de una agrupación global mediante keras
Python3
import numpy as np
from keras.models import Sequential
from keras.layers import GlobalMaxPooling2D
from keras.layers import GlobalAveragePooling2D
# define input image
image = np.array([[2, 2, 7, 3],
[9, 4, 6, 1],
[8, 5, 2, 4],
[3, 1, 2, 6]])
image = image.reshape(1, 4, 4, 1)
# define gm_model containing just a single global-max pooling layer
gm_model = Sequential(
[GlobalMaxPooling2D()])
# define ga_model containing just a single global-average pooling layer
ga_model = Sequential(
[GlobalAveragePooling2D()])
# generate pooled output
gm_output = gm_model.predict(image)
ga_output = ga_model.predict(image)
# print output image
gm_output = np.squeeze(gm_output)
ga_output = np.squeeze(ga_output)
print("gm_output: ", gm_output)
print("ga_output: ", ga_output)
- Producción:
gm_output: 9.0 ga_output: 4.0625
Publicación traducida automáticamente
Artículo escrito por savyakhosla y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA