Generalmente, para cualquier problema de clasificación, predecimos el valor de clase que tiene la mayor probabilidad de ser la verdadera etiqueta de clase. Sin embargo, a veces, queremos predecir las probabilidades de que una instancia de datos pertenezca a cada etiqueta de clase . Por ejemplo, digamos que estamos construyendo un modelo para clasificar frutas y tenemos tres etiquetas de clase: manzanas, naranjas y plátanos (cada fruta es una de estas). Para cualquier fruta, queremos las probabilidades de que la fruta sea una manzana, una naranja o un plátano.
Esto es muy útil para la evaluación de un modelo de clasificación. Puede ayudarnos a comprender qué tan ‘seguro’ es un modelo al predecir una etiqueta de clase y puede ayudarnos a interpretar qué tan decisivo es un modelo de clasificación. En general, los clasificadores que tienen una probabilidad lineal de predecir las etiquetas de cada clase se denominancalibrado _ El problema es que no todos los modelos de clasificación están calibrados.
Algunos modelos pueden dar estimaciones deficientes de las probabilidades de clase y algunos ni siquiera admiten la predicción de probabilidad.
Curvas de calibración:
Las curvas de calibración se utilizan para evaluar qué tan calibrado está un clasificador, es decir, cómo difieren las probabilidades de predecir cada etiqueta de clase. El eje x representa la probabilidad pronosticada promedio en cada contenedor. El eje y es la proporción de positivos (la proporción de predicciones positivas). La curva del modelo calibrado ideal es una línea recta lineal desde (0, 0) que se mueve linealmente.
Trazado de curvas de calibración en Python3:
para este ejemplo, utilizaremos un conjunto de datos binarios. Usaremos el popular conjunto de datos de diabetes. Puede obtener más información sobre este conjunto de datos aquí .
Código: Implementar la curva de calibración de una máquina de vectores de soporte y compararla con la curva de un modelo perfectamente calibrado.
Python3
# Importing required modules
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.calibration import calibration_curve
import matplotlib.pyplot as plt
# Loading dataset
dataset = load_breast_cancer()
X = dataset.data
y = dataset.target
# Splitting dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size = 0.1, random_state = 13)
# Creating and fitting model
model = SVC()
model.fit(X_train, y_train)
# Predict Probabilities
prob = model.decision_function(X_test)
# Creating Calibration Curve
x, y = calibration_curve(y_test, prob, n_bins = 10, normalize = True)
# Plot calibration curve
# Plot perfectly calibrated
plt.plot([0, 1], [0, 1], linestyle = '--', label = 'Ideally Calibrated')
# Plot model's calibration curve
plt.plot(y, x, marker = '.', label = 'Support Vector Classifier')
leg = plt.legend(loc = 'upper left')
plt.xlabel('Average Predicted Probability in each bin')
plt.ylabel('Ratio of positives')
plt.show()
Producción:
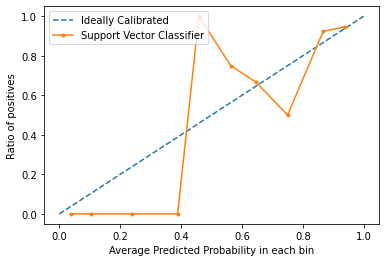
En el gráfico, podemos ver claramente que el clasificador de vectores de soporte no está muy bien calibrado. Cuanto más se acerca la curva de un modelo a la curva del modelo calibrado perfecto (curva punteada), mejor calibrado está.
Conclusión:
ahora que sabe qué es la calibración en términos de aprendizaje automático y cómo trazar una curva de calibración, la próxima vez que su clasificador dé resultados impredecibles y no pueda encontrar la causa, intente trazar la curva de calibración y verifique si el modelo está bien. -calibrado.
Publicación traducida automáticamente
Artículo escrito por alokesh985 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA