Este artículo muestra una ilustración del agrupamiento de K-means en una muestra de datos aleatorios utilizando la biblioteca open-cv.
Requisitos previos: Numpy , OpenCV, matplot-lib
Primero, visualicemos los datos de prueba con funciones múltiples usando la herramienta matplot-lib.
# importing required tools
import numpy as np
from matplotlib import pyplot as plt
# creating two test data
X = np.random.randint(10,35,(25,2))
Y = np.random.randint(55,70,(25,2))
Z = np.vstack((X,Y))
Z = Z.reshape((50,2))
# convert to np.float32
Z = np.float32(Z)
plt.xlabel('Test Data')
plt.ylabel('Z samples')
plt.hist(Z,256,[0,256])
plt.show()
Aquí ‘Z’ es una array de tamaño 100 y valores que van de 0 a 255. Ahora, transforme ‘z’ en un vector de columna. Será más útil cuando haya más de una característica presente. Luego cambie los datos al tipo np.float32.
Producción: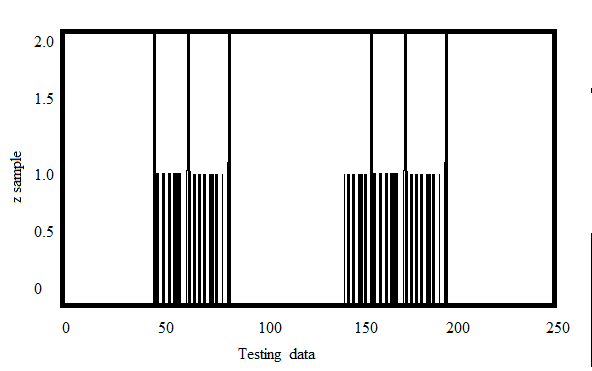
Ahora, aplique el algoritmo de agrupamiento k-Means al mismo ejemplo que en los datos de prueba anteriores y vea su comportamiento.
Pasos a seguir:
1) Primero, necesitamos establecer datos de prueba.
2) Definir criterios y aplicar kmeans().
3) Ahora separa los datos.
4) Finalmente Grafique los datos.
import numpy as np
import cv2
from matplotlib import pyplot as plt
X = np.random.randint(10,45,(25,2))
Y = np.random.randint(55,70,(25,2))
Z = np.vstack((X,Y))
# convert to np.float32
Z = np.float32(Z)
# define criteria and apply kmeans()
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0)
ret,label,center = cv2.kmeans(Z,2,None,criteria,10,cv2.KMEANS_RANDOM_CENTERS)
# Now separate the data
A = Z[label.ravel()==0]
B = Z[label.ravel()==1]
# Plot the data
plt.scatter(A[:,0],A[:,1])
plt.scatter(B[:,0],B[:,1],c = 'r')
plt.scatter(center[:,0],center[:,1],s = 80,c = 'y', marker = 's')
plt.xlabel('Test Data'),plt.ylabel('Z samples')
plt.show()
Producción: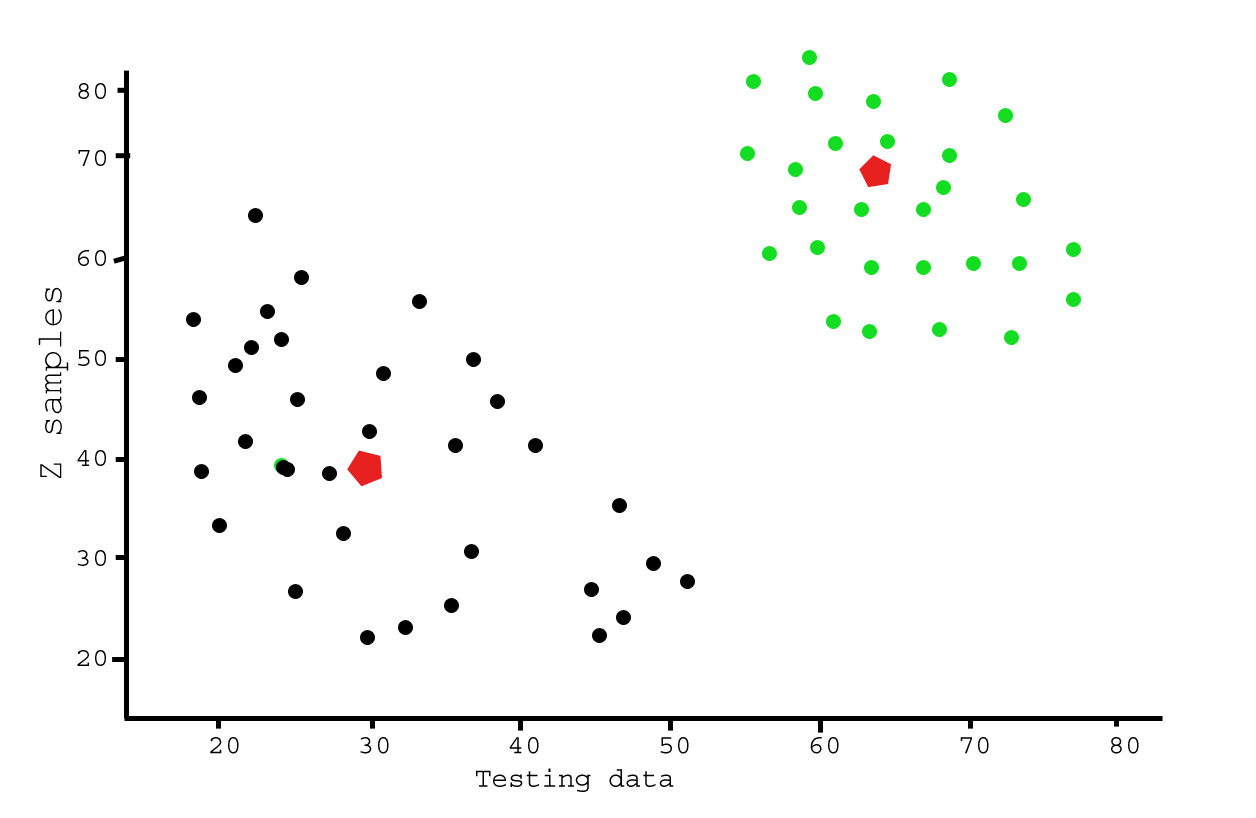
Este ejemplo pretende ilustrar dónde k-means producirá clústeres intuitivamente posibles.
Aplicaciones :
1) Identificación de datos cancerosos.
2) Predicción del Rendimiento Académico de los Estudiantes.
3) Predicción de actividad de fármacos.
Publicación traducida automáticamente
Artículo escrito por AFZAL ANSARI y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA