Un modelo de aprendizaje automático se define como un modelo matemático con una serie de parámetros que deben aprenderse de los datos. Sin embargo, hay algunos parámetros, conocidos como hiperparámetros , que no se pueden aprender directamente. Por lo general, los humanos los eligen en función de su intuición o prueban antes de que comience el entrenamiento real. Estos parámetros exhiben su importancia al mejorar el rendimiento del modelo, como su complejidad o su tasa de aprendizaje. Los modelos pueden tener muchos hiperparámetros y encontrar la mejor combinación de parámetros puede tratarse como un problema de búsqueda.
MVStambién tiene algunos hiperparámetros (como qué valores C o gamma usar) y encontrar el hiperparámetro óptimo es una tarea muy difícil de resolver. Pero se puede encontrar simplemente probando todas las combinaciones y viendo qué parámetros funcionan mejor. La idea principal detrás de esto es crear una cuadrícula de hiperparámetros y simplemente probar todas sus combinaciones (por lo tanto, este método se llama Gridsearch , pero no se preocupe, no tenemos que hacerlo manualmente porque Scikit-learn tiene esta funcionalidad integrada con GridSearchCV.
GridSearchCV toma un diccionario que describe los parámetros que se pueden probar en un modelo para entrenarlo. La cuadrícula de parámetros se define como un diccionario, donde las claves son los parámetros y los valores son las configuraciones para ser probado
Este artículo demuestra cómo usar elMétodo de búsqueda GridSearchCV para encontrar hiperparámetros óptimos y, por lo tanto, mejorar los resultados de precisión/predicción
Importe las bibliotecas necesarias y obtenga los datos:
Usaremos el conjunto de datos de cáncer de mama integrado de Scikit Learn. Podemos obtener con la función de carga:
Python3
import pandas as pd import numpy as np from sklearn.metrics import classification_report, confusion_matrix from sklearn.datasets import load_breast_cancer from sklearn.svm import SVC cancer = load_breast_cancer() # The data set is presented in a dictionary form: print(cancer.keys())
dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
Ahora extraeremos todas las funciones en el nuevo marco de datos y nuestras funciones de destino en marcos de datos separados.
Python3
df_feat = pd.DataFrame(cancer['data'],
columns = cancer['feature_names'])
# cancer column is our target
df_target = pd.DataFrame(cancer['target'],
columns =['Cancer'])
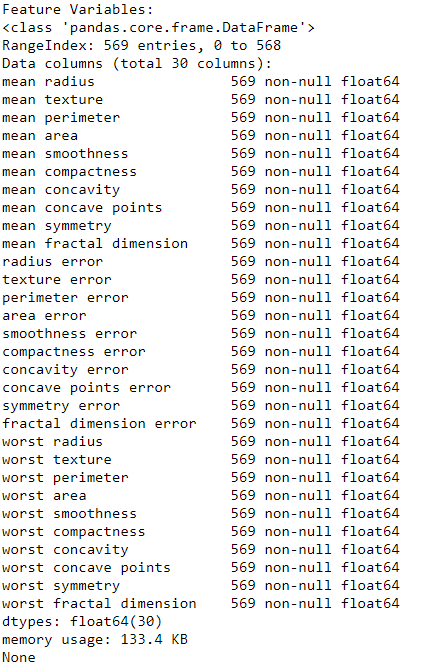
print("Feature Variables: ")
print(df_feat.info())
Python3
print("Dataframe looks like : ")
print(df_feat.head())
División de prueba de tren
Ahora dividiremos nuestros datos en tren y conjunto de prueba con una proporción de 70: 30
Python3
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( df_feat, np.ravel(df_target), test_size = 0.30, random_state = 101)
Entrenar el clasificador de vectores de soporte sin ajuste de hiperparámetros –
Primero, entrenaremos nuestro modelo llamando a la función SVC() estándar sin realizar el ajuste de hiperparámetros y veremos su array de clasificación y confusión.
Python3
# train the model on train set model = SVC() model.fit(X_train, y_train) # print prediction results predictions = model.predict(X_test) print(classification_report(y_test, predictions))
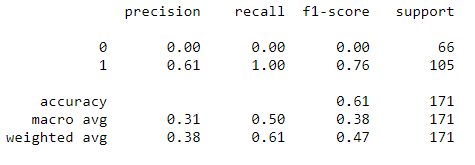
Obtuvimos un 61 % de precisión, pero ¿notaste algo extraño?
Tenga en cuenta que la recuperación y la precisión para la clase 0 son siempre 0. ¡Significa que el clasificador siempre clasifica todo en una sola clase, es decir, la clase 1! Esto significa que nuestro modelo necesita tener sus parámetros ajustados.
Aquí es cuando la utilidad de GridSearch entra en escena. ¡Podemos buscar parámetros usando GridSearch!
Usar GridsearchCV
Una de las mejores cosas de GridSearchCV es que es un metaestimador. Toma un estimador como SVC y crea un nuevo estimador, que se comporta exactamente igual, en este caso, como un clasificador. Debe agregar refit=True y elegir detallado al número que desee, cuanto mayor sea el número, más detallado (detallado solo significa la salida de texto que describe el proceso).
Python3
from sklearn.model_selection import GridSearchCV
# defining parameter range
param_grid = {'C': [0.1, 1, 10, 100, 1000],
'gamma': [1, 0.1, 0.01, 0.001, 0.0001],
'kernel': ['rbf']}
grid = GridSearchCV(SVC(), param_grid, refit = True, verbose = 3)
# fitting the model for grid search
grid.fit(X_train, y_train)
Lo que hace el ajuste es un poco más complicado de lo habitual. Primero, ejecuta el mismo bucle con validación cruzada para encontrar la mejor combinación de parámetros. Una vez que tiene la mejor combinación, vuelve a ejecutar el ajuste en todos los datos pasados para ajustar (sin validación cruzada), para construir un nuevo modelo único usando la mejor configuración de parámetros.
Puede inspeccionar los mejores parámetros encontrados por GridSearchCV en el atributo best_params_ y el mejor estimador en el atributo best_estimator_:
Python3
# print best parameter after tuning print(grid.best_params_) # print how our model looks after hyper-parameter tuning print(grid.best_estimator_)

Luego puede volver a ejecutar predicciones y ver un informe de clasificación en este objeto de cuadrícula como lo haría con un modelo normal.
Python3
grid_predictions = grid.predict(X_test) # print classification report print(classification_report(y_test, grid_predictions))
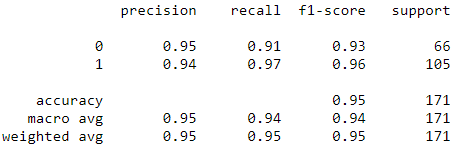
Tenemos un resultado de predicción de casi el 95 % .
Publicación traducida automáticamente
Artículo escrito por tyagikartik4282 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA