Introducción
En este artículo vamos a aprender a clasificar algunas señales de tráfico comunes que nos encontramos ocasionalmente en nuestra vida diaria en la carretera. Al construir un automóvil autónomo, es necesario asegurarse de que identifique las señales de tránsito con un alto grado de precisión, a menos que los resultados puedan ser catastróficos. Mientras viajaba, es posible que se haya encontrado con numerosas señales de tráfico, como la señal de límite de velocidad, la señal de giro a la izquierda o a la derecha, la señal de alto, etc. Clasificar todo esto con precisión puede ser una tarea desalentadora, y ahí es donde esta publicación lo ayudará.

Puede obtener el conjunto de datos desde este enlace: Datos . Contiene 4 archivos –
- signnames.csv – Tiene todas las etiquetas y sus descriptores.
- train.p : contiene todas las intensidades de píxeles de la imagen de entrenamiento junto con las etiquetas.
- valid.p : contiene todas las intensidades de píxeles de la imagen de validación junto con las etiquetas.
- test.p : contiene todas las intensidades de píxeles de la imagen de prueba junto con las etiquetas.
Los archivos anteriores con extensión .p se denominan archivos pickle, que se utilizan para serializar objetos en secuencias de caracteres. Estos se pueden deserializar y reutilizar más tarde cargándolos usando la biblioteca pickle en python.
Implementemos una red neuronal convolucional (CNN) usando Keras en pasos simples y fáciles de seguir. Una CNN consta de una serie de capas convolucionales y de agrupación en la red neuronal que se mapean con la entrada para extraer características. Una capa de convolución tendrá muchos filtros que se utilizan principalmente para detectar las características de bajo nivel, como los bordes de una cara. La capa Pooling reduce la dimensionalidad para disminuir el cálculo. Además, también extrae las características dominantes ignorando los píxeles laterales. Para leer más sobre las CNN, vaya a este enlace.
Importación de las bibliotecas
Necesitaremos las siguientes bibliotecas. Asegúrese de instalar NumPy , Pandas , Keras , Matplotlib y OpenCV antes de implementar el siguiente código.
import numpy as np import matplotlib.pyplot as plt import keras from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers.convolutional import Conv2D, MaxPooling2D from keras.optimizers import Adam from keras.utils.np_utils import to_categorical from keras.preprocessing.image import ImageDataGenerator import pickle import pandas as pd import random import cv2 np.random.seed(0)
Aquí, estamos usando numpy para cálculos numéricos, pandas para importar y administrar el conjunto de datos, Keras para construir la red neuronal convolucional rápidamente con menos código, cv2 para realizar algunos pasos de preprocesamiento que son necesarios para la extracción eficiente de características de las imágenes por parte de CNN. .
Cargando el conjunto de datos
Tiempo para cargar los datos. Usaremos pandas para cargar signnames.csv y pickle para cargar los archivos de tren, validación y prueba pickle. Después de la extracción de datos, se divide utilizando las etiquetas del diccionario «características» y «etiquetas».
# Read data
data = pd.read_csv("german-traffic-signs / signnames.csv")
with open('german-traffic-signs / train.p', 'rb') as f:
train_data = pickle.load(f)
with open('german-traffic-signs / valid.p', 'rb') as f:
val_data = pickle.load(f)
with open('german-traffic-signs / test.p', 'rb') as f:
test_data = pickle.load(f)
# Extracting the labels from the dictionaries
X_train, y_train = train_data['features'], train_data['labels']
X_val, y_val = val_data['features'], val_data['labels']
X_test, y_test = test_data['features'], test_data['labels']
# Printing the shapes
print(X_train.shape)
print(X_val.shape)
print(X_test.shape)
Producción:
(34799, 32, 32, 3) (4410, 32, 32, 3) (12630, 32, 32, 3)
El preprocesamiento de los datos con OpenCV El
preprocesamiento de imágenes antes de alimentar el modelo brinda resultados muy precisos, ya que ayuda a extraer las características complejas de la imagen. OpenCV tiene algunas funciones integradas como cvtColor() y equalizeHist() para esta tarea. Siga los pasos a continuación para esta tarea:
- Primero, las imágenes se convierten en imágenes en escala de grises para reducir el cálculo mediante la función cvtColor() .
- La función equalizeHist() aumenta los contrastes de la imagen al igualar las intensidades de los píxeles al normalizarlos con sus píxeles cercanos.
- Al final, normalizamos los valores de píxel entre 0 y 1 dividiéndolos por 255.
def preprocessing(img): img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) img = cv2.equalizeHist(img) img = img / 255 return img X_train = np.array(list(map(preprocessing, X_train))) X_val = np.array(list(map(preprocessing, X_val))) X_test = np.array(list(map(preprocessing, X_test))) X_train = X_train.reshape(34799, 32, 32, 1) X_val = X_val.reshape(4410, 32, 32, 1) X_test = X_test.reshape(12630, 32, 32, 1)
Después de remodelar las arrays, es hora de introducirlas en el modelo para el entrenamiento. Pero para aumentar la precisión de nuestro modelo CNN, implicaremos un paso más de generación de imágenes aumentadas utilizando ImageDataGenerator.
Esto se hace para reducir el sobreajuste de los datos de entrenamiento, ya que obtener datos más variados dará como resultado un mejor modelo. El valor 0,1 se interpreta como 10%, mientras que 10 es el grado de rotación. También estamos convirtiendo las etiquetas en valores categóricos, como hacemos normalmente.
datagen = ImageDataGenerator(width_shift_range = 0.1, height_shift_range = 0.1, zoom_range = 0.2, shear_range = 0.1, rotation_range = 10) datagen.fit(X_train) y_train = to_categorical(y_train, 43) y_val = to_categorical(y_val, 43) y_test = to_categorical(y_test, 43)
Construyendo el modelo
Como tenemos 43 clases de imágenes en el conjunto de datos, estamos configurando num_classes como 43. El modelo contiene dos capas Conv2D seguidas de una capa MaxPooling2D. Esto se hace dos veces para la extracción efectiva de características, seguida por las capas Densas. Se agrega una capa de abandono de 0,5 para evitar el sobreajuste de los datos.
num_classes = 43 def cnn_model(): model = Sequential() model.add(Conv2D(60, (5, 5), input_shape =(32, 32, 1), activation ='relu')) model.add(Conv2D(60, (5, 5), activation ='relu')) model.add(MaxPooling2D(pool_size =(2, 2))) model.add(Conv2D(30, (3, 3), activation ='relu')) model.add(Conv2D(30, (3, 3), activation ='relu')) model.add(MaxPooling2D(pool_size =(2, 2))) model.add(Flatten()) model.add(Dense(500, activation ='relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes, activation ='softmax')) # Compile model model.compile(Adam(lr = 0.001), loss ='categorical_crossentropy', metrics =['accuracy']) return model model = cnn_model() history = model.fit_generator(datagen.flow(X_train, y_train, batch_size = 50), steps_per_epoch = 2000, epochs = 10, validation_data =(X_val, y_val), shuffle = 1)
Output: Epoch 1/10 2000/2000 [==============================] - 129s 65ms/step - loss: 0.9130 - acc: 0.7322 - val_loss: 0.0984 - val_acc: 0.9669 Epoch 2/10 2000/2000 [==============================] - 119s 60ms/step - loss: 0.2084 - acc: 0.9352 - val_loss: 0.0609 - val_acc: 0.9803 Epoch 3/10 2000/2000 [==============================] - 116s 58ms/step - loss: 0.1399 - acc: 0.9562 - val_loss: 0.0409 - val_acc: 0.9878 Epoch 4/10 2000/2000 [==============================] - 115s 58ms/step - loss: 0.1066 - acc: 0.9672 - val_loss: 0.0262 - val_acc: 0.9925 Epoch 5/10 2000/2000 [==============================] - 116s 58ms/step - loss: 0.0890 - acc: 0.9726 - val_loss: 0.0268 - val_acc: 0.9925 Epoch 6/10 2000/2000 [==============================] - 115s 58ms/step - loss: 0.0777 - acc: 0.9756 - val_loss: 0.0237 - val_acc: 0.9927 Epoch 7/10 2000/2000 [==============================] - 132s 66ms/step - loss: 0.0700 - acc: 0.9779 - val_loss: 0.0327 - val_acc: 0.9900 Epoch 8/10 2000/2000 [==============================] - 122s 61ms/step - loss: 0.0618 - acc: 0.9812 - val_loss: 0.0267 - val_acc: 0.9914 Epoch 9/10 2000/2000 [==============================] - 115s 57ms/step - loss: 0.0565 - acc: 0.9830 - val_loss: 0.0146 - val_acc: 0.9957 Epoch 10/10 2000/2000 [==============================] - 120s 60ms/step - loss: 0.0577 - acc: 0.9828 - val_loss: 0.0222 - val_acc: 0.9939
Después de compilar con éxito el modelo y ajustarlo al tren y los datos de validación, evaluémoslo usando Matplotlib.
Evaluación y prueba
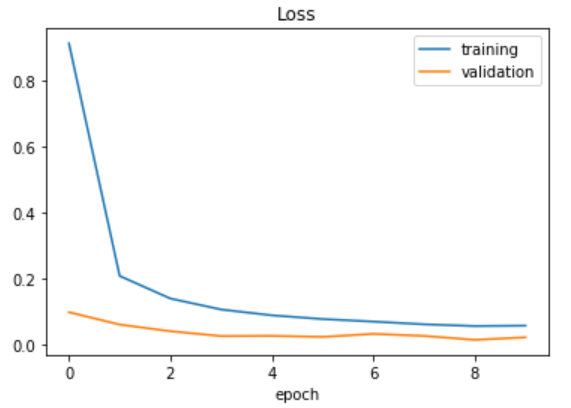
Trazado de la función de pérdida.
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.legend(['training', 'validation'])
plt.title('Loss')
plt.xlabel('epoch')
Producción:
Trazado de la función de precisión.
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.legend(['training', 'validation'])
plt.title('Accuracy')
plt.xlabel('epoch')
Producción:
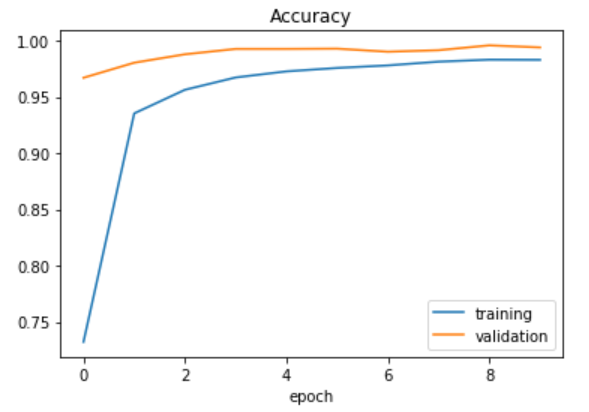
Como puede ver, hemos ajustado bien los datos manteniendo al mínimo tanto la pérdida de entrenamiento como la de validación. Es hora de evaluar cómo funciona nuestro modelo en los datos de prueba.
score = model.evaluate(X_test, y_test, verbose = 0)
print('Test Loss: ', score[0])
print('Test Accuracy: ', score[1])
Producción:
Test Loss: 0.16352852963907774 Test Accuracy: 0.9701504354899777
Verifiquemos una imagen de prueba introduciéndola en el modelo. El modelo da una predicción de clase 0 (límite de velocidad 20), que es correcta.
plt.imshow(X_test[990].reshape(32, 32))
print("Predicted sign: "+ str(
model.predict_classes(X_test[990].reshape(1, 32, 32, 1))))
Output: Predicted sign: [0]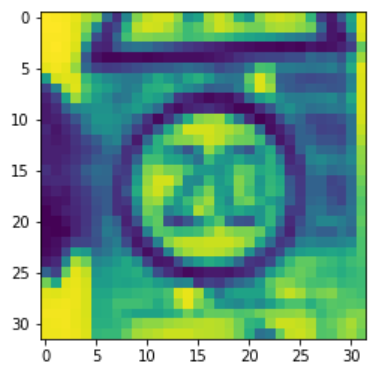
Publicación traducida automáticamente
Artículo escrito por JaideepSinghSandhu y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA