YOLO fue propuesto por Joseph Redmond et al. en 2015. Se propuso para hacer frente a los problemas que enfrentaban los modelos de reconocimiento de objetos en ese momento, Fast R-CNN es uno de los modelos más avanzados en ese momento, pero tiene sus propios desafíos, como esta red. no se puede usar en tiempo real, porque se tarda de 2 a 3 segundos en predecir una imagen y, por lo tanto, no se puede usar en tiempo real. Mientras que en YOLO tenemos que mirar solo una vez en la red, es decir, solo se requiere un pase hacia adelante a través de la red para hacer las predicciones finales.
Arquitectura:
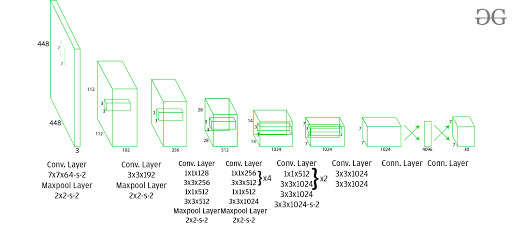
Esta arquitectura toma una imagen como entrada y la redimensiona a 448*448 manteniendo la relación de aspecto igual y realizando relleno. Esta imagen luego se pasa en la red CNN. Este modelo tiene 24 capas de convolución, 4 capas de agrupación máxima seguidas de 2 capas completamente conectadas . Para la reducción del número de capas (Canales), usamos una convolución 1*1 seguida de una convolución 3*3 . Observe que la última capa de YOLOv1 predice una salida cuboide. Esto se hace generando (1, 1470) a partir de la capa final completamente conectada y remodelándola al tamaño (7, 7, 30) .
Esta arquitectura usa Leaky ReLU como su función de activación en toda la arquitectura excepto en la última capa donde usa la función de activación lineal. La definición de Leaky ReLU se puede encontrar aquí . La normalización por lotes también ayuda a regularizar el modelo. La técnica de abandono también se utiliza para evitar el sobreajuste.
Entrenamiento:
este modelo está entrenado en el conjunto de datos ImageNet-1000 . El modelo se entrena durante una semana y logra una precisión del 88 % entre los 5 primeros en la validación de ImageNet 2012, que es comparable a GoogLeNet (ganador de ILSVRC 2014), el modelo de vanguardia en ese momento. Fast YOLO utiliza menos capas (9 en lugar de 24) y menos filtros. Excepto esto, el YOLO rápido tiene todos los parámetros similares a YOLO. YOLO usa la función de pérdida de error de suma cuadrada que es fácil de optimizar. Sin embargo, esta función otorga el mismo peso a la tarea de clasificación y localización. La función de pérdida definida en YOLO de la siguiente manera:
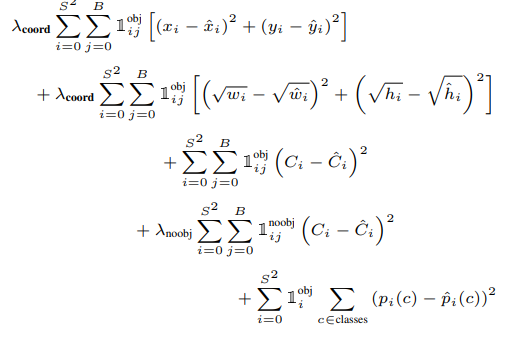
donde,  denota si el objeto está presente en la celda i .
denota si el objeto está presente en la celda i .  denota
denota  un cuadro delimitador responsable de la predicción del objeto en la celda i .
un cuadro delimitador responsable de la predicción del objeto en la celda i .
 and
and  are regularization parameter required to balance the loss function.
are regularization parameter required to balance the loss function.
In this model, we take  and
and 
The first two parts of the above loss equation represent localization mean-squared error, but the other three parts represent classification error. In the localization error, the first term calculates the deviation from the ground truth bounding box. The second term calculates the square root of the difference between height and width of the bounding box. In the second term, we take the square root of width and height because our loss function should be able to consider the deviation in terms of the size of the bounding box. For small bounding boxes, the little deviation should be more important as compared to large bounding boxes.
There are three terms in classification loss, the first term calculates the sum-squared error between the predicted confidence score that whether the object present or not and the ground truth for each bounding box in each cell. Similarly, The second term calculates the mean-squared sum of cells that do not contain any bounding box, and a regularization parameter is used to make this loss small. The third term calculates the sum-squared error of the classes belongs to these grid cells.
Detección: Esta arquitectura divide la imagen en una cuadrícula de tamaño S*S . Si el centro del cuadro delimitador del objeto está en esa cuadrícula, entonces esta cuadrícula es responsable de detectar ese objeto. Cada cuadrícula predice cuadros delimitadores con su puntuación de confianza. Cada puntaje de confianza muestra qué tan preciso es que el cuadro delimitador predicho contenga un objeto y qué tan preciso predice las coordenadas del cuadro delimitador wrt. predicción de la verdad del terreno.

Imagen de YOLO (dividida en cuadrícula S*S)
En el momento de la prueba, multiplicamos las probabilidades de clase condicional y las predicciones de confianza de caja individuales. Definimos nuestra puntuación de confianza de la siguiente manera:

Tenga en cuenta que la puntuación de confianza debe ser 0 cuando no existe ningún objeto en la cuadrícula. Si hay un objeto presente en la imagen, la puntuación de confianza debe ser igual a IoU entre los cuadros reales y predichos. Cada cuadro delimitador consta de 5 predicciones: (x, y, w, h) y puntuación de confianza. Las coordenadas (x, y) representan el centro del cuadro en relación con los límites de la celda de la cuadrícula. Las coordenadas h, w representan la altura y el ancho del cuadro delimitador en relación con (x, y) . La puntuación de confianza representa la presencia de un objeto en el cuadro delimitador.

Cuadro delimitador de rejilla simple YOLO-Caja
Esto da como resultado una combinación de cuadros delimitadores de cada cuadrícula como esta.

Combinación de caja delimitadora YOLO
Cada cuadrícula también predice la probabilidad de clase condicional C, P r (Clase i | Objeto).

Mapa de probabilidad condicional de YOLO
Esta probabilidad estaba condicionada a la presencia de un objeto en la celda de la cuadrícula. Independientemente del número de casillas, cada celda de la cuadrícula predice solo un conjunto de probabilidades de clase. Estas predicciones están codificadas en el tensor 3D de tamaño S * S * (5*B +C).
Ahora, multiplicamos las probabilidades de clase condicional y las predicciones de confianza de caja individual,

Mapa de funciones de salida de YOLO


Resultado de la prueba YOLO
lo que nos da puntuaciones de confianza específicas de la clase para cada casilla. Estos puntajes codifican tanto la probabilidad de que esa clase aparezca en el cuadro como qué tan bien el cuadro predicho se ajusta al objeto. Luego, después de aplicar la supresión no máxima para suprimir las salidas no máximas (cuando se predice una cantidad de cuadros para el mismo objeto). Y por fin, se generan nuestras predicciones finales.
YOLO es muy rápido en el momento de la prueba porque utiliza una sola arquitectura CNN para predecir los resultados y la clase se define de tal manera que trata la clasificación como un problema de regresión.
Resultados: El YOLO simple tiene un mAP (precisión media media) del 63,4 % cuando se entrenó en VOC en 2007 y 2012, el YOLO rápido, que es casi 3 veces más rápido en la generación de resultados, tiene un mAP del 52 %. Esto es más bajo que el mejor modelo Fast R-CNN logrado (71 % mAP) y también el R-CNN logrado (66 % mAP) . Sin embargo, supera a otros detectores en tiempo real como (DPMv5 33% mAP) en precisión.
Beneficios de YOLO:
- Procese fotogramas a una velocidad de 45 fps (red más grande) a 150 fps (red más pequeña), que es mejor que en tiempo real.
- La red es capaz de generalizar mejor la imagen.
Desventajas de YOLO:
- Recuperación comparativamente baja y más error de localización en comparación con Faster R_CNN.
- Tiene dificultades para detectar objetos cercanos porque cada cuadrícula puede proponer solo 2 cuadros delimitadores.
- Tiene dificultades para detectar objetos pequeños.
Mejoras: el concepto de cuadros de anclaje se ha introducido en los modelos YOLO avanzados que ayudan a predecir varios objetos en la misma celda de cuadrícula y los objetos con diferentes alineaciones.