¿Qué es el Aprendizaje Activo?
El aprendizaje activo es un caso especial de aprendizaje automático supervisado. Este enfoque se utiliza para construir un clasificador de alto rendimiento manteniendo al mínimo el tamaño del conjunto de datos de entrenamiento mediante la selección activa de los puntos de datos valiosos.
¿Dónde debemos aplicar el aprendizaje activo?
- Tenemos una cantidad muy pequeña o una gran cantidad de conjuntos de datos.
- La anotación del conjunto de datos sin etiqueta cuesta esfuerzo humano, tiempo y dinero.
- Tenemos acceso a un poder de procesamiento limitado.
Ejemplo
En cierto planeta, hay varias frutas de diferentes tamaños (1-5), algunas de ellas son venenosas y otras no. El único criterio para decidir que una fruta es venenosa o no es su tamaño. nuestra tarea es entrenar un clasificador que prediga que la fruta dada es venenosa o no. La única información que tenemos es que una fruta con tamaño 1 no es venenosa, la fruta de tamaño 5 es venenosa y después de un tamaño particular, todas las frutas son venenosas.

El primer enfoque es verificar todos y cada uno de los tamaños de la fruta, lo que consume tiempo y recursos.
El segundo enfoque es aplicar la búsqueda binaria y encontrar el punto de transición (límite de decisión). Este enfoque utiliza menos datos y da los mismos resultados que la búsqueda lineal.
General Algorithm : 1. train classifier with the initial training dataset 2. calculate the accuracy 3. while(accuracy < desired accuracy): 4. select the most valuable data points (in general points close to decision boundary) 5. query that data point/s (ask for a label) from human oracle 6. add that data point/s to our initial training dataset 7. re-train the model 8. re-calculate the accuracy
Enfoques Algoritmo de aprendizaje activo
1. Síntesis de consultas
- Generalmente, este enfoque se usa cuando tenemos un conjunto de datos muy pequeño.
- En este enfoque, elegimos cualquier punto incierto del espacio n-dimensional dado. no nos importa la existencia de ese punto.
En esta consulta, la síntesis puede seleccionar cualquier punto (valioso) del plano 2-D 3*3.
- A veces sería difícil para el oráculo humano anotar el punto de datos consultado.
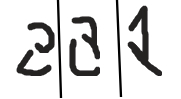
Estas son algunas consultas generadas por el enfoque de síntesis de consulta para un modelo entrenado para el reconocimiento de escritura a mano. Es muy difícil anotar estas consultas.
2. Muestreo
- Este enfoque se utiliza cuando tenemos un gran conjunto de datos.
- En este enfoque, dividimos nuestro conjunto de datos en tres partes: Conjunto de entrenamiento; Equipo de prueba; Pool sin etiquetar (irónico) [5%; 25%, 70%].
- Este conjunto de datos de entrenamiento es nuestro conjunto de datos inicial y se usa para entrenar inicialmente nuestro modelo.
- Este enfoque selecciona puntos valiosos/inciertos de este grupo sin etiquetar, lo que garantiza que Oracle humano pueda reconocer toda la consulta.
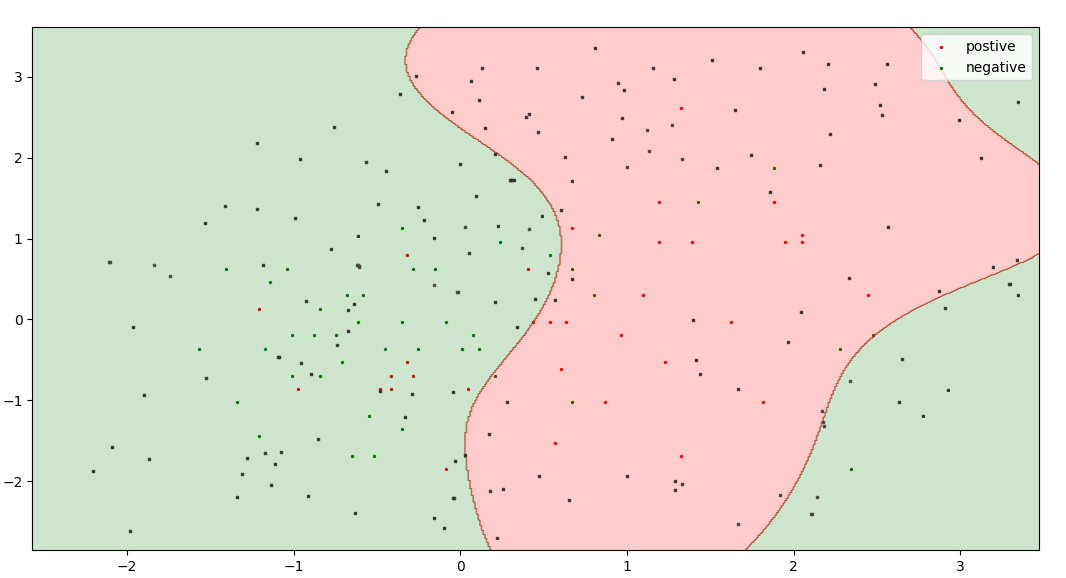
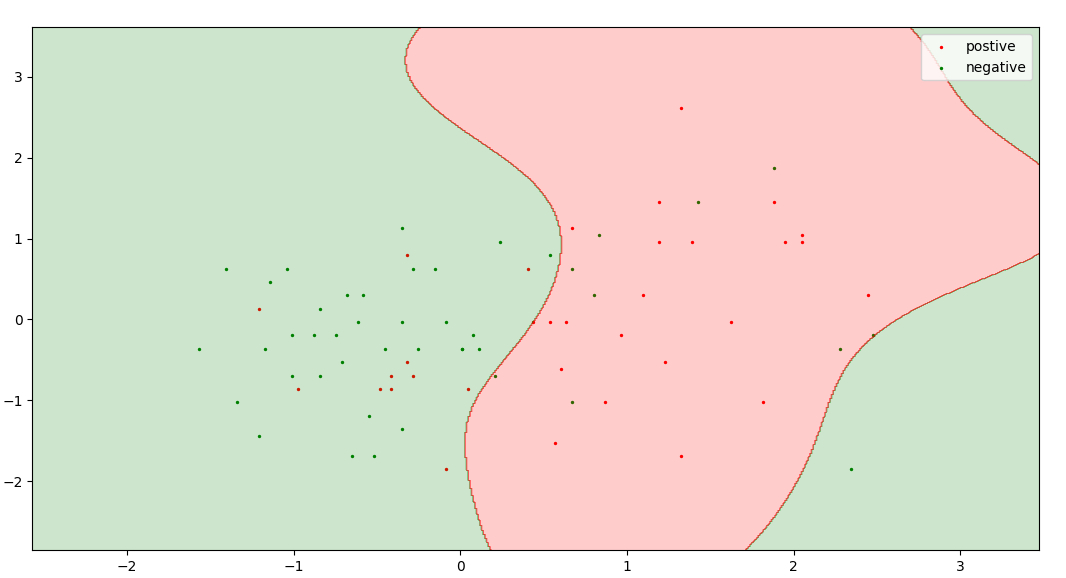
Los puntos negros representan un grupo sin etiquetar y los puntos de color rojo y verde representan un conjunto de datos de entrenamiento.
Aquí hay un modelo de aprendizaje activo que decide puntos valiosos sobre la base de la probabilidad de un punto presente en una clase. En la regresión logística, los puntos más cercanos al umbral (es decir, probabilidad = 0,5) es el punto más incierto. Entonces, elijo la probabilidad entre 0,47 y 0,53 como rango de incertidumbre.
Puede descargar el conjunto de datos desde aquí .
Python3
import numpy as np
import pandas as pd
from statistics import mean
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# split dataset into test set, train set and unlabel pool
def split(dataset, train_size, test_size):
x = dataset[:, :-1]
y = dataset[:, -1]
x_train, x_pool, y_train, y_pool = train_test_split(
x, y, train_size = train_size)
unlabel, x_test, label, y_test = train_test_split(
x_pool, y_pool, test_size = test_size)
return x_train, y_train, x_test, y_test, unlabel, label
if __name__ == '__main__':
# read dataset
dataset = pd.read_csv("./spambase.csv").values[:, ]
# imputing missing data
imputer = SimpleImputer(missing_values = 0, strategy ="mean")
imputer = imputer.fit(dataset[:, :-1])
dataset[:, :-1] = imputer.transform(dataset[:, :-1])
# feature scaling
sc = StandardScaler()
dataset[:, :-1] = sc.fit_transform(dataset[:, :-1])
# run both models 100 times and take the average of their accuracy
ac1, ac2 = [], [] # arrays to store accuracy of different models
for i in range(100):
# split dataset into train(5 %), test(25 %), unlabel(70 %)
x_train, y_train, x_test, y_test, unlabel, label = split(
dataset, 0.05, 0.25)
# train model by active learning
for i in range(5):
classifier1 = LogisticRegression()
classifier1.fit(x_train, y_train)
y_probab = classifier1.predict_proba(unlabel)[:, 0]
p = 0.47 # range of uncertanity 0.47 to 0.53
uncrt_pt_ind = []
for i in range(unlabel.shape[0]):
if(y_probab[i] >= p and y_probab[i] <= 1-p):
uncrt_pt_ind.append(i)
x_train = np.append(unlabel[uncrt_pt_ind, :], x_train, axis = 0)
y_train = np.append(label[uncrt_pt_ind], y_train)
unlabel = np.delete(unlabel, uncrt_pt_ind, axis = 0)
label = np.delete(label, uncrt_pt_ind)
classifier2 = LogisticRegression()
classifier2.fit(x_train, y_train)
ac1.append(classifier2.score(x_test, y_test))
''' split dataset into train(same as generated by our model),
test(25 %), unlabel(rest) '''
train_size = x_train.shape[0]/dataset.shape[0]
x_train, y_train, x_test, y_test, unlabel, label = split(
dataset, train_size, 0.25)
# train model without active learning
classifier3 = LogisticRegression()
classifier3.fit(x_train, y_train)
ac2.append(classifier3.score(x_test, y_test))
print("Accuracy by active model :", mean(ac1)*100)
print("Accuracy by random sampling :", mean(ac2)*100)
'''
This code is contributed by Raghav Dalmia
https://github.com / raghav-dalmia
'''
Producción:
Accuracy by active model : 80.7 Accuracy by random sampling : 79.5
Existen varios modelos para la selección de los puntos más valiosos. Algunos de ellos son:
- Consulta por comité
- Síntesis de consultas y búsqueda de vecinos más cercanos
- Heurísticas basadas en grandes márgenes
- Heurísticas posteriores basadas en la probabilidad
Publicación traducida automáticamente
Artículo escrito por raghav-dalmia y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA