Las estimaciones como la media, la mediana, la desviación estándar y la varianza son muy útiles en el caso del análisis de datos univariado. Pero en el caso del análisis bivariado (comparación de dos variables) entra en juego la correlación.
La tabla de contingencia es una de las técnicas para explorar dos o incluso más variables. Es básicamente un conteo de conteos entre dos o más variables categóricas.
Para obtener los datos del préstamo, haga clic aquí .
Cargando bibliotecas
import numpy as np import pandas as pd import matplotlib as plt
Cargando datos
data = pd.read_csv("loan_status.csv")
print (data.head(10))
Producción: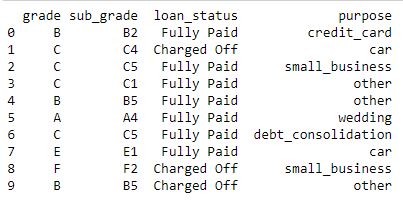
Describir datos
data.describe()
Producción: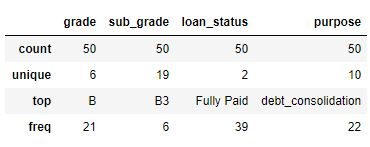
Información de datos
data.info()
Producción:
Tipos de datos
# data types of feature/attributes # in the data data.dtypes
Producción: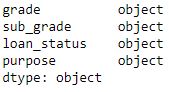
Código #1: Tabla de contingencia que muestra la correlación entre las calificaciones y el estado del préstamo.
data_crosstab = pd.crosstab(data['grade'], data['loan_status'], margins = False) print(data_crosstab)
Producción: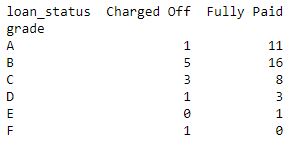
Código #2: Tabla de contingencia que muestra la correlación entre el Propósito y el estado del préstamo.
data_crosstab = pd.crosstab(data['purpose'], data['loan_status'], margins = False) print(data_crosstab)
Producción: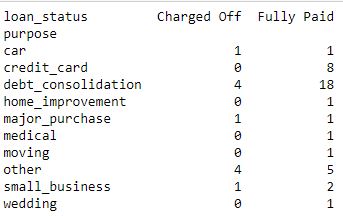
Código #3: Tabla de contingencia que muestra la correlación entre Grados+Propósito y el estado del préstamo.
data_crosstab = pd.crosstab([data.grade, data.purpose], data.loan_status, margins = False) print(data_crosstab)
Producción: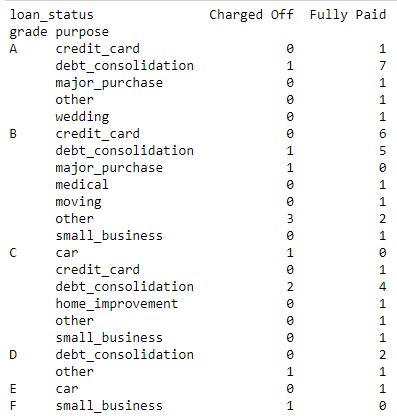
Entonces, como en el código, las tablas de contingencia brindan valores de correlación claros entre dos o más variables. Por lo tanto, es mucho más útil comprender los datos para una mayor extracción de información.
.
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA