Requisitos previos: regresión lineal
Predicción de lluvia es la aplicación de la ciencia y la tecnología para predecir la cantidad de lluvia en una región. Es importante determinar con exactitud las precipitaciones para un uso eficaz de los recursos hídricos, la productividad de los cultivos y la planificación previa de las estructuras hídricas.
En este artículo, utilizaremos la regresión lineal para predecir la cantidad de lluvia. La regresión lineal nos dice cuántas pulgadas de lluvia podemos esperar.
El conjunto de datos es un conjunto de datos meteorológicos públicos de Austin, Texas, disponible en Kaggle. El conjunto de datos se puede encontrar aquí .
Limpieza de datos:
los datos vienen en todas las formas, la mayoría de los cuales son muy desordenados y desestructurados. Rara vez vienen listos para usar. Los conjuntos de datos, grandes y pequeños, vienen con una variedad de problemas: campos no válidos, valores faltantes y adicionales, y valores que están en formas diferentes a las que requerimos. Para llevarlo a una forma viable o estructurada, necesitamos «limpiar» nuestros datos y dejarlos listos para usar. Algunas limpiezas comunes incluyen el análisis, la conversión a one-hot, la eliminación de datos innecesarios, etc.
En nuestro caso, nuestros datos tienen algunos días en los que no se registraron algunos factores. Y la precipitación en cm se marcó como T si hubo trazas de precipitación. Nuestro algoritmo requiere números, por lo que no podemos trabajar con alfabetos que aparecen en nuestros datos. entonces necesitamos limpiar los datos antes de aplicarlos en nuestro modelo
Limpiando los datos en Python:
# importing libraries
import pandas as pd
import numpy as np
# read the data in a pandas dataframe
data = pd.read_csv("austin_weather.csv")
# drop or delete the unnecessary columns in the data.
data = data.drop(['Events', 'Date', 'SeaLevelPressureHighInches',
'SeaLevelPressureLowInches'], axis = 1)
# some values have 'T' which denotes trace rainfall
# we need to replace all occurrences of T with 0
# so that we can use the data in our model
data = data.replace('T', 0.0)
# the data also contains '-' which indicates no
# or NIL. This means that data is not available
# we need to replace these values as well.
data = data.replace('-', 0.0)
# save the data in a csv file
data.to_csv('austin_final.csv')
Una vez que se limpian los datos, se pueden utilizar como entrada para nuestro modelo de regresión lineal. La regresión lineal es un enfoque lineal para formar una relación entre una variable dependiente y muchas variables explicativas independientes. Esto se hace trazando una línea que se ajuste mejor a nuestro diagrama de dispersión, es decir, con la menor cantidad de errores. Esto da predicciones de valor, es decir, cuánto, sustituyendo los valores independientes en la ecuación de la línea.
Usaremos el modelo de regresión lineal de Scikit-learn para entrenar nuestro conjunto de datos. Una vez que se entrena el modelo, podemos proporcionar nuestras propias entradas para las distintas columnas, como temperatura, punto de rocío, presión, etc., para predecir el clima en función de estos atributos.
# importing libraries
import pandas as pd
import numpy as np
import sklearn as sk
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
# read the cleaned data
data = pd.read_csv("austin_final.csv")
# the features or the 'x' values of the data
# these columns are used to train the model
# the last column, i.e, precipitation column
# will serve as the label
X = data.drop(['PrecipitationSumInches'], axis = 1)
# the output or the label.
Y = data['PrecipitationSumInches']
# reshaping it into a 2-D vector
Y = Y.values.reshape(-1, 1)
# consider a random day in the dataset
# we shall plot a graph and observe this
# day
day_index = 798
days = [i for i in range(Y.size)]
# initialize a linear regression classifier
clf = LinearRegression()
# train the classifier with our
# input data.
clf.fit(X, Y)
# give a sample input to test our model
# this is a 2-D vector that contains values
# for each column in the dataset.
inp = np.array([[74], [60], [45], [67], [49], [43], [33], [45],
[57], [29.68], [10], [7], [2], [0], [20], [4], [31]])
inp = inp.reshape(1, -1)
# print the output.
print('The precipitation in inches for the input is:', clf.predict(inp))
# plot a graph of the precipitation levels
# versus the total number of days.
# one day, which is in red, is
# tracked here. It has a precipitation
# of approx. 2 inches.
print("the precipitation trend graph: ")
plt.scatter(days, Y, color = 'g')
plt.scatter(days[day_index], Y[day_index], color ='r')
plt.title("Precipitation level")
plt.xlabel("Days")
plt.ylabel("Precipitation in inches")
plt.show()
x_vis = X.filter(['TempAvgF', 'DewPointAvgF', 'HumidityAvgPercent',
'SeaLevelPressureAvgInches', 'VisibilityAvgMiles',
'WindAvgMPH'], axis = 1)
# plot a graph with a few features (x values)
# against the precipitation or rainfall to observe
# the trends
print("Precipitation vs selected attributes graph: ")
for i in range(x_vis.columns.size):
plt.subplot(3, 2, i + 1)
plt.scatter(days, x_vis[x_vis.columns.values[i][:100]],
color = 'g')
plt.scatter(days[day_index],
x_vis[x_vis.columns.values[i]][day_index],
color ='r')
plt.title(x_vis.columns.values[i])
plt.show()
Producción :
The precipitation in inches for the input is: [[1.33868402]] The precipitation trend graph:
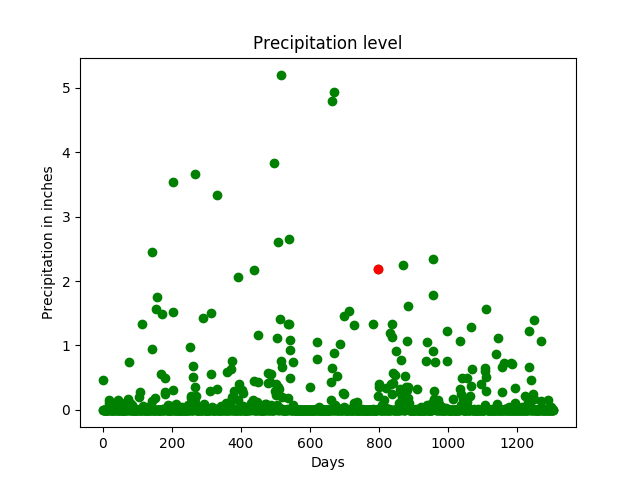
Gráfico de precipitación vs atributos seleccionados: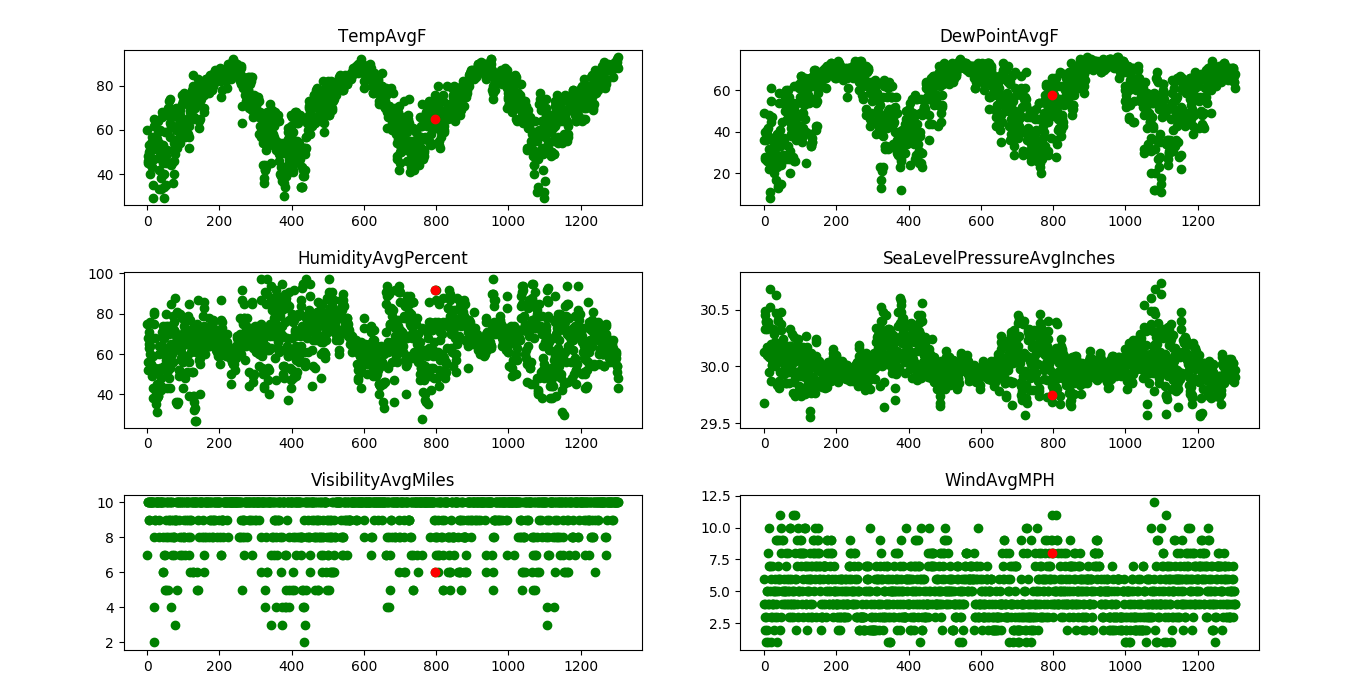
Un día (en rojo) que tiene una precipitación de aproximadamente 2 pulgadas se rastrea a través de múltiples parámetros (el mismo día se rastrea a través de múltiples características como temperatura, presión, etc.). El eje x indica los días y el eje y indica la magnitud de la característica, como la temperatura, la presión, etc. A partir del gráfico, se puede observar que se puede esperar que la precipitación sea alta cuando la temperatura es alta y la humedad es baja. alto.
Publicación traducida automáticamente
Artículo escrito por Adith Bharadwaj y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA