Requisito previo: escalado de características | Conjunto-1 , Conjunto-2
El escalado de características es uno de los pasos más importantes del preprocesamiento de datos. Se aplica a variables independientes o características de los datos. Los datos a veces contienen características con magnitudes variables y si no las tratamos, los algoritmos solo toman en cuenta la magnitud de estas características, descuidando las unidades. Ayuda a normalizar los datos en un rango particular y, a veces, también ayuda a acelerar los cálculos en un algoritmo.
Escalador robusto:
Esto utiliza un método similar al escalador Min-Max, pero en su lugar utiliza el rango intercuartílico, en lugar del mínimo-máximo, por lo que es resistente a los valores atípicos. Este escalador elimina la mediana y escala los datos de acuerdo con el rango de cuantiles (el valor predeterminado es IQR: rango intercuartílico). El IQR es el rango entre el primer cuartil (cuartil 25) y el tercer cuartil (cuartil 75).
Se utiliza la siguiente fórmula: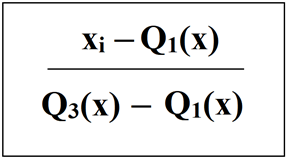
Algunas propiedades más de Robust Scaler son:
- Escalador robusto como media 0 y varianza unitaria
- Robust Scaler no tiene un rango predeterminado, a diferencia de Min-Max Scaler
- Robust Scaler utiliza rangos de cuartiles y esto lo hace menos sensible a los valores atípicos
Código:
# Python code for Feature Scaling using Robust Scaling
""" PART 1: Importing Libraries """
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns % matplotlib inline
matplotlib.style.use('ggplot')
""" PART 2: Making the data distributions """
x = pd.DataFrame({
# Distribution with lower outliers
'x1': np.concatenate([np.random.normal(20, 1, 2000), np.random.normal(1, 1, 20)]),
# Distribution with higher outliers
'x2': np.concatenate([np.random.normal(30, 1, 2000), np.random.normal(50, 1, 20)]),
})
""" PART 3: Scaling the Data """
scaler = preprocessing.RobustScaler()
robust_scaled_df = scaler.fit_transform(x)
robust_scaled_df = pd.DataFrame(robust_scaled_df, columns =['x1', 'x2'])
""" PART 4: Visualizing the impact of scaling """
fig, (ax1, ax2, ax3) = plt.subplots(ncols = 3, figsize =(9, 5))
ax1.set_title('Before Scaling')
sns.kdeplot(x['x1'], ax = ax1)
sns.kdeplot(x['x2'], ax = ax1)
ax2.set_title('After Robust Scaling')
sns.kdeplot(robust_scaled_df['x1'], ax = ax2)
sns.kdeplot(robust_scaled_df['x2'], ax = ax2)
Salida: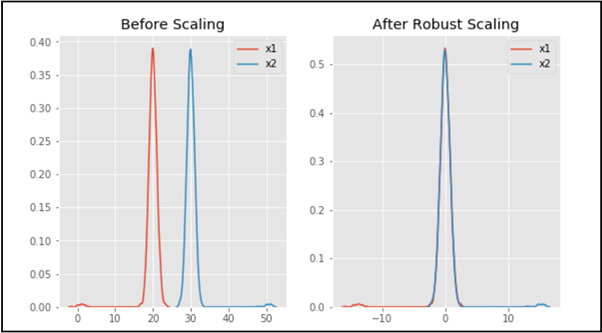
como puede ver en la salida, después del escalado robusto, las distribuciones se colocan en la misma escala y se superponen, pero los valores atípicos permanecen fuera del grueso de las nuevas distribuciones. Por lo tanto, el escalado robusto es un método eficaz para escalar los datos.