Aprendizaje reforzado :
El aprendizaje por refuerzo es un tipo de aprendizaje automático. Permite que las máquinas y los agentes de software determinen automáticamente el comportamiento ideal dentro de un contexto específico, para maximizar su rendimiento. Se requiere una retroalimentación de recompensa simple para que el agente aprenda su comportamiento; esto se conoce como la señal de refuerzo.
Hay muchos algoritmos diferentes que abordan este problema. De hecho, el Aprendizaje por Refuerzo se define por un tipo específico de problema, y todas sus soluciones se clasifican como algoritmos de Aprendizaje por Refuerzo. En el problema, se supone que un agente debe decidir la mejor acción para seleccionar en función de su estado actual. Cuando se repite este paso, el problema se conoce como Proceso de Decisión de Markov .
Un modelo de proceso de decisión de Markov (MDP) contiene:
- Un conjunto de posibles estados del mundo S.
- Un conjunto de modelos.
- Un conjunto de acciones posibles A.
- Una función de recompensa de valor real R(s,a).
- Una política la solución del Proceso de Decisión de Markov .
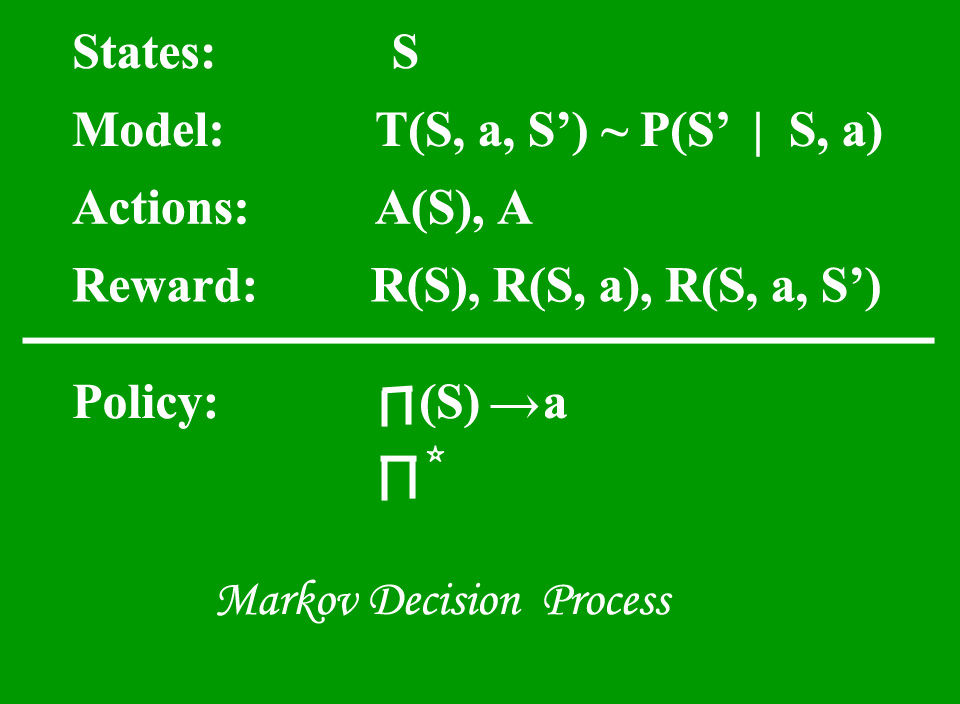
¿Qué es un Estado?
Un estado es un conjunto de tokens que representan todos los estados en los que puede estar el agente.
¿Qué es un modelo?
Un Modelo (a veces llamado Modelo de Transición) da el efecto de una acción en un estado. En particular, T(S, a, S’) define una transición T donde estar en el estado S y realizar una acción ‘a’ nos lleva al estado S’ (S y S’ pueden ser lo mismo). Para acciones estocásticas (ruidosas, no deterministas) también definimos una probabilidad P(S’|S,a) que representa la probabilidad de alcanzar un estado S’ si la acción ‘a’ se realiza en el estado S. Tenga en cuenta que la propiedad de Markov establece que los efectos de una acción realizada en un estado dependen sólo de ese estado y no de la historia previa.
¿Qué son las Acciones?
Una Acción A es un conjunto de todas las acciones posibles. A(s) define el conjunto de acciones que se pueden realizar estando en el estado S.
¿Qué es una recompensa?
Una recompensa es una función de recompensa de valor real. R(s) indica la recompensa por estar simplemente en el estado S. R(S,a) indica la recompensa por estar en un estado S y realizar una acción ‘a’. R(S,a,S’) indica la recompensa por estar en un estado S, realizar una acción ‘a’ y terminar en un estado S’.
¿Qué es una póliza?
Una política es una solución al proceso de decisión de Markov. Una política es un mapeo de S a a. Indica la acción ‘a’ que se debe realizar en el estado S.
Tomemos el ejemplo de un mundo de cuadrícula:
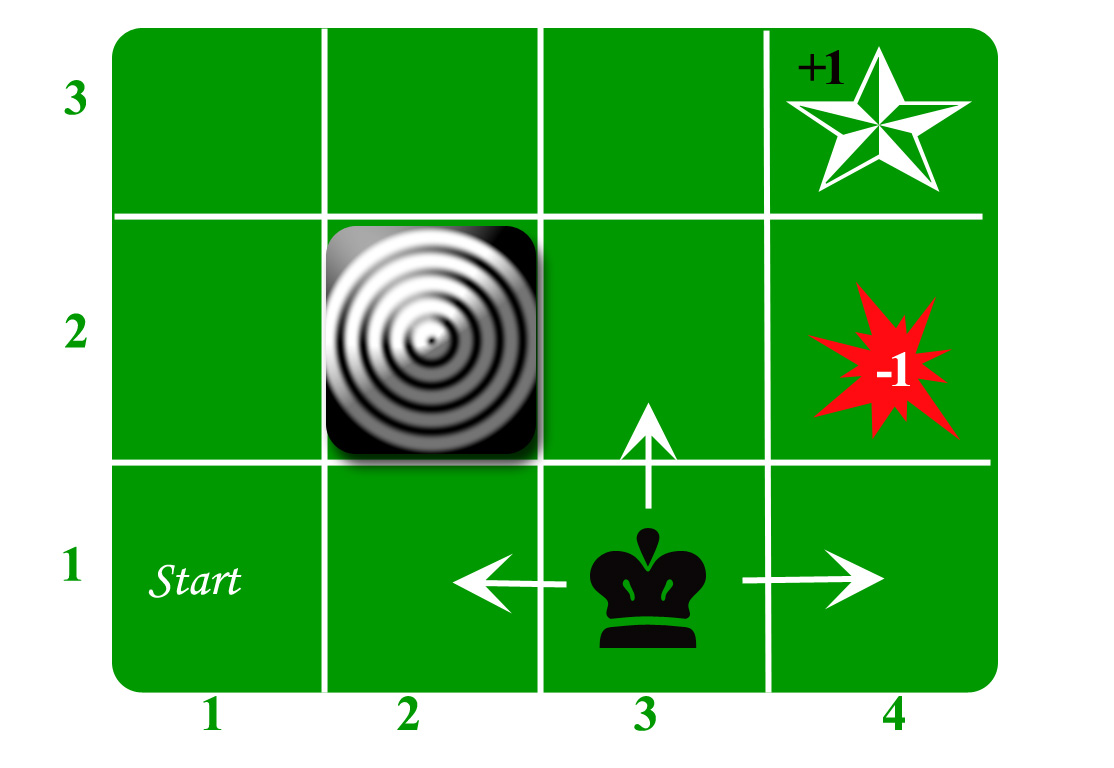
Un agente vive en la red. El ejemplo anterior es una cuadrícula de 3*4. La cuadrícula tiene un estado INICIO (cuadrícula no 1,1). El propósito del agente es deambular por la cuadrícula para finalmente llegar al Diamante Azul (cuadrícula n.° 4,3). En todas las circunstancias, el agente debe evitar la cuadrícula de Incendio (color naranja, cuadrícula n.° 4,2). Además, la cuadrícula n.º 2,2 es una cuadrícula bloqueada, actúa como un muro, por lo que el agente no puede ingresar.
El agente puede realizar cualquiera de estas acciones: ARRIBA, ABAJO, IZQUIERDA, DERECHA
Los muros bloquean el camino del agente, es decir, si hay un muro en la dirección que habría tomado el agente, el agente permanece en el mismo lugar. Entonces, por ejemplo, si el agente dice IZQUIERDA en la cuadrícula de INICIO, permanecerá en la cuadrícula de INICIO.
Primer objetivo: encontrar la secuencia más corta desde INICIO hasta el diamante. Se pueden encontrar dos secuencias de este tipo:
- DERECHA DERECHA ARRIBA DERECHA
- ARRIBA ARRIBA DERECHA DERECHA DERECHA
Tomemos el segundo (ARRIBA ARRIBA DERECHA DERECHA DERECHA) para la discusión posterior.
El movimiento ahora es ruidoso. El 80% de las veces la acción prevista funciona correctamente. El 20% del tiempo que tarda el agente de acción hace que se mueva en ángulo recto. Por ejemplo, si el agente dice ARRIBA, la probabilidad de ir ARRIBA es 0,8, mientras que la probabilidad de ir A LA IZQUIERDA es 0,1 y la probabilidad de ir a la DERECHA es 0,1 (ya que IZQUIERDA y DERECHA son ángulos rectos de ARRIBA).
El agente recibe recompensas cada paso de tiempo: –
- Pequeña recompensa en cada paso (puede ser negativo cuando también puede ser término como castigo, en el ejemplo anterior entrar en el Fuego puede tener una recompensa de -1).
- Las grandes recompensas vienen al final (buenas o malas).
- El objetivo es maximizar la suma de recompensas.
Referencias: http://reinforcementlearning.ai-depot.com/
http://artint.info/html/ArtInt_224.html
Publicación traducida automáticamente
Artículo escrito por Abhishek Sharma 44 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA