XGBoostes una implementación de árboles de decisión Gradient Boost. Esta biblioteca fue escrita en C++. Es un tipo de biblioteca de software que fue diseñada básicamente para mejorar la velocidad y el rendimiento del modelo. Recientemente ha sido dominante en el aprendizaje automático aplicado. Los modelos XGBoost dominan en gran medida en muchas competiciones de Kaggle. En este algoritmo, los árboles de decisión se crean en forma secuencial. Los pesos juegan un papel importante en XGBoost. Se asignan pesos a todas las variables independientes que luego se introducen en el árbol de decisión que predice los resultados. El peso de las variables predichas incorrectamente por el árbol aumenta y las variables luego se alimentan al segundo árbol de decisión. Estos clasificadores/predictores individuales luego se agrupan para dar un modelo fuerte y más preciso. Puede funcionar en problemas de regresión, clasificación, clasificación y predicción definida por el usuario.
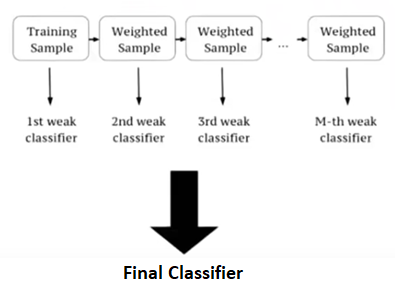
Características de XGBoost La biblioteca está enfocada con láser en la velocidad computacional y el rendimiento del modelo, como tal, hay pocos adornos. Características del modelo Se admiten tres formas principales de aumento de gradiente:
- Aumento de gradiente
- Aumento de gradiente estocástico
- Aumento de gradiente regularizado
características del sistema
- Para el uso de una variedad de entornos informáticos, esta biblioteca proporciona:
- Paralelización de la construcción del árbol.
- Computación distribuida para entrenar modelos muy grandes
- Optimización de caché de estructuras de datos y algoritmo
Mejoras/optimizaciones de XGBoost
XGBoost presenta varias optimizaciones integradas para acelerar el entrenamiento cuando se trabaja con grandes conjuntos de datos, además de su método único de generación y poda de árboles. Aquí hay un puñado de los más significativos:
- Algoritmo codicioso aproximado: en lugar de evaluar cada división candidata, este algoritmo emplea cuantiles ponderados para encontrar la mejor división de Nodes.
- Acceso Cash-Aware: XGBoost almacena datos en la memoria caché de la CPU.
- Sparsity: Aware Split Finding calcula la ganancia colocando observaciones con valores faltantes en la hoja izquierda cuando faltan algunos datos. Luego repite el proceso colocándolos en la hoja apropiada y seleccionando el escenario con la Ganancia más alta.
Pasos para instalar Windows XGBoost usa submódulos de Git para administrar las dependencias. Entonces, cuando clone el repositorio, recuerde especificar la opción recursiva:
git clone --recursive https://github.com/dmlc/xgboost
Para los usuarios de Windows que usan las herramientas de Github, puede abrir el git-shell y escribir el siguiente comando:
git submodule init git submodule update
OSX (Mac) Primero, obtenga gcc-8 con Homebrew ( https://brew.sh/ ) para habilitar subprocesos múltiples (es decir, usar múltiples subprocesos de CPU para entrenamiento). El compilador predeterminado de Apple Clang no es compatible con OpenMP, por lo que usar el compilador predeterminado habría deshabilitado los subprocesos múltiples.
brew install gcc@8
Luego instale XGBoost con pip:
pip3 install xgboost
Es posible que deba ejecutar el comando con el indicador de usuario si se encuentra con errores de permiso.
Ejemplo: Código: código de Python para clasificador XGB
Python3
# Importing the libraries
from sklearn.metrics import confusion_matrix
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Importing the dataset
dataset = pd.read_csv('Churn_Modelling.csv')
X = dataset.iloc[:, 3:13].values
y = dataset.iloc[:, 13].values
# Encoding categorical data
labelencoder_X_1 = LabelEncoder()
X[:, 1] = labelencoder_X_1.fit_transform(X[:, 1])
labelencoder_X_2 = LabelEncoder()
X[:, 2] = labelencoder_X_2.fit_transform(X[:, 2])
onehotencoder = OneHotEncoder(categorical_features=[1])
X = onehotencoder.fit_transform(X).toarray()
X = X[:, 1:]
# Splitting the dataset into the Training set and Test set
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=0)
# Fitting XGBoost to the training data
my_model = xgb.XGBClassifier()
my_model.fit(X_train, y_train)
# Predicting the Test set results
y_pred = my_model.predict(X_test)
# Making the Confusion Matrix
cm = confusion_matrix(y_test, y_pred)
Producción:
Accuracy will be about 0.8645
Publicación traducida automáticamente
Artículo escrito por Prateek_Aggarwal y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA