En el siglo XXI, dos términos » Ciencia de datos » y » Aprendizaje automático » son algunos de los términos más buscados en el mundo de la tecnología. Desde estudiantes de 1er año de Informática hasta grandes Organizaciones como Netflix, Amazon, etc. están detrás de estas dos técnicas. Y también obtuvieron la razón. En el mundo del espacio de datos, la era de Big Data surgió cuando las organizaciones manejan petabytes y exabytes de datos. Se volvió muy difícil para las industrias el almacenamiento de datos hasta 2010. Ahora, cuando los marcos populares como Hadoop y otros resolvieron el problema del almacenamiento, la atención se centra en el procesamiento de los datos. Y aquí la ciencia de datos y el aprendizaje automático juegan un papel importante. Pero, ¿cuántos datos son Big Data?

- Google procesa 20 petabytes (PB) por día (2008)
- Facebook tiene 2,5 PB de datos de usuario + 15 TB por día (2009)
- eBay tiene 6,5 PB de datos de usuario + 50 TB por día (2009)
- El Gran Colisionador de Hadrones (LHC) del CERN genera 15 PB al año
Pero, en general, ¿qué hace que estos dos términos sean diferentes? ¿Cuáles son las grandes diferencias entre estas dos técnicas? Entonces, eliminemos la confusión con un diagrama de Venn simple que es muy popular y se conoce como Diagrama de Venn de Drew Conway . Antes de eso, echemos un vistazo a la definición de estos dos términos.
Ciencia de los datos
Es el estudio complejo de las grandes cantidades de datos en el repositorio de una empresa u organización. Este estudio incluye de dónde se originaron los datos, el estudio real de su contenido y cómo estos datos pueden ser útiles para el crecimiento de la empresa en el futuro. Los datos relativos a una organización siempre se encuentran en dos formas: estructurados o no estructurados . Cuando estudiamos estos datos, obtenemos información valiosa sobre patrones comerciales o de mercado que ayudan a la empresa a tener una ventaja sobre los demás competidores, ya que han aumentado su eficacia al reconocer patrones en el conjunto de datos.
Los científicos de datos son especialistas que se destacan en la conversión de datos sin procesar en asuntos comerciales críticos. Estos científicos son expertos en codificación algorítmica junto con conceptos como minería de datos, aprendizaje automático y estadísticas. La ciencia de datos es utilizada ampliamente por empresas como Amazon, Netflix, el sector de la salud, en el sector de detección de fraudes, búsqueda en Internet, aerolíneas, etc.
Aprendizaje automático
El aprendizaje automático es un campo de estudio que brinda a las computadoras la capacidad de aprender sin ser programadas explícitamente. El aprendizaje automático se aplica utilizando algoritmos para procesar los datos y capacitarse para entregar predicciones futuras sin intervención humana. Las entradas para Machine Learning son el conjunto de instrucciones o datos u observaciones. El aprendizaje automático es utilizado ampliamente por empresas como Facebook, Google, etc.
¿Qué hace que estas dos técnicas sean diferentes?
A continuación se muestra el diagrama de Venn de Drew Conway . Echemos un vistazo al Diagrama de Venn.
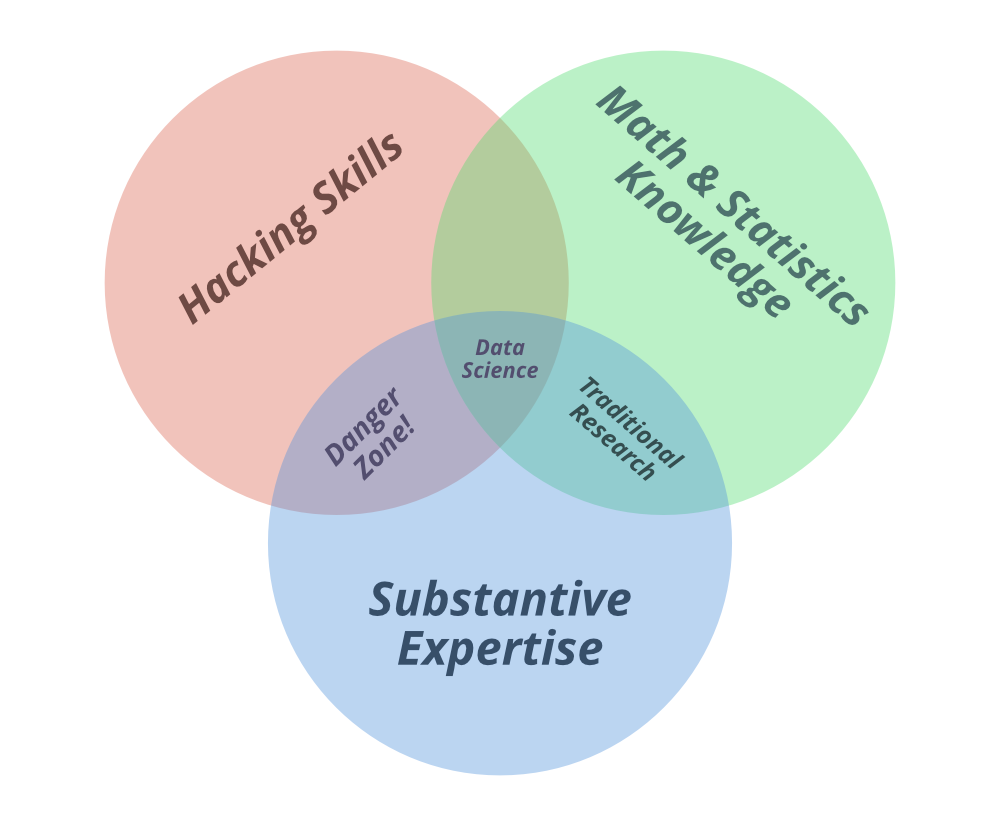
Puede ver los dos términos «Ciencia de datos» y «Aprendizaje automático» en el diagrama de Venn anterior. Así que entendamos el diagrama. En el diagrama de Venn de ciencia de datos de Drew Conway, los colores primarios de los datos son
- Habilidades de pirateo,
- Conocimientos de Matemáticas y Estadística, y
- Experiencia sustantiva
Pero la pregunta es ¿por qué ha resaltado estos tres? ¡Así que entendamos el término por qué!
Habilidades de piratería: todos saben que los datos son la parte clave de la ciencia de datos. Y los datos son una mercancía comercializada electrónicamente; entonces, para estar en este mercado, “ hay que hablar hacker” . Entonces, ¿qué significa esta línea? Ser capaz de administrar archivos de texto en la línea de comandos, aprender operaciones vectorizadas, pensar algorítmicamente; son las habilidades de hacking que hacen que un hacker de datos tenga éxito .
Conocimiento de matemáticas y estadísticas: una vez que haya recopilado y limpiado los datos, el siguiente paso es obtener información de ellos. Para hacer esto, debe usar métodos matemáticos y estadísticos apropiados , que exigen al menos una familiaridad básica con estas herramientas. Esto no quiere decir que un Ph.D. en estadística se requiere ser un científico de datos experto, pero es necesario comprender qué es una regresión de mínimos cuadrados ordinarios y cómo explicarla.
Experiencia Sustantiva: La tercera parte importante es la experiencia Sustantiva. Y aquí es donde nuestra confusión se borra. ¡¡Sí!!
De acuerdo con Drew Conway, » Los datos más el conocimiento matemático y estadístico solo te brindan aprendizaje automático» , lo cual es excelente si eso es lo que te interesa, pero no si estás haciendo ciencia de datos . La ciencia se trata de experimentar y construir conocimiento, lo que exige algunas preguntas motivadoras sobre el mundo e hipótesis que se pueden llevar a los datos y probar con métodos estadísticos.
Y este es el principal punto de diferencia entre estos dos términos. Si desea ser un científico de datos, debe tener conocimiento en ese área de dominio. ¿Pero por qué? El principal objetivo de la ciencia de datos es extraer información útil de esos datos para que pueda ser rentable para el negocio de la empresa. Si no está al tanto del lado comercial de la empresa, de cómo funciona el modelo comercial de la empresa y de cómo no puede construirlo mejor, no es de utilidad para esta empresa. Debe saber cómo hacer las preguntas correctas a las personas adecuadas para que pueda percibir la información adecuada que necesita para obtener la información que necesita. A continuación se muestra una tabla completa de diferencias entre Data Science y Machine Learning.
Tabla de diferencias
|
S.No |
Ciencia de los datos |
Aprendizaje automático |
|---|---|---|
| 1. | Data Science es un campo sobre procesos y sistemas para extraer datos de datos estructurados y semiestructurados. | El aprendizaje automático es un campo de estudio que brinda a las computadoras la capacidad de aprender sin ser programadas explícitamente. |
| 2. | Necesita todo el universo analítico. | Combinación de máquina y ciencia de datos. |
| 3. | Rama que se ocupa de los datos. | Las máquinas utilizan técnicas de ciencia de datos para aprender sobre los datos. |
| 4. | Los datos en Data Science pueden o no evolucionar a partir de una máquina o un proceso mecánico. | Utiliza varias técnicas como la regresión y el agrupamiento supervisado. |
| 5. | Data Science, como un término más amplio, no solo se enfoca en las estadísticas de algoritmos, sino que también se ocupa del procesamiento de datos. | Pero solo se enfoca en estadísticas de algoritmos. |
| 6. | Es un término amplio para múltiples disciplinas. | Encaja dentro de la ciencia de datos. |
| 7. | Muchas operaciones de ciencia de datos, es decir, recopilación de datos, limpieza de datos, manipulación de datos, etc. | Hay tres tipos: aprendizaje no supervisado, aprendizaje por refuerzo, aprendizaje supervisado. |
| 8. | Ejemplo: Netflix utiliza tecnología de ciencia de datos. | Ejemplo: Facebook utiliza tecnología de aprendizaje automático. |
Publicación traducida automáticamente
Artículo escrito por amritanand25 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA