El apilamiento es una forma de ensamblar múltiples clasificaciones o modelos de regresión. Hay muchas formas de ensamblar modelos, los modelos más conocidos son el Bagging o el Boosting . El embolsado permite promediar múltiples modelos similares con una gran variación para disminuir la variación. Boosting construye múltiples modelos incrementales para disminuir el sesgo, mientras mantiene la varianza pequeña.
El apilamiento (a veces llamado generalización apilada ) es un paradigma diferente. El objetivo del apilamiento es explorar un espacio de diferentes modelos para el mismo problema. La idea es que puedes abordar un problema de aprendizaje con diferentes tipos de modelos que son capaces de aprender una parte del problema, pero no todo el espacio del problema. Por lo tanto, puede crear varios alumnos diferentes y usarlos para crear una predicción intermedia, una predicción para cada modelo aprendido. Luego agrega un nuevo modelo que aprende de las predicciones intermedias el mismo objetivo.
Se dice que este modelo final está apilado encima de los demás, de ahí el nombre. Por lo tanto, puede mejorar su rendimiento general y, a menudo, termina con un modelo que es mejor que cualquier modelo intermedio individual. Sin embargo, tenga en cuenta que no le ofrece ninguna garantía, como suele ser el caso con cualquier técnica de aprendizaje automático.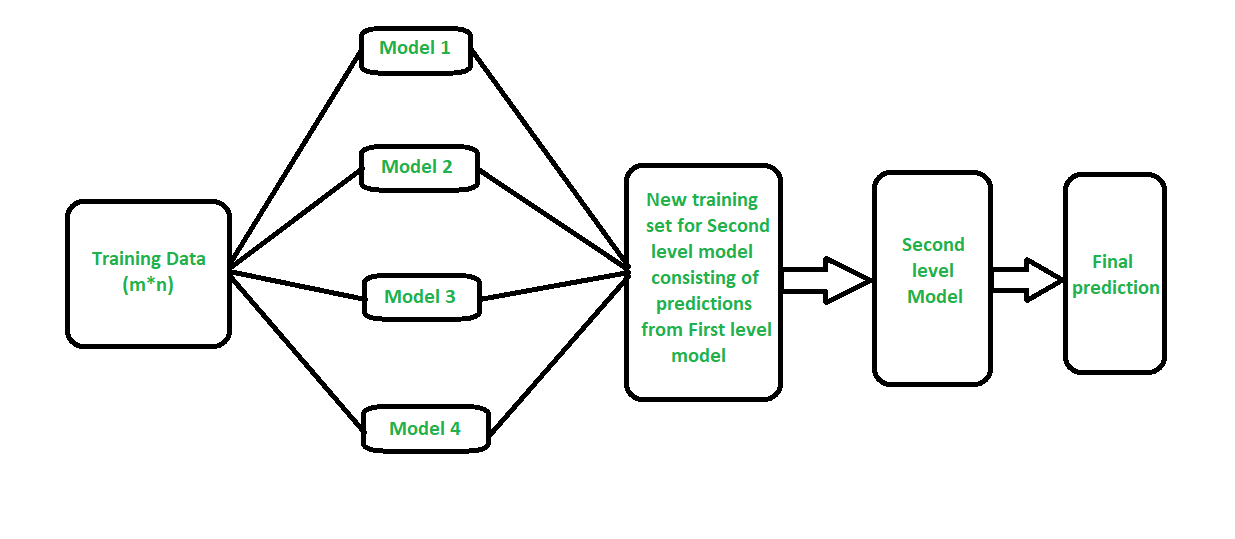
¿Cómo funciona el apilamiento?
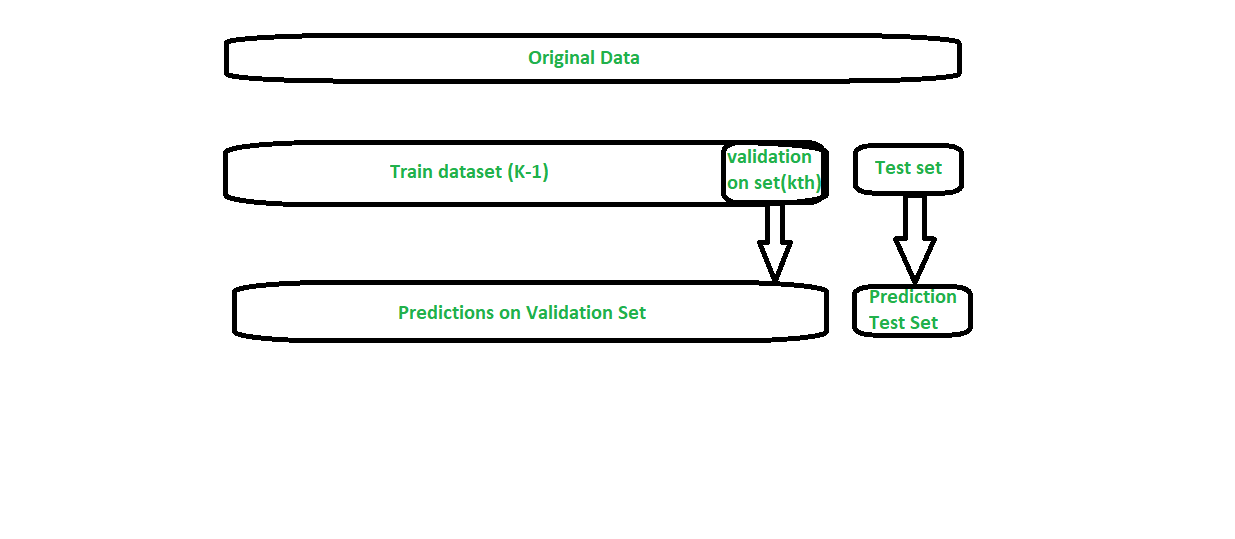
- Dividimos los datos de entrenamiento en K-folds al igual que la validación cruzada de K-fold.
- Se ajusta un modelo base en las partes K-1 y se hacen predicciones para la parte K-ésima.
- Lo hacemos para cada parte de los datos de entrenamiento.
- Luego, el modelo base se ajusta en todo el conjunto de datos del tren para calcular su rendimiento en el conjunto de prueba.
- Repetimos los últimos 3 pasos para otros modelos base.
- Las predicciones del conjunto de trenes se utilizan como características para el modelo de segundo nivel.
- El modelo de segundo nivel se usa para hacer una predicción en el conjunto de prueba.
mezclando –
La mezcla es un enfoque similar al apilamiento.
- El conjunto de trenes se divide en conjuntos de entrenamiento y validación.
- Entrenamos los modelos base en el conjunto de entrenamiento.
- Hacemos predicciones solo en el conjunto de validación y el conjunto de prueba.
- Las predicciones de validación se utilizan como características para construir un nuevo modelo.
- Este modelo se usa para hacer predicciones finales en el conjunto de prueba utilizando los valores de predicción como características.
Publicación traducida automáticamente
Artículo escrito por Avik_Dutta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA