El gráfico de KDE descrito como estimación de la densidad del núcleo se utiliza para visualizar la densidad de probabilidad de una variable continua. Representa la densidad de probabilidad en diferentes valores en una variable continua. También podemos trazar un solo gráfico para múltiples muestras, lo que ayuda a una visualización de datos más eficiente.
En este artículo, usaremos Iris Dataset y KDE Plot para visualizar las perspectivas del conjunto de datos.
Acerca del conjunto de datos de Iris :
- Atributos : Longitud_pétalo (cm), Ancho_pétalo (cm), Longitud_sépalo (cm), Ancho_sépalo(cm)
- Objetivo : Iris_Virginica, Iris_Setosa, Iris_Vercicolor
- Número de instancias : 150
Gráfica KDE unidimensional:
Podemos visualizar la distribución de probabilidad de una muestra frente a un único atributo continuo.
# importing the required libraries
from sklearn import datasets
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# Setting up the Data Frame
iris = datasets.load_iris()
iris_df = pd.DataFrame(iris.data, columns=['Sepal_Length',
'Sepal_Width', 'Patal_Length', 'Petal_Width'])
iris_df['Target'] = iris.target
iris_df['Target'].replace([0], 'Iris_Setosa', inplace=True)
iris_df['Target'].replace([1], 'Iris_Vercicolor', inplace=True)
iris_df['Target'].replace([2], 'Iris_Virginica', inplace=True)
# Plotting the KDE Plot
sns.kdeplot(iris_df.loc[(iris_df['Target']=='Iris_Virginica'),
'Sepal_Length'], color='b', shade=True, Label='Iris_Virginica')
# Setting the X and Y Label
plt.xlabel('Sepal Length')
plt.ylabel('Probability Density')
Producción: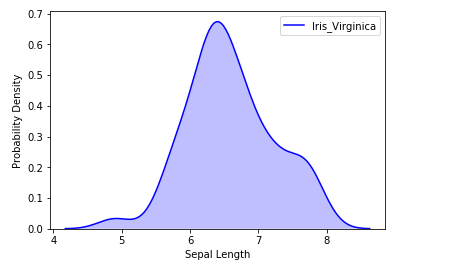
También podemos visualizar la distribución de probabilidad de múltiples muestras en una sola parcela.
# Plotting the KDE Plot
sns.kdeplot(iris_df.loc[(iris_df['Target']=='Iris_Setosa'),
'Sepal_Length'], color='r', shade=True, Label='Iris_Setosa')
sns.kdeplot(iris_df.loc[(iris_df['Target']=='Iris_Virginica'),
'Sepal_Length'], color='b', shade=True, Label='Iris_Virginica')
plt.xlabel('Sepal Length')
plt.ylabel('Probability Density')
Salida: 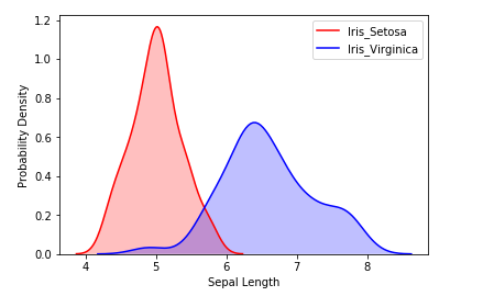
Gráfica bidimensional de KDE:
Podemos visualizar la distribución de probabilidad de una muestra contra múltiples atributos continuos.
# Setting up the samples
iris_setosa = iris_df.query("Target=='Iris_Setosa'")
iris_virginica = iris_df.query("Target=='Iris_Virginica'")
# Plotting the KDE Plot
sns.kdeplot(iris_setosa['Sepal_Length'],
iris_setosa['Sepal_Width'],
color='r', shade=True, Label='Iris_Setosa',
cmap="Reds", shade_lowest=False)
Producción: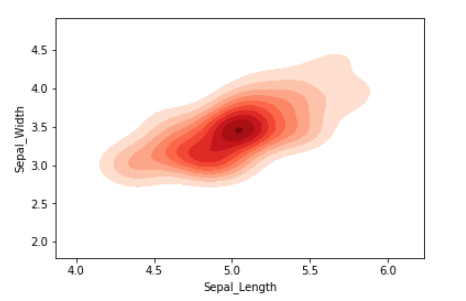
También podemos visualizar la distribución de probabilidad de múltiples muestras en una sola parcela.
# Plotting the KDE Plot sns.kdeplot(iris_setosa['Sepal_Length'], iris_setosa['Sepal_Width'], color='r', shade=True, Label='Iris_Setosa', cmap="Reds", shade_lowest=False) sns.kdeplot(iris_virginica['Sepal_Length'], iris_virginica['Sepal_Width'], color='b', shade=True, Label='Iris_Virginica', cmap="Blues", shade_lowest=False)
Producción: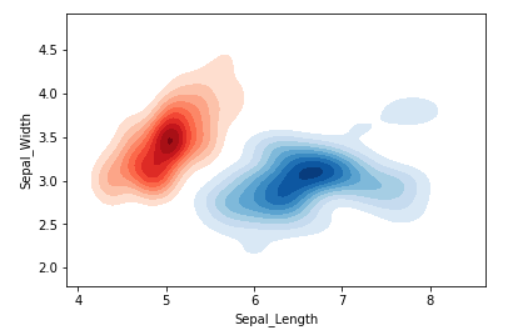
Publicación traducida automáticamente
Artículo escrito por sauravprateek y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA