Desde apps de traducción hasta vehículos autónomos, todas las potencias con Machine Learning. Ofrece una forma de resolver problemas y responder preguntas complejas. Básicamente es un proceso de entrenamiento de una pieza de software llamada algoritmo o modelo, para hacer predicciones útiles a partir de los datos. Este artículo analiza las categorías de problemas de aprendizaje automático y las terminologías utilizadas en el campo del aprendizaje automático.

Tipos de problemas de aprendizaje automático
Hay varias formas de clasificar los problemas de aprendizaje automático. Aquí, discutimos los más obvios.
1. Sobre la base de la naturaleza de la «señal» o «retroalimentación» de aprendizaje disponible para un sistema de aprendizaje
- Aprendizaje supervisado : el modelo o algoritmo se presenta con entradas de ejemplo y sus salidas deseadas y luego encuentra patrones y conexiones entre la entrada y la salida. El objetivo es aprender una regla general que asigna entradas a salidas. El proceso de entrenamiento continúa hasta que el modelo alcanza el nivel deseado de precisión en los datos de entrenamiento. Algunos ejemplos de la vida real son:
- Clasificación de imágenes: Entrenas con imágenes/etiquetas. Luego, en el futuro, das una nueva imagen esperando que la computadora reconozca el nuevo objeto.
- Predicción/regresión del mercado: Entrenas a la computadora con datos históricos del mercado y le pides que prediga el nuevo precio en el futuro.
- Aprendizaje no supervisado : no se asignan etiquetas al algoritmo de aprendizaje, dejándolo solo para encontrar una estructura en su entrada. Se utiliza para agrupar la población en diferentes grupos. El aprendizaje no supervisado puede ser un objetivo en sí mismo (descubrir patrones ocultos en los datos).
- Agrupamiento: Le pides a la computadora que separe datos similares en grupos, esto es esencial en la investigación y la ciencia.
- Visualización de alta dimensión: use la computadora para ayudarnos a visualizar datos de alta dimensión.
- Modelos generativos: después de que un modelo capture la distribución de probabilidad de sus datos de entrada, podrá generar más datos. Esto puede ser muy útil para hacer que su clasificador sea más robusto.
A continuación se muestra un diagrama simple que aclara el concepto de aprendizaje supervisado y no supervisado: 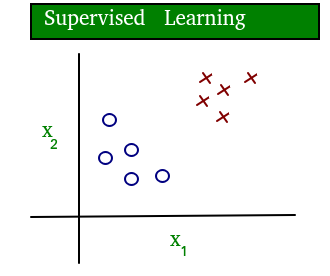
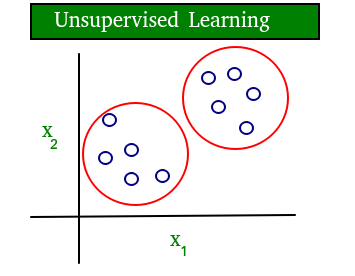
Como puede ver claramente, los datos en el aprendizaje supervisado están etiquetados, mientras que los datos en el aprendizaje no supervisado no están etiquetados.
- Aprendizaje semisupervisado: los problemas en los que tiene una gran cantidad de datos de entrada y solo algunos de los datos están etiquetados se denominan problemas de aprendizaje semisupervisado. Estos problemas se ubican entre el aprendizaje supervisado y el no supervisado. Por ejemplo, un archivo de fotos donde solo algunas de las imágenes están etiquetadas (por ejemplo, perro, gato, persona) y la mayoría no está etiquetada.
- Aprendizaje por refuerzo : un programa de computadora interactúa con un entorno dinámico en el que debe realizar un objetivo determinado (como conducir un vehículo o jugar un juego contra un oponente). El programa recibe retroalimentación en términos de recompensas y castigos a medida que navega por su espacio problemático.
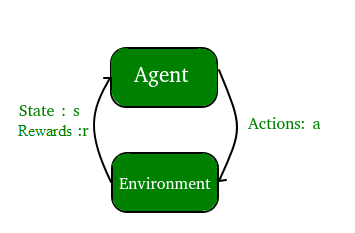
2. Los dos casos de uso más comunes del aprendizaje supervisado son:
- Clasificación : las entradas se dividen en dos o más clases, y el alumno debe producir un modelo que asigne entradas no vistas a una o más (clasificación de etiquetas múltiples) de estas clases y prediga si algo pertenece o no a una clase en particular. Por lo general, esto se aborda de manera supervisada. Los modelos de clasificación se pueden categorizar en dos grupos: Clasificación binaria y Clasificación multiclase. El filtrado de spam es un ejemplo de clasificación binaria, donde las entradas son mensajes de correo electrónico (u otros) y las clases son «spam» y «no spam».
- Regresión : también es un problema de aprendizaje supervisado, que predice un valor numérico y las salidas son continuas en lugar de discretas. Por ejemplo, predecir los precios de las acciones utilizando datos históricos.
A continuación se muestra un ejemplo de clasificación y regresión en dos conjuntos de datos diferentes: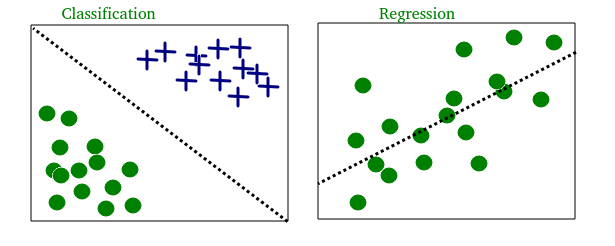
3. Los aprendizajes no supervisados más comunes son:
- Agrupación : aquí, un conjunto de entradas se dividirá en grupos. A diferencia de la clasificación, los grupos no se conocen de antemano, por lo que esta suele ser una tarea sin supervisión. Como puede ver en el siguiente ejemplo, los puntos del conjunto de datos proporcionados se han dividido en grupos identificables por los colores rojo, verde y azul.
- Estimación de densidad : la tarea es encontrar la distribución de entradas en algún espacio.
- Reducción de dimensionalidad : simplifica las entradas al mapearlas en un espacio de menor dimensión. El modelado de temas es un problema relacionado, donde un programa recibe una lista de documentos en lenguaje humano y tiene la tarea de averiguar qué documentos cubren temas similares.
Sobre la base de estas tareas/problemas de aprendizaje automático, tenemos una serie de algoritmos que se utilizan para realizar estas tareas. Algunos algoritmos de aprendizaje automático de uso común son la regresión lineal, la regresión logística, el árbol de decisión, SVM (máquinas de vectores de soporte), Naive Bayes, KNN (K vecinos más cercanos), K-Means, Random Forest, etc. Nota: Se cubrirán todos estos algoritmos en próximos artículos.
Terminologías de aprendizaje automático
- Modelo Un modelo es una representación específica aprendida de los datos mediante la aplicación de algún algoritmo de aprendizaje automático. Un modelo también se llama hipótesis .
- Característica Una característica es una propiedad individual medible de nuestros datos. Un conjunto de características numéricas puede describirse convenientemente mediante un vector de características . Los vectores de características se alimentan como entrada al modelo. Por ejemplo, para predecir una fruta, puede haber características como color, olor, sabor, etc. Nota: Elegir características informativas, discriminatorias e independientes es un paso crucial para algoritmos efectivos. Por lo general, empleamos un extractor de características para extraer las características relevantes de los datos sin procesar.
- Objetivo (Etiqueta) Una variable objetivo o etiqueta es el valor que va a predecir nuestro modelo. Para el ejemplo de la fruta discutido en la sección de características, la etiqueta con cada conjunto de entrada sería el nombre de la fruta como manzana, naranja, plátano, etc.
- Entrenamiento La idea es dar un conjunto de entradas (características) y sus resultados esperados (etiquetas), así que después del entrenamiento, tendremos un modelo (hipótesis) que luego asignará nuevos datos a una de las categorías entrenadas.
- Predicción Una vez que nuestro modelo está listo, se puede alimentar con un conjunto de entradas a las que proporcionará una salida predicha (etiqueta). Pero asegúrese de que si la máquina funciona bien con datos no vistos, solo nosotros podemos decir que la máquina funciona bien.
La figura que se muestra a continuación aclara los conceptos anteriores: 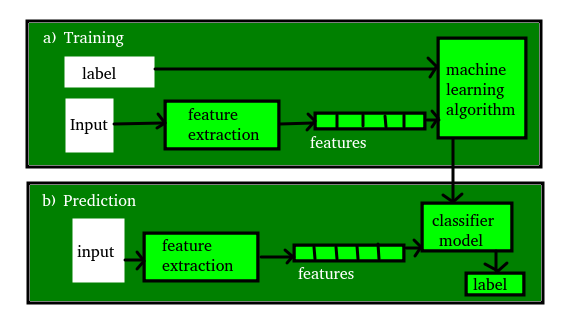 Artículos relacionados:
Artículos relacionados:
Referencias:
- https://en.wikipedia.org/wiki/Machine_learning
- https://leonardoaraujosantos.gitbooks.io/inteligencia-artificial/
- http://machinelearningmastery.com/data-terminology-in-machine-learning/
Este blog es una contribución de Nikhil Kumar . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks. Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Cursos GeeksforGeeks
Aprendizaje automático básico y avanzado: curso a su propio ritmo
Construya sus bases sólidas con nuestro curso de aprendizaje automático a su propio ritmo, con temas como la dimensionalidad de los datos, el manejo de datos, la regresión, la agrupación en clústeres y mucho más. Recuerda, este curso está especialmente diseñado para principiantes, teniendo en cuenta los requisitos básicos. Este curso de aprendizaje automático le enseñará las habilidades que necesita para convertirse en un ingeniero de aprendizaje automático listo para la industria. ¡Inscribirse ahora!
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA