El reconocimiento facial en vivo es un problema que aún enfrenta la división de seguridad automatizada. Con los avances en las redes neuronales de convoluciones y específicamente las formas creativas de Region-CNN, ya se ha confirmado que con nuestras tecnologías actuales, podemos optar por opciones de aprendizaje supervisado como FaceNet, YOLO para un reconocimiento facial rápido y en vivo en un entorno del mundo real. .
Para entrenar un modelo supervisado, necesitamos obtener conjuntos de datos de nuestras etiquetas de destino, lo que sigue siendo una tarea tediosa. Necesitamos una solución eficiente y automatizada para la generación de conjuntos de datos con un mínimo esfuerzo de etiquetado por parte del usuario.
Solución propuesta –
Introducción: Proponemos una canalización de generación de conjuntos de datos que toma un videoclip como fuente y extrae todos los rostros y los agrupa en conjuntos limitados y precisos de imágenes que representan a una persona distinta. Cada conjunto se puede etiquetar fácilmente mediante la entrada humana con facilidad.
Detalles técnicos: Vamos a utilizar opencv lib para la extracción de fotogramas por segundo del videoclip de entrada. 1 segundo parece apropiado para cubrir datos relevantes y marcos limitados para el procesamiento.
Usaremos la biblioteca face_recognition (respaldada por dlib) para extraer las caras de los marcos y alinearlas para la extracción de características.
Luego, extraeremos las características observables por humanos y las agruparemos utilizando el agrupamiento DBSCAN proporcionado por scikit-learn.
Para la solución, recortaremos todas las caras, crearemos etiquetas y las agruparemos en carpetas para que los usuarios las adapten como un conjunto de datos para sus casos de uso de capacitación.
Desafíos en la implementación: para una audiencia más amplia, planeamos implementar la solución para que se ejecute en una CPU en lugar de una GPU NVIDIA. El uso de una GPU NVIDIA puede aumentar la eficiencia de la canalización.
La implementación de la CPU de la extracción de incrustaciones faciales es muy lenta (más de 30 segundos por imagen). Para hacer frente al problema, los implementamos con ejecuciones de canalización paralelas (lo que da como resultado ~13 segundos por imagen) y luego fusionamos sus resultados para realizar más tareas de agrupación. Presentamos tqdm junto con PyPiper para las actualizaciones de progreso y el cambio de tamaño de los fotogramas extraídos del video de entrada para una ejecución fluida de la canalización.
Input: Footage.mp4 Output:
Módulos Python3 requeridos:
os, cv2, numpy, tensorflow, json, re, shutil, time, pickle, pyPiper, tqdm, imutils, face_recognition, dlib, advertencias, sklearn
Sección de fragmentos:
para el contenido del archivo FaceClusteringLibrary.py , que contiene todas las definiciones de clase, a continuación se encuentran los fragmentos y la explicación de su funcionamiento.
La implementación de clase de ResizeUtils proporciona la función rescale_by_height y rescale_by_width.
“rescale_by_width” es una función que toma ‘image’ y ‘target_width’ como entrada. Aumenta/reduce la dimensión de la imagen para que el ancho cumpla con target_width. La altura se calcula automáticamente para que la relación de aspecto permanezca igual. rescale_by_height también es lo mismo, pero en lugar de ancho, apunta a la altura.
Python3
''' The ResizeUtils provides resizing function to keep the aspect ratio intact Credits: AndyP at StackOverflow''' class ResizeUtils: # Given a target height, adjust the image # by calculating the width and resize def rescale_by_height(self, image, target_height, method = cv2.INTER_LANCZOS4): # Rescale `image` to `target_height` # (preserving aspect ratio) w = int(round(target_height * image.shape[1] / image.shape[0])) return (cv2.resize(image, (w, target_height), interpolation = method)) # Given a target width, adjust the image # by calculating the height and resize def rescale_by_width(self, image, target_width, method = cv2.INTER_LANCZOS4): # Rescale `image` to `target_width` # (preserving aspect ratio) h = int(round(target_width * image.shape[0] / image.shape[1])) return (cv2.resize(image, (target_width, h), interpolation = method))
A continuación se muestra la definición de la clase FramesGenerator. Esta clase proporciona funcionalidad para extraer imágenes jpg leyendo el video secuencialmente. Si tomamos un ejemplo de un archivo de video de entrada, puede tener una velocidad de cuadros de ~30 fps. Podemos concluir que por 1 segundo de video, habrá 30 imágenes. Incluso para un video de 2 minutos, la cantidad de imágenes para procesar será 2 * 60 * 30 = 3600. Es una cantidad demasiado alta de imágenes para procesar y puede llevar horas completar el procesamiento de canalización.
Pero viene un hecho más de que las caras y las personas pueden no cambiar en un segundo. Entonces, considerando un video de 2 minutos, generar 30 imágenes por 1 segundo es engorroso y repetitivo de procesar. En cambio, podemos tomar solo 1 instantánea de la imagen en 1 segundo. La implementación de «FramesGenerator» descarga solo 1 imagen por segundo de un videoclip.
Teniendo en cuenta que las imágenes volcadas están sujetas al procesamiento de reconocimiento facial/dlib para la extracción de rostros, tratamos de mantener un umbral de altura no superior a 500 y un ancho limitado a 700. Este límite lo impone la función «AutoResize» que además llama a rescale_by_height o rescale_by_width para reducir el tamaño de la imagen si se alcanzan los límites, pero conserva la relación de aspecto.
Llegando al siguiente fragmento, la función AutoResize intenta imponer un límite a la dimensión de la imagen dada. Si el ancho es superior a 700, lo reducimos para mantener el ancho de 700 y mantener la relación de aspecto. Otro límite establecido aquí es que la altura no debe ser superior a 500.
Python3
# The FramesGenerator extracts image # frames from the given video file # The image frames are resized for # face_recognition / dlib processing class FramesGenerator: def __init__(self, VideoFootageSource): self.VideoFootageSource = VideoFootageSource # Resize the given input to fit in a specified # size for face embeddings extraction def AutoResize(self, frame): resizeUtils = ResizeUtils() height, width, _ = frame.shape if height > 500: frame = resizeUtils.rescale_by_height(frame, 500) self.AutoResize(frame) if width > 700: frame = resizeUtils.rescale_by_width(frame, 700) self.AutoResize(frame) return frame
A continuación se muestra el fragmento de la función GenerateFrames. Consulta los fps para decidir entre cuántos fotogramas se puede volcar 1 imagen. Limpiamos el directorio de salida y comenzamos a iterar a lo largo de los marcos. Antes de descargar cualquier imagen, cambiamos el tamaño de la imagen si alcanza el límite especificado en la función AutoResize.
Python3
# Extract 1 frame from each second from video footage
# and save the frames to a specific folder
def GenerateFrames(self, OutputDirectoryName):
cap = cv2.VideoCapture(self.VideoFootageSource)
_, frame = cap.read()
fps = cap.get(cv2.CAP_PROP_FPS)
TotalFrames = cap.get(cv2.CAP_PROP_FRAME_COUNT)
print("[INFO] Total Frames ", TotalFrames, " @ ", fps, " fps")
print("[INFO] Calculating number of frames per second")
CurrentDirectory = os.path.curdir
OutputDirectoryPath = os.path.join(
CurrentDirectory, OutputDirectoryName)
if os.path.exists(OutputDirectoryPath):
shutil.rmtree(OutputDirectoryPath)
time.sleep(0.5)
os.mkdir(OutputDirectoryPath)
CurrentFrame = 1
fpsCounter = 0
FrameWrittenCount = 1
while CurrentFrame < TotalFrames:
_, frame = cap.read()
if (frame is None):
continue
if fpsCounter > fps:
fpsCounter = 0
frame = self.AutoResize(frame)
filename = "frame_" + str(FrameWrittenCount) + ".jpg"
cv2.imwrite(os.path.join(
OutputDirectoryPath, filename), frame)
FrameWrittenCount += 1
fpsCounter += 1
CurrentFrame += 1
print('[INFO] Frames extracted')
A continuación se muestra el fragmento de la clase FramesProvider. Hereda «Node», que se puede utilizar para construir la canalización de procesamiento de imágenes. Implementamos funciones de «configuración» y «ejecución». Cualquier argumento definido en la función de «configuración» puede tener los parámetros que el constructor esperará como parámetros en el momento de la creación del objeto. Aquí, podemos pasar el parámetro sourcePath al objeto FramesProvider. La función de «configuración» solo se ejecuta una vez. La función «ejecutar» se ejecuta y sigue emitiendo datos llamando a la función de emisión para procesar la canalización hasta que se llama a la función de cierre.
Aquí, en la «configuración», aceptamos sourcePath como argumento e iteramos a través de todos los archivos en el directorio de marcos dado. Cualquiera que sea la extensión del archivo .jpg (que será generado por la clase FrameGenerator), lo agregamos a la lista «filesList».
Durante las llamadas de la función de ejecución, todas las rutas de imágenes jpg de «filesList» se empaquetan con atributos que especifican «id» y «imagePath» únicos como un objeto y se emiten a la canalización para su procesamiento.
Python3
# Following are nodes for pipeline constructions.
# It will create and asynchronously execute threads
# for reading images, extracting facial features and
# storing them independently in different threads
# Keep emitting the filenames into
# the pipeline for processing
class FramesProvider(Node):
def setup(self, sourcePath):
self.sourcePath = sourcePath
self.filesList = []
for item in os.listdir(self.sourcePath):
_, fileExt = os.path.splitext(item)
if fileExt == '.jpg':
self.filesList.append(os.path.join(item))
self.TotalFilesCount = self.size = len(self.filesList)
self.ProcessedFilesCount = self.pos = 0
# Emit each filename in the pipeline for parallel processing
def run(self, data):
if self.ProcessedFilesCount < self.TotalFilesCount:
self.emit({'id': self.ProcessedFilesCount,
'imagePath': os.path.join(self.sourcePath,
self.filesList[self.ProcessedFilesCount])})
self.ProcessedFilesCount += 1
self.pos = self.ProcessedFilesCount
else:
self.close()
A continuación se muestra la implementación de clase de » FaceEncoder » que hereda «Node» y se puede insertar en la canalización de procesamiento de imágenes. En la función de «configuración», aceptamos el valor «detection_method» para que se invoque el reconocedor de rostros «face_recognition/dlib». Puede tener un detector basado en «cnn» o uno basado en «hog».
La función «ejecutar» desempaqueta los datos entrantes en «id» e «imagePath».
Posteriormente, lee la imagen de «imagePath», ejecuta «face_location» definida en la biblioteca «face_recognition/dlib» para recortar la imagen de la cara alineada, que es nuestra región de interés. Una imagen de cara alineada es una imagen recortada rectangular que tiene ojos y labios alineados en una ubicación específica en la imagen (Nota: la implementación puede diferir con otras bibliotecas, por ejemplo, opencv).
Además, llamamos a la función «face_encodings» definida en «face_recognition/dlib» para extraer las incrustaciones faciales de cada cuadro. Estos valores flotantes incorporados pueden ayudarlo a llegar a la ubicación exacta de las características en una imagen de cara alineada.
Definimos la variable «d» como una array de cajas y sus respectivas incrustaciones. Ahora, empaquetamos la «id» y la array de incrustaciones como clave de «codificación» en un objeto y la emitimos a la canalización de procesamiento de imágenes.
Python3
# Encode the face embedding, reference path
# and location and emit to pipeline
class FaceEncoder(Node):
def setup(self, detection_method = 'cnn'):
self.detection_method = detection_method
# detection_method can be cnn or hog
def run(self, data):
id = data['id']
imagePath = data['imagePath']
image = cv2.imread(imagePath)
rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
boxes = face_recognition.face_locations(
rgb, model = self.detection_method)
encodings = face_recognition.face_encodings(rgb, boxes)
d = [{"imagePath": imagePath, "loc": box, "encoding": enc}
for (box, enc) in zip(boxes, encodings)]
self.emit({'id': id, 'encodings': d})
A continuación, se muestra una implementación de DatastoreManager que nuevamente hereda de «Node» y se puede conectar a la canalización de procesamiento de imágenes. El objetivo de la clase es volcar la array de «codificaciones» como archivo pickle y usar el parámetro «id» para nombrar de forma única el archivo pickle. Queremos que la canalización funcione con subprocesos múltiples.
Para aprovechar los subprocesos múltiples para mejorar el rendimiento, debemos separar adecuadamente las tareas asincrónicas y tratar de evitar cualquier necesidad de sincronización. Por lo tanto, para obtener el máximo rendimiento, permitimos que los subprocesos de la canalización escriban los datos en un archivo separado individual de forma independiente sin interferir con ninguna otra operación de subprocesos.
En caso de que esté pensando en cuánto tiempo ahorró, en hardware de desarrollo usado, sin subprocesos múltiples, el tiempo promedio de extracción de incrustaciones fue de ~30 segundos. Después de la canalización de subprocesos múltiples (con 4 subprocesos), disminuyó a ~10 segundos, pero con el costo de un uso elevado de la CPU.
Dado que el subproceso tarda alrededor de ~ 10 segundos, no se producen escrituras frecuentes en el disco y no obstaculiza nuestro rendimiento de subprocesos múltiples.
Otro caso, si está pensando por qué se usa pickle en lugar de la alternativa JSON. La verdad es que JSON es una mejor alternativa a pickle. Pickle es muy inseguro para el almacenamiento y la comunicación de datos. Los pickles se pueden modificar maliciosamente para incrustar códigos ejecutables en Python. Los archivos JSON son legibles por humanos y más rápidos para codificar y decodificar. Lo único en lo que pickle es bueno es en el volcado sin errores de objetos y contenidos de python en archivos binarios.
Dado que no planeamos almacenar ni distribuir los archivos pickle, y para una ejecución sin errores, estamos usando pickle. De lo contrario, se recomienda encarecidamente JSON y otras alternativas.
Python3
# Receive the face embeddings for clustering and # id for naming the distinct filename class DatastoreManager(Node): def setup(self, encodingsOutputPath): self.encodingsOutputPath = encodingsOutputPath def run(self, data): encodings = data['encodings'] id = data['id'] with open(os.path.join(self.encodingsOutputPath, 'encodings_' + str(id) + '.pickle'), 'wb') as f: f.write(pickle.dumps(encodings))
A continuación se muestra la implementación de la clase PickleListCollator. Está diseñado para leer arrays de objetos en varios archivos pickle, combinarlos en una array y volcar la array combinada en un único archivo pickle.
Aquí, solo hay una función GeneratePickle que acepta outputFilepath que especifica el único archivo pickle de salida que contendrá la array fusionada.
Python3
# PicklesListCollator takes multiple pickle # files as input and merges them together # It is made specifically to support use-case # of merging distinct pickle files into one class PicklesListCollator: def __init__(self, picklesInputDirectory): self.picklesInputDirectory = picklesInputDirectory # Here we will list down all the pickles # files generated from multiple threads, # read the list of results append them to a # common list and create another pickle # with combined list as content def GeneratePickle(self, outputFilepath): datastore = [] ListOfPickleFiles = [] for item in os.listdir(self.picklesInputDirectory): _, fileExt = os.path.splitext(item) if fileExt == '.pickle': ListOfPickleFiles.append(os.path.join( self.picklesInputDirectory, item)) for picklePath in ListOfPickleFiles: with open(picklePath, "rb") as f: data = pickle.loads(f.read()) datastore.extend(data) with open(outputFilepath, 'wb') as f: f.write(pickle.dumps(datastore))
La siguiente es la implementación de la clase FaceClusterUtility. Hay un constructor definido que toma «EncodingFilePath» con valor como ruta al archivo pickle fusionado. Leemos la array del archivo pickle e intentamos agruparlos usando la implementación «DBSCAN» en la biblioteca «scikit». A diferencia de k-means, el escaneo DBSCAN no requiere la cantidad de grupos. El número de grupos depende del parámetro de umbral y se calculará automáticamente.
La implementación de DBSCAN se proporciona en «scikit» y también acepta la cantidad de subprocesos para el cálculo.
Aquí, tenemos una función «Cluster», que se invocará para leer los datos de la array del archivo pickle, ejecutar «DBSCAN», imprimir los grupos únicos como caras únicas y devolver las etiquetas. Las etiquetas son valores únicos que representan categorías, que se pueden usar para identificar la categoría de una cara presente en la array. (El contenido de la array proviene del archivo pickle).
Python3
# Face clustering functionality
class FaceClusterUtility:
def __init__(self, EncodingFilePath):
self.EncodingFilePath = EncodingFilePath
# Credits: Arian's pyimagesearch for the clustering code
# Here we are using the sklearn.DBSCAN functionality
# cluster all the facial embeddings to get clusters
# representing distinct people
def Cluster(self):
InputEncodingFile = self.EncodingFilePath
if not (os.path.isfile(InputEncodingFile) and
os.access(InputEncodingFile, os.R_OK)):
print('The input encoding file, ' +
str(InputEncodingFile) +
' does not exists or unreadable')
exit()
NumberOfParallelJobs = -1
# load the serialized face encodings
# + bounding box locations from disk,
# then extract the set of encodings to
# so we can cluster on them
print("[INFO] Loading encodings")
data = pickle.loads(open(InputEncodingFile, "rb").read())
data = np.array(data)
encodings = [d["encoding"] for d in data]
# cluster the embeddings
print("[INFO] Clustering")
clt = DBSCAN(eps = 0.5, metric ="euclidean",
n_jobs = NumberOfParallelJobs)
clt.fit(encodings)
# determine the total number of
# unique faces found in the dataset
labelIDs = np.unique(clt.labels_)
numUniqueFaces = len(np.where(labelIDs > -1)[0])
print("[INFO] # unique faces: {}".format(numUniqueFaces))
return clt.labels_
A continuación se muestra la implementación de la clase TqdmUpdate que hereda de «tqdm». tqdm es una biblioteca de Python que visualiza una barra de progreso en la interfaz de la consola.
Las variables “n” y “total” son reconocidas por “tqdm”. Los valores de estas dos variables se utilizan para calcular el progreso realizado.
Los parámetros «hecho» y «total_size» en la función «actualizar» son valores proporcionados cuando se vinculan al evento de actualización en el marco de la canalización «PyPiper». El super().refresh() invoca la implementación de la función «actualizar» en la clase «tqdm» que visualiza y actualiza la barra de progreso en la consola.
Python3
# Inherit class tqdm for visualization of progress class TqdmUpdate(tqdm): # This function will be passed as progress # callback function. Setting the predefined # variables for auto-updates in visualization def update(self, done, total_size = None): if total_size is not None: self.total = total_size self.n = done super().refresh()
A continuación se muestra la implementación de la clase FaceImageGenerator. Esta clase proporciona funcionalidad para generar un montaje, una imagen de retrato recortada y una anotación para fines de capacitación futura (por ejemplo, Darknet YOLO) a partir de las etiquetas que resultan después de la agrupación.
El constructor espera EncodingFilePath como la ruta del archivo pickle combinado. Se utilizará para cargar todas las codificaciones de rostros. Ahora estamos interesados en el «imagePath» y las coordenadas de la cara para generar la imagen.
La llamada a «GenerateImages» hace el trabajo previsto. Cargamos la array desde el archivo pickle fusionado. Aplicamos la operación única en las etiquetas y hacemos un bucle a lo largo de las etiquetas. Dentro de la iteración de las etiquetas, para cada etiqueta única, enumeramos todos los índices de array que tienen la misma etiqueta actual.
Estos índices de array se iteran nuevamente para procesar cada cara.
Para procesar la cara, usamos el índice para obtener la ruta del archivo de imagen y las coordenadas de la cara.
El archivo de imagen se carga desde la ruta del archivo de imagen. Las coordenadas de la cara se expanden a una forma de retrato (y también nos aseguramos de que no se expanda más que las dimensiones de la imagen) y se recorta y se vuelca al archivo como una imagen de retrato.
Empezamos de nuevo con las coordenadas originales y nos expandimos un poco para crear anotaciones para futuras opciones de entrenamiento supervisado para mejorar las capacidades de reconocimiento.
Para la anotación, solo lo diseñamos para «Darknet YOLO», pero también se puede adaptar para cualquier otro marco. Finalmente, construimos un montaje y lo escribimos en un archivo de imagen.
Python3
class FaceImageGenerator:
def __init__(self, EncodingFilePath):
self.EncodingFilePath = EncodingFilePath
# Here we are creating montages for
# first 25 faces for each distinct face.
# We will also generate images for all
# the distinct faces by using the labels
# from clusters and image url from the
# encodings pickle file.
# The face bounding box is increased a
# little more for training purposes and
# we also created the exact annotation for
# each face image (similar to darknet YOLO)
# to easily adapt the annotation for future
# use in supervised training
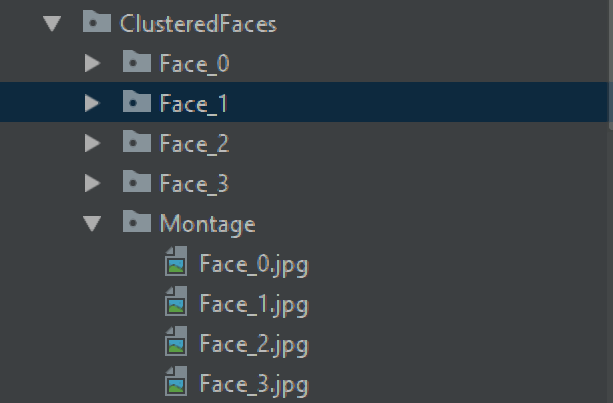
def GenerateImages(self, labels, OutputFolderName = "ClusteredFaces",
MontageOutputFolder = "Montage"):
output_directory = os.getcwd()
OutputFolder = os.path.join(output_directory, OutputFolderName)
if not os.path.exists(OutputFolder):
os.makedirs(OutputFolder)
else:
shutil.rmtree(OutputFolder)
time.sleep(0.5)
os.makedirs(OutputFolder)
MontageFolderPath = os.path.join(OutputFolder, MontageOutputFolder)
os.makedirs(MontageFolderPath)
data = pickle.loads(open(self.EncodingFilePath, "rb").read())
data = np.array(data)
labelIDs = np.unique(labels)
# loop over the unique face integers
for labelID in labelIDs:
# find all indexes into the `data` array
# that belong to the current label ID, then
# randomly sample a maximum of 25 indexes
# from the set
print("[INFO] faces for face ID: {}".format(labelID))
FaceFolder = os.path.join(OutputFolder, "Face_" + str(labelID))
os.makedirs(FaceFolder)
idxs = np.where(labels == labelID)[0]
# initialize the list of faces to
# include in the montage
portraits = []
# loop over the sampled indexes
counter = 1
for i in idxs:
# load the input image and extract the face ROI
image = cv2.imread(data[i]["imagePath"])
(o_top, o_right, o_bottom, o_left) = data[i]["loc"]
height, width, channel = image.shape
widthMargin = 100
heightMargin = 150
top = o_top - heightMargin
if top < 0: top = 0
bottom = o_bottom + heightMargin
if bottom > height: bottom = height
left = o_left - widthMargin
if left < 0: left = 0
right = o_right + widthMargin
if right > width: right = width
portrait = image[top:bottom, left:right]
if len(portraits) < 25:
portraits.append(portrait)
resizeUtils = ResizeUtils()
portrait = resizeUtils.rescale_by_width(portrait, 400)
FaceFilename = "face_" + str(counter) + ".jpg"
FaceImagePath = os.path.join(FaceFolder, FaceFilename)
cv2.imwrite(FaceImagePath, portrait)
widthMargin = 20
heightMargin = 20
top = o_top - heightMargin
if top < 0: top = 0
bottom = o_bottom + heightMargin
if bottom > height: bottom = height
left = o_left - widthMargin
if left < 0: left = 0
right = o_right + widthMargin
if right > width:
right = width
AnnotationFilename = "face_" + str(counter) + ".txt"
AnnotationFilePath = os.path.join(FaceFolder, AnnotationFilename)
f = open(AnnotationFilePath, 'w')
f.write(str(labelID) + ' ' +
str(left) + ' ' + str(top) + ' ' +
str(right) + ' ' + str(bottom) + "\n")
f.close()
counter += 1
montage = build_montages(portraits, (96, 120), (5, 5))[0]
MontageFilenamePath = os.path.join(
MontageFolderPath, "Face_" + str(labelID) + ".jpg")
cv2.imwrite(MontageFilenamePath, montage)
Guarde el archivo como FaceClusteringLibrary.py , que contendrá todas las definiciones de clase.
El siguiente es el archivo Driver.py , que invoca las funcionalidades para crear una canalización.
Python3
# importing all classes from above Python file
from FaceClusteringLibrary import *
if __name__ == "__main__":
# Generate the frames from given video footage
framesGenerator = FramesGenerator("Footage.mp4")
framesGenerator.GenerateFrames("Frames")
# Design and run the face clustering pipeline
CurrentPath = os.getcwd()
FramesDirectory = "Frames"
FramesDirectoryPath = os.path.join(CurrentPath, FramesDirectory)
EncodingsFolder = "Encodings"
EncodingsFolderPath = os.path.join(CurrentPath, EncodingsFolder)
if os.path.exists(EncodingsFolderPath):
shutil.rmtree(EncodingsFolderPath, ignore_errors = True)
time.sleep(0.5)
os.makedirs(EncodingsFolderPath)
pipeline = Pipeline(
FramesProvider("Files source", sourcePath = FramesDirectoryPath) |
FaceEncoder("Encode faces") |
DatastoreManager("Store encoding",
encodingsOutputPath = EncodingsFolderPath),
n_threads = 3, quiet = True)
pbar = TqdmUpdate()
pipeline.run(update_callback = pbar.update)
print()
print('[INFO] Encodings extracted')
# Merge all the encodings pickle files into one
CurrentPath = os.getcwd()
EncodingsInputDirectory = "Encodings"
EncodingsInputDirectoryPath = os.path.join(
CurrentPath, EncodingsInputDirectory)
OutputEncodingPickleFilename = "encodings.pickle"
if os.path.exists(OutputEncodingPickleFilename):
os.remove(OutputEncodingPickleFilename)
picklesListCollator = PicklesListCollator(
EncodingsInputDirectoryPath)
picklesListCollator.GeneratePickle(
OutputEncodingPickleFilename)
# To manage any delay in file writing
time.sleep(0.5)
# Start clustering process and generate
# output images with annotations
EncodingPickleFilePath = "encodings.pickle"
faceClusterUtility = FaceClusterUtility(EncodingPickleFilePath)
faceImageGenerator = FaceImageGenerator(EncodingPickleFilePath)
labelIDs = faceClusterUtility.Cluster()
faceImageGenerator.GenerateImages(
labelIDs, "ClusteredFaces", "Montage")
Salida de montaje:
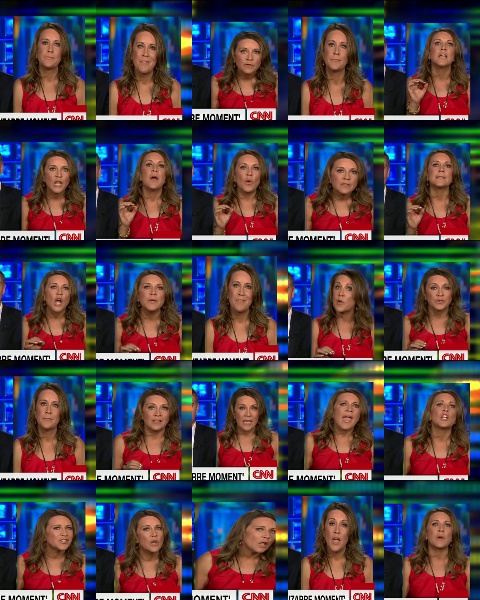
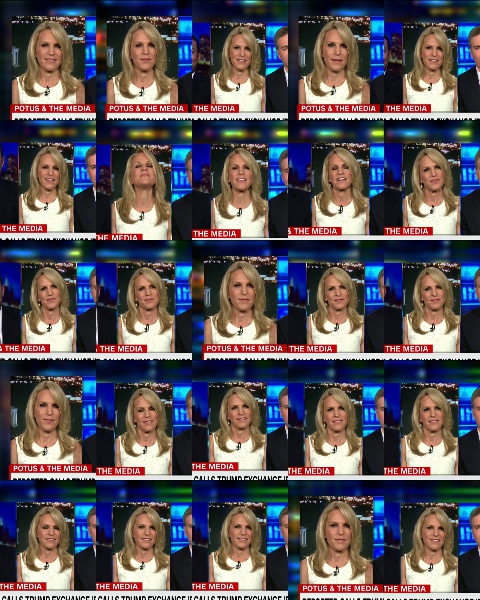

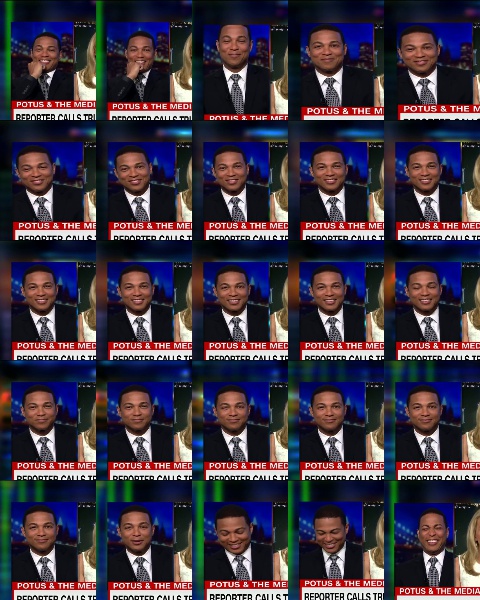
Solución de problemas –
Pregunta 1: Todo el equipo se congela al extraer incrustaciones faciales.
Solución: La solución es disminuir los valores en la función de cambio de tamaño de fotogramas al extraer fotogramas de un videoclip de entrada. Recuerde, disminuir demasiado los valores dará como resultado una agrupación de caras incorrecta. En lugar de cambiar el tamaño del marco, podemos introducir algo de detección de rostros frontales y recortar los rostros frontales solo para mejorar la precisión.
Pregunta 2: La PC se vuelve lenta mientras ejecuta la canalización.
Solución: La CPU se utilizará al máximo nivel. Para limitar el uso, puede disminuir la cantidad de subprocesos especificados en el constructor de canalización.
Pregunta 3: La agrupación de salida es demasiado inexacta.
Solución:La única razón del caso puede ser que los fotogramas extraídos del videoclip de entrada tengan muchas caras con una resolución muy pequeña o que la cantidad de fotogramas sea muy inferior (alrededor de 7-8). Tenga la amabilidad de obtener un clip de video con imágenes brillantes y claras de rostros o, para el último caso, obtenga un video de 2 minutos o un mod con código fuente para la extracción de cuadros de video.
Consulte el enlace de Github para obtener el código completo y el archivo adicional utilizado: https://github.com/cppxaxa/FaceRecognitionPipeline_GeeksForGeeks
Referencias:
1. Publicación de blog de Adrian sobre agrupamiento de caras
2. Guía de PyPiper
3. Manual de OpenCV
4. StackOverflow
Publicación traducida automáticamente
Artículo escrito por Prateek Xaxa y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA