Aprendizaje sin supervisión:
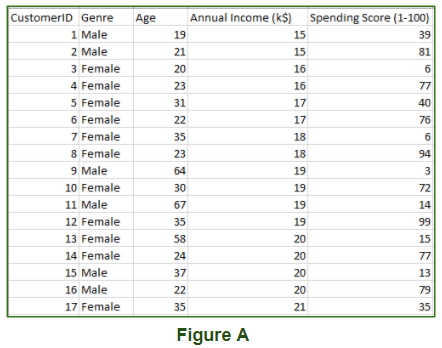
O análisis de aprendizaje automático no supervisados y agrupa conjuntos de datos no etiquetados utilizando algoritmos de aprendizaje automático. Estos algoritmos encuentran patrones y datos ocultos sin intervención humana, es decir, no damos resultados a nuestro modelo. El modelo de entrenamiento solo tiene valores de parámetros de entrada y descubre los grupos o patrones por sí solo. El conjunto de datos de la Figura A son datos del centro comercial que contienen información sobre los clientes que se suscriben a ellos. Una vez suscritos, se les proporciona una tarjeta de membresía y el centro comercial tiene información completa sobre el cliente y cada una de sus compras. Ahora, utilizando estos datos y técnicas de aprendizaje no supervisadas, el centro comercial puede agrupar fácilmente a los clientes según los parámetros que estamos ingresando.
La entrada a los modelos de aprendizaje no supervisado es la siguiente:
- Datos no estructurados : pueden contener datos ruidosos (sin sentido), valores faltantes o datos desconocidos
- Datos sin etiquetar : los datos solo contienen un valor para los parámetros de entrada, no hay un valor objetivo (salida). Es fácil de recopilar en comparación con el etiquetado en el enfoque Supervisado.
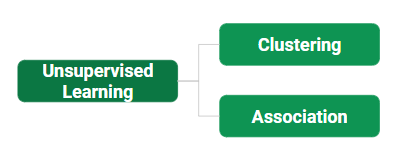
Los tipos de aprendizaje no supervisado son los siguientes:
- Agrupación: en términos generales, esta técnica se aplica para agrupar datos en función de diferentes patrones, como similitudes o diferencias, encuentra nuestro modelo de máquina. Estos algoritmos se utilizan para procesar objetos de datos sin procesar y sin clasificar en grupos. Por ejemplo, en la figura anterior, no hemos dado valores de parámetros de salida, por lo que esta técnica se utilizará para agrupar clientes en función de los parámetros de entrada proporcionados por nuestros datos.
- Asociación: esta técnica es una técnica de ML basada en reglas que descubre algunas relaciones muy útiles entre los parámetros de un gran conjunto de datos. Esta técnica se utiliza básicamente para el análisis de la cesta de la compra que ayuda a comprender mejor la relación entre los diferentes productos. Por ejemplo, las tiendas de compras utilizan algoritmos basados en esta técnica para averiguar la relación entre la venta de un producto y las ventas de otro en función del comportamiento del cliente. Por ejemplo, si un cliente compra leche, también puede comprar pan, huevos o mantequilla. Una vez bien entrenados, estos modelos se pueden utilizar para aumentar sus ventas mediante la planificación de diferentes ofertas.
Algunos algoritmos: Agrupación de K-Means
- DBSCAN: agrupación espacial basada en la densidad de aplicaciones con ruido
- BIRCH: Reducción iterativa equilibrada y agrupamiento mediante jerarquías
- Agrupación jerárquica
Aprendizaje semisupervisado:
Como su nombre indica, su funcionamiento se encuentra entre las técnicas supervisadas y no supervisadas. Usamos estas técnicas cuando tratamos con datos que están un poco etiquetados y la gran parte restante no está etiquetada. Podemos usar las técnicas no supervisadas para predecir etiquetas y luego alimentar estas etiquetas a técnicas supervisadas. Esta técnica es aplicable principalmente en el caso de conjuntos de datos de imágenes en los que, por lo general, todas las imágenes no están etiquetadas.
Aprendizaje reforzado:
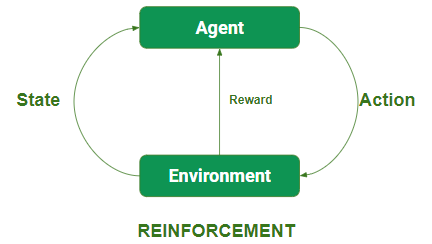
En esta técnica, el modelo sigue aumentando su rendimiento utilizando Reward Feedback para aprender el comportamiento o patrón. Estos algoritmos son específicos para un problema particular, por ejemplo, Google Self Driving car, AlphaGo, donde un bot compite con humanos e incluso consigo mismo para obtener mejores resultados en Go Game. Cada vez que ingresamos datos, aprenden y agregan los datos a su conocimiento, que son datos de entrenamiento. Entonces, cuanto más aprende, mejor se entrena y, por lo tanto, experimenta.
- Los agentes observan la entrada.
- Un agente realiza una acción tomando algunas decisiones.
- Después de su actuación, un agente recibe una recompensa y, en consecuencia, refuerza y el modelo almacena en un par de información estado-acción.
- Diferencia Temporal (DT)
- Q-aprendizaje
- Redes antagónicas profundas
Cursos GeeksforGeeks
Aprendizaje automático básico y avanzado: curso a su propio ritmo
Debes haber escuchado mucho sobre el aprendizaje automático, ¿verdad? Aquí hay una manera perfecta de comenzar con esto. Un curso de nivel principiante a avanzado seleccionado por expertos de la industria para ayudarlo a aprender temas importantes de aprendizaje automático como agrupamiento, dimensionalidad de datos, NLP y mucho más. Entonces, ¿por qué esperar? Inscríbase ahora y conviértase en un ingeniero de aprendizaje automático listo para la industria hoy.
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA