Tomar decisiones rápidas y acertadas es vital en estos días y más ahora que el mundo se enfrenta a un fenómeno como el COVID-19, por lo que contar con información tanto actual como proyectada es determinante para este proceso.
En este sentido, hemos aplicado un modelo en el que es posible observar el pico en casos específicos de países, utilizando información estadística actual, esperando que pueda ser utilizado como base de apoyo para tomar acciones en este escenario. Para lograr este objetivo, se ha aplicado al modelo una regresión no lineal, utilizando una función logística. Este proceso consiste en:
- Limpieza de datos
- Elegir la ecuación más adecuada que se pueda adaptar gráficamente a los datos, en este caso, Función Logística (Sigmoide)
- Normalización de base de datos
- Ajuste del modelo a nuestro conjunto de datos mediante el proceso “curve_fit”, obteniendo una nueva beta de referencia.
- Evaluación del modelo
El conjunto de datos es público y está disponible en Data.europa.eu siguiendo este enlace: Limpieza de datos del CONJUNTO DE
DATOS: Los datos disponibles se han etiquetado originalmente. Pudimos identificar dos países que no mencionaron la ubicación geográfica, esta información se agregó, sin embargo, no contribuiría significativamente al modelo. Se agrega una nueva columna al conjunto de datos denominado «n-day» para mostrar el número de días consecutivos.
Código: Importación de bibliotecas
Python3
# import libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt % matplotlib inline # sklearn specific function to obtain R2 calculations from sklearn.metrics import r2_score
Código: Uso de datos
Python3
# Data Reading
df = pd.read_excel("C:/BaseDato / COVID-19-310302020chi.xlsx")
df.head()
Producción:
Código:
Python3
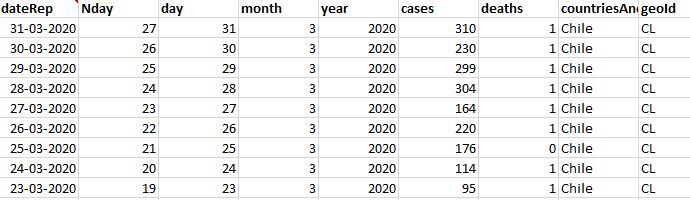
# Initial Data Graphics
plt.figure(figsize =(8, 5))
x_data, y_data = (df["Nday"].values, df["cases"].values)
plt.plot(x_data, y_data, 'ro')
plt.title('Data: Cases Vs Day of infection')
plt.ylabel('Cases')
plt.xlabel('Day Number')
Producción:
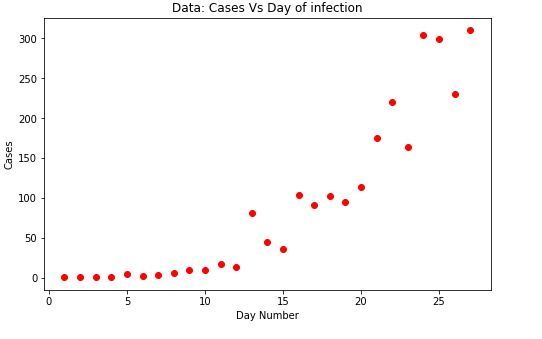
Código: Elección del modelo
Aplicamos la función logística, un caso específico de las funciones sigmoideas, considerando que la curva original comienza con un crecimiento lento permaneciendo casi plana por un tiempo antes de aumentar, eventualmente podría descender o mantener su crecimiento en forma de una curva exponencial .
La fórmula de la función logística es:
Y = 1/(1+e^B1(X-B2))
Código: Construcción del modelo
Python3
# Definition of the logistic function
def sigmoid(x, Beta_1, Beta_2):
y = 1 / (1 + np.exp(-Beta_1*(x-Beta_2)))
return y
# Choosing initial arbitrary beta parameters
beta_1 = 0.09
beta_2 = 305
# application of the logistic function using beta
Y_pred = sigmoid(x_data, beta_1, beta_2)
# point prediction
plt.plot(x_data, Y_pred * 15000000000000., label = "Model")
plt.plot(x_data, y_data, 'ro', label = "Data")
plt.title('Data Vs Model')
plt.legend(loc ='best')
plt.ylabel('Cases')
plt.xlabel('Day Number')
Producción:
Normalización de datos: Aquí se normalizan las variables x e y asignándoles un rango de 0 a 1 (dependiendo de cada caso). Por lo tanto, ambos pueden interpretarse con la misma relevancia.
Referencia – información
Código:
Python3
xdata = x_data / max(x_data) ydata = y_data / max(y_data)
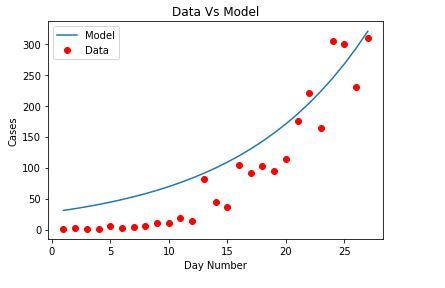
Ajuste del Modelo:
El objetivo es obtener nuevos parámetros B óptimos, para ajustar el modelo a nuestros datos. Usamos «curve_fit» que usa mínimos cuadrados no lineales para ajustar la función sigmoidea. Siendo “popt” nuestros parámetros optimizados.
Código: Entrada
Python3
from scipy.optimize import curve_fit
popt, pcov = curve_fit(sigmoid, xdata, data)
# imprimir los parámetros finales
print(" beta_1 = % f, beta_2 = % f" % (popt[0], popt[1]))
Producción:
beta_1 = 9.833364, beta_2 = 0.777140
Código: se aplican nuevos valores Beta al modelo
Python3
x = np.linspace(0, 40, 4)
x = x / max(x)
plt.figure(figsize = (8, 5))
y = sigmoid(x, *popt)
plt.plot(xdata, ydata, 'ro', label ='data')
plt.plot(x, y, linewidth = 3.0, label ='fit')
plt.title("Data Vs Fit model")
plt.legend(loc ='best')
plt.ylabel('Cases')
plt.xlabel('Day Number')
plt.show()
Evaluación del modelo: el modelo está listo para ser evaluado. Los datos se dividen en 80:20, para entrenamiento y prueba respectivamente. Los datos se aplican al modelo obteniendo las medias estadísticas correspondientes para evaluar la distancia de los datos resultantes a la línea de regresión.
Código: Entrada
Python3
# Model accuracy calculation
# Splitting training and testing data
L = np.random.rand(len(df)) < 0.8 # 80 % training data
train_x = xdata[L]
test_x = xdata[~L]
train_y = ydata[L]
test_y = ydata[~L]
# Construction of the model
popt, pcov = curve_fit(sigmoid, train_x, train_y)
# Predicting using testing model
y_predic = sigmoid(test_x, *popt)
# Evaluation
print("Mean Absolute Error: %.2f" % np.mean(np.absolute(y_predic - test_y)))
print("Mean Square Error (MSE): %.2f" % np.mean(( test_y - y_predic)**2))
print("R2-score: %.2f" % r2_score(y_predic, test_y))
Producción:
Mean Absolute Error: 0.06 Mean Square Error (MSE): 0.01 R2-score: 0.93
Publicación traducida automáticamente
Artículo escrito por liuandreschang y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA