sklearn.preprocessing.Binarizer() es un método que pertenece al módulo de preprocesamiento. Desempeña un papel clave en la discretización de valores de características continuas.
Ejemplo #1:
Los datos continuos de valores de píxeles de una imagen en escala de grises de 8 bits tienen valores que oscilan entre 0 (negro) y 255 (blanco) y se necesita que sea en blanco y negro. Entonces, al usar Binarizer(), se puede establecer un umbral que convierte los valores de píxeles de 0 a 127 en 0 y de 128 a 255 en 1.
Ejemplo n.º 2:
uno tiene un registro de máquina que tiene «Porcentaje de éxito» como característica. Estos valores son continuos y van del 10 % al 99 %, pero un investigador simplemente quiere usar estos datos para predecir el estado de aprobación o falla de la máquina en función de otros parámetros dados.
Sintaxis:
sklearn.preprocessing.Binarizer(threshold, copy)
Parámetros:
umbral: [flotante, opcional] Los valores menores o iguales que el umbral se asignan a 0, de lo contrario, a 1. Por defecto, el valor del umbral es 0.0.
copy: [booleano, opcional] Si se establece en False, evita una copia. Por defecto es Verdadero.
Devolver :
Binarized Feature values
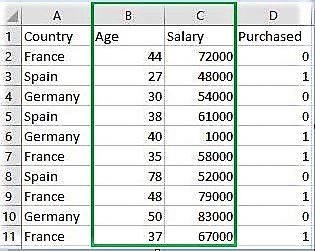
Descargue el conjunto de datos:
vaya al enlace y descargue Data.csv
A continuación se muestra el código de Python que explica sklearn.Binarizer()
Python3
# Python code explaining how
# to Binarize feature values
""" PART 1
Importing Libraries """
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
# Sklearn library
from sklearn import preprocessing
""" PART 2
Importing Data """
data_set = pd.read_csv(
'C:\\Users\\dell\\Desktop\\Data_for_Feature_Scaling.csv')
data_set.head()
# here Features - Age and Salary columns
# are taken using slicing
# to binarize values
age = data_set.iloc[:, 1].values
salary = data_set.iloc[:, 2].values
print ("\nOriginal age data values : \n", age)
print ("\nOriginal salary data values : \n", salary)
""" PART 4
Binarizing values """
from sklearn.preprocessing import Binarizer
x = age
x = x.reshape(1, -1)
y = salary
y = y.reshape(1, -1)
# For age, let threshold be 35
# For salary, let threshold be 61000
binarizer_1 = Binarizer(35)
binarizer_2 = Binarizer(61000)
# Transformed feature
print ("\nBinarized age : \n", binarizer_1.fit_transform(x))
print ("\nBinarized salary : \n", binarizer_2.fit_transform(y))
Producción :
Country Age Salary Purchased 0 France 44 72000 0 1 Spain 27 48000 1 2 Germany 30 54000 0 3 Spain 38 61000 0 4 Germany 40 1000 1 Original age data values : [44 27 30 38 40 35 78 48 50 37] Original salary data values : [72000 48000 54000 61000 1000 58000 52000 79000 83000 67000] Binarized age : [[1 0 0 1 1 0 1 1 1 1]] Binarized salary : [[1 0 0 0 0 0 0 1 1 1]]
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA