Aprendizaje automático: como se discutió en este artículo , el aprendizaje automático no es más que un campo de estudio que permite a las computadoras «aprender» como humanos sin necesidad de programación explícita.
Qué es el modelado predictivo: el modelado predictivo es un proceso probabilístico que nos permite pronosticar resultados, sobre la base de algunos predictores. Estos predictores son básicamente características que entran en juego a la hora de decidir el resultado final, es decir, el resultado del modelo.
¿Qué es la Reducción de Dimensionalidad?
En los problemas de clasificación de aprendizaje automático, a menudo hay demasiados factores sobre la base de los cuales se realiza la clasificación final. Estos factores son básicamente variables llamadas características. Cuanto mayor sea el número de funciones, más difícil será visualizar el conjunto de entrenamiento y luego trabajar en él. A veces, la mayoría de estas características están correlacionadas y, por lo tanto, son redundantes. Aquí es donde entran en juego los algoritmos de reducción de dimensionalidad. La reducción de dimensionalidad es el proceso de reducir el número de variables aleatorias bajo consideración, mediante la obtención de un conjunto de variables principales. Se puede dividir en selección de características y extracción de características.
¿Por qué es importante la reducción de la dimensionalidad en el aprendizaje automático y el modelado predictivo?
Un ejemplo intuitivo de reducción de dimensionalidad se puede discutir a través de un problema simple de clasificación de correo electrónico, donde necesitamos clasificar si el correo electrónico es correo no deseado o no. Esto puede involucrar una gran cantidad de características, como si el correo electrónico tiene un título genérico o no, el contenido del correo electrónico, si el correo electrónico usa una plantilla, etc. Sin embargo, algunas de estas características pueden superponerse. . En otra condición, un problema de clasificación que se basa tanto en la humedad como en la lluvia se puede colapsar en una sola característica subyacente, ya que ambas están correlacionadas en un alto grado. Por lo tanto, podemos reducir el número de funciones en tales problemas. Un problema de clasificación en 3D puede ser difícil de visualizar, mientras que uno en 2D se puede asignar a un espacio bidimensional simple y un problema de 1D a una línea simple. La siguiente figura ilustra este concepto,
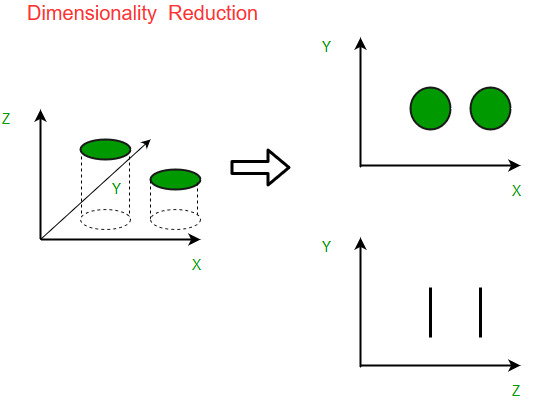
Componentes de la reducción de la dimensionalidad
Hay dos componentes de la reducción de la dimensionalidad:
- Selección de características: en esto, tratamos de encontrar un subconjunto del conjunto original de variables, o características, para obtener un subconjunto más pequeño que pueda usarse para modelar el problema. Suele implicar tres formas:
- Filtrar
- Envoltura
- Incrustado
- Extracción de características: Esto reduce los datos en un espacio de alta dimensión a un espacio de menor dimensión, es decir, un espacio con menor no. de dimensiones
Métodos de reducción de la dimensionalidad
Los diversos métodos utilizados para la reducción de la dimensionalidad incluyen:
- Análisis de componentes principales (PCA)
- Análisis Discriminante Lineal (LDA)
- Análisis Discriminante Generalizado (GDA)
La reducción de la dimensionalidad puede ser lineal o no lineal, según el método utilizado. El método lineal principal, llamado Análisis de Componentes Principales, o PCA, se analiza a continuación.
Análisis de componentes principales
Este método fue introducido por Karl Pearson. Funciona con la condición de que mientras los datos en un espacio dimensional superior se asignan a datos en un espacio dimensional inferior, la variación de los datos en el espacio dimensional inferior debe ser máxima.
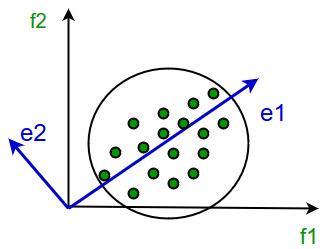
Implica los siguientes pasos:
- Construya la array de covarianza de los datos.
- Calcule los vectores propios de esta array.
- Los vectores propios correspondientes a los valores propios más grandes se utilizan para reconstruir una gran fracción de la varianza de los datos originales.
Por lo tanto, nos quedamos con un número menor de vectores propios y podría haber habido alguna pérdida de datos en el proceso. Pero, las varianzas más importantes deben ser retenidas por los vectores propios restantes.
Ventajas de la reducción de la dimensionalidad
- Ayuda en la compresión de datos y, por lo tanto, reduce el espacio de almacenamiento.
- Reduce el tiempo de cálculo.
- También ayuda a eliminar funciones redundantes, si las hay.
Desventajas de la reducción de la dimensionalidad
- Puede conducir a una cierta cantidad de pérdida de datos.
- PCA tiende a encontrar correlaciones lineales entre variables, lo que a veces no es deseable.
- PCA falla en los casos en que la media y la covarianza no son suficientes para definir conjuntos de datos.
- Es posible que no sepamos cuántos componentes principales mantener; en la práctica, se aplican algunas reglas generales.
Este artículo es una contribución de Anannya Uberoi . Si te gusta GeeksforGeeks y te gustaría contribuir, también puedes escribir un artículo usando write.geeksforgeeks.org o enviar tu artículo por correo a review-team@geeksforgeeks.org. Vea su artículo que aparece en la página principal de GeeksforGeeks y ayude a otros Geeks.
Escriba comentarios si encuentra algo incorrecto o si desea compartir más información sobre el tema tratado anteriormente.
Publicación traducida automáticamente
Artículo escrito por GeeksforGeeks-1 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA