Prerrequisito: Distribución de Probabilidad
Densidad de probabilidad: suponga una variable aleatoria x que tiene una distribución de probabilidad p(x). La relación entre los resultados de una variable aleatoria y su probabilidad se denomina densidad de probabilidad.
El problema es que no siempre conocemos la distribución de probabilidad completa de una variable aleatoria. Esto se debe a que solo usamos un pequeño subconjunto de observaciones para derivar el resultado. Este problema se conoce como Estimación de densidad de probabilidad , ya que usamos solo una muestra aleatoria de observaciones para encontrar la densidad general de todo el espacio muestral.
Función de densidad de probabilidad (PDF)
Un PDF es una función que indica la probabilidad de que la variable aleatoria de un espacio de submuestra se encuentre dentro de un rango particular de valores y no solo de un valor. Indica la probabilidad de que el rango de valores en el subespacio de la variable aleatoria sea el mismo que el de toda la muestra.
Por definición, si X es cualquier variable aleatoria continua, entonces la función f(x) se denomina función de densidad de probabilidad si:

where, a -> lower limit b -> upper limit X -> continuous random variable f(x) -> probability density function
Pasos involucrados:
Step 1 - Create a histogram for the random set of observations to understand the
density of the random sample.
Step 2 - Create the probability density function and fit it on the random sample.
Observe how it fits the histogram plot.
Step 3 - Now iterate steps 1 and 2 in the following manner:
3.1 - Calculate the distribution parameters.
3.2 - Calculate the PDF for the random sample distribution.
3.3 - Observe the resulting PDF against the data.
3.4 - Transform the data to until it best fits the distribution.
La mayor parte del histograma de las diferentes muestras aleatorias después del ajuste debe coincidir con la gráfica del histograma de toda la población.
Estimación de densidad: es el proceso de averiguar la densidad de toda la población mediante el examen de una muestra aleatoria de datos de esa población. Una de las mejores formas de lograr una estimación de la densidad es mediante un gráfico de histograma.
Estimación de densidad paramétrica
Una distribución normal tiene dos parámetros dados, media y desviación estándar. Calculamos la media muestral y la desviación estándar de la muestra aleatoria tomada de esta población para estimar la densidad de la muestra aleatoria. La razón por la que se denomina «paramétrico» se debe al hecho de que la relación entre las observaciones y su probabilidad puede ser diferente en función de los valores de los dos parámetros.
Ahora bien, es importante entender que la media y desviación estándar de esta muestra aleatoria no va a ser la misma que la de toda la población debido a su pequeño tamaño. A continuación se muestra un gráfico de muestra para la estimación de la densidad paramétrica.
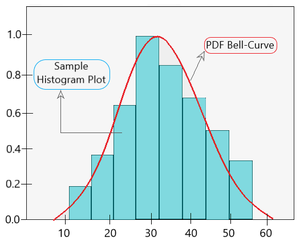
PDF ajustado sobre gráfico de histograma con un valor máximo
Estimación de densidad no paramétrica
En algunos casos, es posible que la PDF no se ajuste a la muestra aleatoria ya que no sigue una distribución normal (es decir, en lugar de un pico, hay múltiples picos en el gráfico). Aquí, en lugar de usar parámetros de distribución como la media y la desviación estándar, se usa un algoritmo particular para estimar la distribución de probabilidad. Por lo tanto, se conoce como una «estimación de densidad no paramétrica» .
Uno de los enfoques no paramétricos más comunes se conoce como estimación de la densidad del núcleo . En esto, el objetivo es calcular la densidad desconocida f h (x) usando la ecuación dada a continuación:

where, K -> kernel (non-negative function) h -> bandwidth (smoothing parameter, h > 0) Kh -> scaled kernel fh(x) -> density (to calculate) n -> no. of samples in random sample.
A continuación se proporciona una gráfica de muestra para la estimación de la densidad no paramétrica.
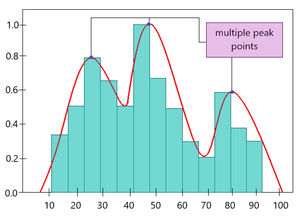
Diagrama en PDF sobre diagrama de histograma de muestra basado en KDE
Problemas con la estimación de distribución de probabilidad
La estimación de distribución de probabilidad se basa en encontrar el mejor PDF y determinar sus parámetros con precisión. Pero la muestra de datos aleatorios que consideramos es muy pequeña. Por lo tanto, se vuelve muy difícil determinar qué parámetros y qué función de distribución de probabilidad usar. Para abordar este problema, se utiliza la estimación de máxima verosimilitud.
Estimación de máxima verosimilitud
Es un método para determinar los parámetros (media, desviación estándar, etc.) de datos de muestras aleatorias distribuidas normalmente o un método para encontrar la PDF que mejor se ajusta a los datos de muestras aleatorias. Esto se hace maximizando la función de probabilidad para que la PDF se ajuste a la muestra aleatoria. Otra forma de verlo es que la función MLE da la media, la desviación estándar de la muestra aleatoria es más similar a la de la muestra completa .
NOTA: MLE asume que todos los archivos PDF son candidatos probables para ser la mejor curva de ajuste. Por lo tanto, es un método computacionalmente costoso.
Intuición:
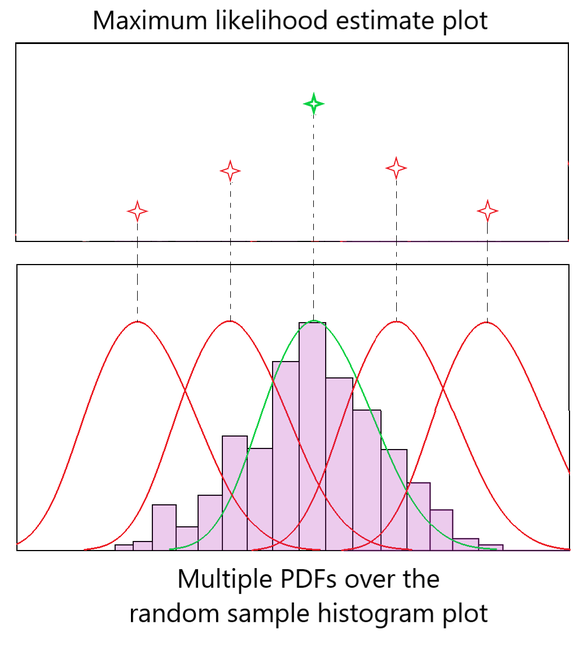
Figura 1: Intuición MLE
La figura 1 muestra varios intentos de ajustar la curva de campana PDF sobre los datos de muestra aleatorios. Las curvas de campana rojas indican un PDF mal ajustado y la curva de campana verde muestra el PDF de mejor ajuste sobre los datos. Obtuvimos la curva de campana óptima comprobando los valores en el gráfico de estimación de máxima verosimilitud correspondiente a cada PDF.
Como se observa en la figura 1, las gráficas rojas se ajustan mal a la distribución normal, por lo que su «estimación de probabilidad» también es más baja. La curva PDF verde tiene la estimación de máxima verosimilitud, ya que se ajusta perfectamente a los datos. Así es como funciona el método de estimación de máxima verosimilitud.
Matemáticas involucradas
En la intuición, discutimos el papel que juega el valor de probabilidad en la determinación de la curva PDF óptima. Entendamos las matemáticas involucradas en el método MLE.
Calculamos la probabilidad en función de las probabilidades condicionales. Vea la ecuación dada a continuación.
![L = F(\ [X_1 = x_1],[X_2 = x_2], ...,[X_n = x_n]\ |\ P) = \Pi_{i = 1}^{n}P^{x_i}(1-P)^{1-x_i}](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-1414c230180ffecaa06ba79207707f91_l3.png "Rendered by QuickLaTeX.com")
where, L -> Likelihood value F -> Probability distribution function P -> Probability X1, X2, ... Xn -> random sample of size n taken from the whole population. x1, x2, ... xn -> values that these random sample (Xi) takes when determining the PDF. Π -> product from 1 to n.
En la ecuación dada arriba, estamos tratando de determinar el valor de probabilidad calculando la probabilidad conjunta de que cada X i tome un valor específico x i involucrado en un PDF particular. Ahora, dado que estamos buscando el valor de máxima verosimilitud, diferenciamos la función de verosimilitud wrt P y la establecemos en 0 como se indica a continuación.

De esta forma, podemos obtener la curva PDF que tiene la máxima probabilidad de ajuste sobre los datos de la muestra aleatoria.
Pero, si observas detenidamente, diferenciar L wrt P no es una tarea fácil ya que todas las probabilidades en la función de verosimilitud son un producto. Por lo tanto, el cálculo se vuelve computacionalmente costoso. Para resolver esto, tomamos el logaritmo de la función de Verosimilitud L.
Probabilidad de registro

Tomar el registro de la función de probabilidad da el mismo resultado que antes debido a la naturaleza creciente de la función de registro. Pero ahora, se vuelve menos computacional debido a la propiedad del logaritmo: 
Así, la ecuación se convierte en:
![\log(L) = \log[\Pi_{i = 1}^{n}P^{x_i}(1-P)^{1-x_i}] \\ = \Sigma_{i = 1}^{n}\log[P^{x_i}(1-P)^{1-x_i}]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-e45315a1cf7ef21b739022849d1362e8_l3.png "Rendered by QuickLaTeX.com")
Ahora, podemos diferenciar fácilmente log L wrt P y obtener el resultado deseado. Para cualquier duda/consulta, comenta abajo.
Publicación traducida automáticamente
Artículo escrito por prakharr0y y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA