En este artículo, aprenderemos cómo implementar una puerta XOR en Tensorflow. Antes de pasar a la implementación de Tensorflow, veremos cómo la tabla de verdad de XOR Gate permite obtener una comprensión profunda de XOR.
|
X |
Y |
X (XOR) Y |
|---|---|---|
|
0 |
0 |
0 |
|
0 |
1 |
1 |
|
1 |
0 |
1 |
|
1 |
1 |
0 |
De la tabla de verdad anterior, llegamos a saber que la salida de la puerta es 1 solo cuando una de las entradas es 1. Si ambas entradas son idénticas, entonces la salida es 0. Ahora que sabemos cómo funciona una puerta XOR, permítanos Comencemos con la implementación de XOR usando Tensorflow.
Acercarse
Comenzaremos con la implementación de XOR usando tensorflow.
Paso 1: Importación de todas las bibliotecas requeridas. Aquí estamos usando tensorflow y numpy .
import tensorflow.compat.v1 as tf tf.disable_v2_behaviour() import numpy as np
Paso 2: Cree marcadores de posición para entrada y salida. La entrada tendrá la forma (4 X 2) y la salida tendrá la forma (4 × 1).
X = tf.placeholder(dtype=tf.float32, shape=(4,2)) Y = tf.placeholder(dtype=tf.float32, shape=(4,1))
Paso 3: Cree entradas y salidas de capacitación.
INPUT_XOR = [[0,0],[0,1],[1,0],[1,1]] OUTPUT_XOR = [[0],[1],[1],[0]]
Paso 4: Proporcione una tasa de aprendizaje estándar y la cantidad de épocas para las que el modelo debe entrenar.
learning_rate = 0.01 epochs = 10000
Paso 5: crea una capa oculta para el modelo. Las capas ocultas tienen pesos y sesgos. El funcionamiento de la capa oculta es multiplicar la entrada proporcionada con los pesos y luego agregar sesgos al producto. Luego, esta respuesta se le da a una función de activación de Relu para dar la salida a la siguiente capa.
con tf.variable_scope(‘oculto’):
h_w = tf.Variable(tf.truncado_normal([2, 2]), nombre=’pesos’)
h_b = tf.Variable(tf.truncado_normal([4, 2]), nombre=’sesgos’)
h = tf.nn.relu(tf.matmul(X, h_w) + h_b)
Paso 6: cree una capa de salida para el modelo. La capa de salida, similar a las capas ocultas, tiene pesos y sesgos y realiza las mismas funcionalidades, pero en lugar de una activación de Relu, usamos la función de activación de Sigmoid para obtener salidas entre 0 y 1.
con tf.variable_scope(‘salida’):
o_w = tf.Variable(tf.truncado_normal([2, 1]), nombre=’pesos’)
o_b = tf.Variable(tf.truncado_normal([4, 1]), nombre=’sesgos’)
Y_estimación = tf.nn.sigmoid(tf.matmul(h, o_w) + o_b)
Paso 7: Cree una función de pérdida/costo. Esto calcula el costo para que el modelo entrene en los datos dados. Aquí hacemos RMSE del valor de salida previsto y el valor de salida real. RMSE: error cuadrático medio.
with tf.variable_scope('cost'):
cost = tf.reduce_mean(tf.squared_difference(Y_estimation, Y))
Paso 8: Cree una variable de entrenamiento para entrenar el modelo con la función de costo/pérdida dada con un ADAM Optimizer con la tasa de aprendizaje dada para minimizar la pérdida.
with tf.variable_scope('train'):
train = tf.train.AdamOptimizer(learning_rate).minimize(cost)
Paso 9: ahora que todas las cosas requeridas están inicializadas, iniciaremos una sesión de Tensorflow y comenzaremos el entrenamiento inicializando todas las variables declaradas anteriormente.
with tf.Session() as session:
session.run(tf.global_variables_initializer())
print("Training Started")
Paso 10: entrenar el modelo y dar predicciones. Aquí ejecutamos el entrenamiento en entrada y salida ya que estamos haciendo aprendizaje supervisado. Luego calculamos el costo por cada 1000 épocas y, al final, predecimos la salida y la comparamos con la salida real.
log_count_frac = epochs/10
for epoch in range(epochs):
# Training the base network
session.run(train, feed_dict={X: INPUT_XOR, Y:OUTPUT_XOR})
# log training parameters
# Print cost for every 1000 epochs
if epoch % log_count_frac == 0:
cost_results = session.run(cost, feed_dict={X: INPUT_XOR, Y:OUTPUT_XOR})
print("Cost of Training at epoch {0} is {1}".format(epoch, cost_results))
print("Training Completed !")
Y_test = session.run(Y_estimation, feed_dict={X:INPUT_XOR})
print(np.round(Y_test, decimals=1))
A continuación se muestra la implementación completa.
Python3
# import tensorflow library
# Since we'll be using functionalities
# of tensorflow V1 Let us import Tensorflow v1
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import numpy as np
# Create placeholders for input X and output Y
X = tf.placeholder(dtype=tf.float32, shape=(4, 2))
Y = tf.placeholder(dtype=tf.float32, shape=(4, 1))
# Give training input and label
INPUT_XOR = [[0,0],[0,1],[1,0],[1,1]]
OUTPUT_XOR = [[0],[1],[1],[0]]
# Give a standard learning rate and the number
# of epochs the model has to train for.
learning_rate = 0.01
epochs = 10000
# Create/Initialize a Hidden Layer variable
with tf.variable_scope('hidden'):
# Initialize weights and biases for the
# hidden layer randomly whose mean=0 and
# std_dev=1
h_w = tf.Variable(tf.truncated_normal([2, 2]), name='weights')
h_b = tf.Variable(tf.truncated_normal([4, 2]), name='biases')
# Pass the matrix multiplied Input and
# weights added with Bias to the relu
# activation function
h = tf.nn.relu(tf.matmul(X, h_w) + h_b)
# Create/Initialize an Output Layer variable
with tf.variable_scope('output'):
# Initialize weights and biases for the
# output layer randomly whose mean=0 and
# std_dev=1
o_w = tf.Variable(tf.truncated_normal([2, 1]), name='weights')
o_b = tf.Variable(tf.truncated_normal([4, 1]), name='biases')
# Pass the matrix multiplied hidden layer
# Input and weights added with Bias
# to a sigmoid activation function
Y_estimation = tf.nn.sigmoid(tf.matmul(h, o_w) + o_b)
# Create/Initialize Loss function variable
with tf.variable_scope('cost'):
# Calculate cost by taking the Root Mean
# Square between the estimated Y value
# and the actual Y value
cost = tf.reduce_mean(tf.squared_difference(Y_estimation, Y))
# Create/Initialize Training model variable
with tf.variable_scope('train'):
# Train the model with ADAM Optimizer
# with the previously initialized learning
# rate and the cost from the previous variable
train = tf.train.AdamOptimizer(learning_rate).minimize(cost)
# Start a Tensorflow Session
with tf.Session() as session:
# initialize the session variables
session.run(tf.global_variables_initializer())
print("Training Started")
# log count
log_count_frac = epochs/10
for epoch in range(epochs):
# Training the base network
session.run(train, feed_dict={X: INPUT_XOR, Y:OUTPUT_XOR})
# log training parameters
# Print cost for every 1000 epochs
if epoch % log_count_frac == 0:
cost_results = session.run(cost, feed_dict={X: INPUT_XOR, Y:OUTPUT_XOR})
print("Cost of Training at epoch {0} is {1}".format(epoch, cost_results))
print("Training Completed !")
Y_test = session.run(Y_estimation, feed_dict={X:INPUT_XOR})
print(np.round(Y_test, decimals=1))
Producción:
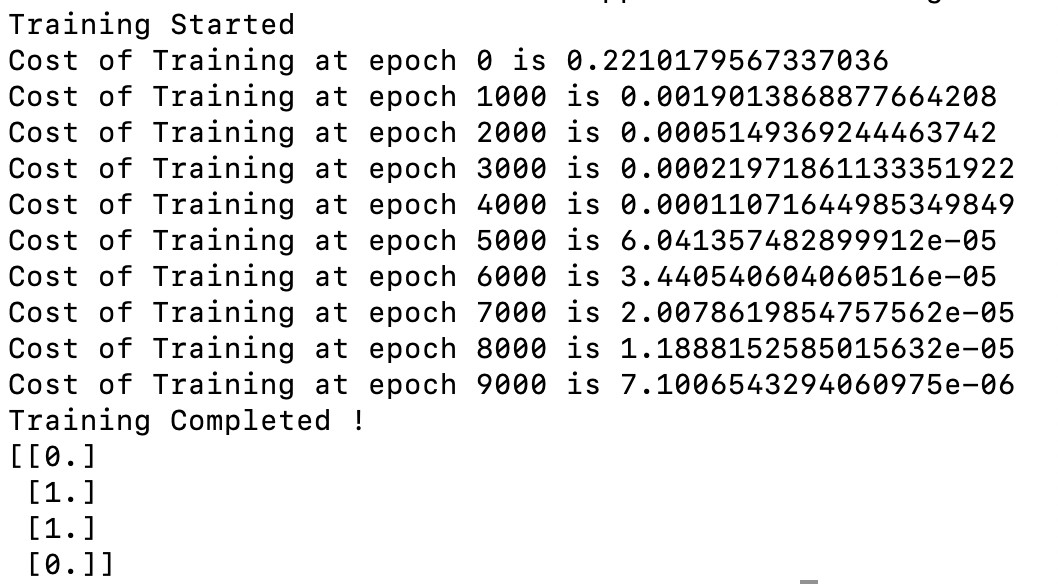
Salida del programa anterior
Publicación traducida automáticamente
Artículo escrito por rakshithacharya1030 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA