En el aprendizaje automático, el descenso de gradiente es una técnica de optimización utilizada para calcular los parámetros del modelo (coeficientes y sesgo) para algoritmos como la regresión lineal, la regresión logística, las redes neuronales, etc. En esta técnica, iteramos repetidamente a través del conjunto de entrenamiento y actualizamos el modelo. parámetros de acuerdo con el gradiente del error con respecto al conjunto de entrenamiento. Dependiendo de la cantidad de ejemplos de entrenamiento considerados en la actualización de los parámetros del modelo, tenemos 3 tipos de descensos de gradiente:
- Descenso de gradiente por lotes: los parámetros se actualizan después de calcular el gradiente del error con respecto a todo el conjunto de entrenamiento
- Descenso de gradiente estocástico: los parámetros se actualizan después de calcular el gradiente del error con respecto a un solo ejemplo de entrenamiento
- Descenso de gradiente de minilote: los parámetros se actualizan después de calcular el gradiente del error con respecto a un subconjunto del conjunto de entrenamiento
| Descenso de gradiente por lotes | Descenso de gradiente estocástico | Descenso de gradiente de mini lotes |
|---|---|---|
| Dado que todos los datos de entrenamiento se consideran antes de dar un paso en la dirección del gradiente, lleva mucho tiempo realizar una sola actualización. | Dado que solo se considera un único ejemplo de entrenamiento antes de dar un paso en la dirección del gradiente, nos vemos obligados a recorrer el conjunto de entrenamiento y, por lo tanto, no podemos aprovechar la velocidad asociada con la vectorización del código. | Dado que se considera un subconjunto de ejemplos de entrenamiento, puede realizar actualizaciones rápidas en los parámetros del modelo y también puede aprovechar la velocidad asociada con la vectorización del código. |
| Realiza actualizaciones suaves en los parámetros del modelo. | Hace actualizaciones muy ruidosas en los parámetros. | Según el tamaño del lote, las actualizaciones se pueden hacer menos ruidosas: cuanto mayor sea el tamaño del lote, menos ruidosa será la actualización. |
Por lo tanto, el descenso de gradiente de mini lotes hace un compromiso entre la convergencia rápida y el ruido asociado con la actualización de gradiente, lo que lo convierte en un algoritmo más flexible y robusto.
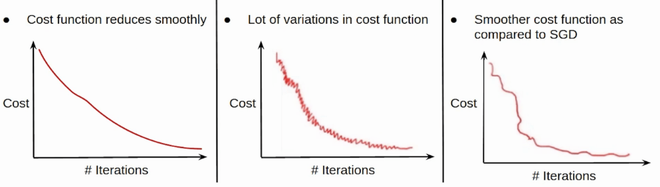
Convergencia en BGD, SGD y MBGD
Descenso de gradiente de mini lotes: Algoritmo-
Sea theta = parámetros del modelo y max_iters = número de épocas. para itr = 1, 2, 3, …, max_iters: para mini_batch (X_mini, y_mini):
- Pase adelante en el lote X_mini:
- Hacer predicciones sobre el mini lote
- Calcular el error en las predicciones (J(theta)) con los valores actuales de los parámetros
- Pase hacia atrás:
- Calcular gradiente (theta) = derivada parcial de J (theta) wrt theta
- Actualizar parámetros:
- theta = theta – tasa_de_aprendizaje*gradiente(theta)
A continuación se muestra la implementación de Python:
Paso #1: El primer paso es importar dependencias, generar datos para la regresión lineal y visualizar los datos generados. Hemos generado 8000 ejemplos de datos, cada uno con 2 atributos/características. Estos ejemplos de datos se dividen además en conjuntos de entrenamiento (X_train, y_train) y conjuntos de prueba (X_test, y_test) que tienen 7200 y 800 ejemplos respectivamente.
Python3
# importing dependencies import numpy as np import matplotlib.pyplot as plt # creating data mean = np.array([5.0, 6.0]) cov = np.array([[1.0, 0.95], [0.95, 1.2]]) data = np.random.multivariate_normal(mean, cov, 8000) # visualising data plt.scatter(data[:500, 0], data[:500, 1], marker='.') plt.show() # train-test-split data = np.hstack((np.ones((data.shape[0], 1)), data)) split_factor = 0.90 split = int(split_factor * data.shape[0]) X_train = data[:split, :-1] y_train = data[:split, -1].reshape((-1, 1)) X_test = data[split:, :-1] y_test = data[split:, -1].reshape((-1, 1)) print(& quot Number of examples in training set= % d & quot % (X_train.shape[0])) print(& quot Number of examples in testing set= % d & quot % (X_test.shape[0]))
Producción:
Número de ejemplos en el conjunto de entrenamiento = 7200 Número de ejemplos en el conjunto de prueba = 800
Paso #2: A continuación, escribimos el código para implementar la regresión lineal utilizando el descenso de gradiente de mini lotes. gradienteDescent() es la función principal del controlador y otras funciones son funciones auxiliares que se utilizan para hacer predicciones: hipótesis(), gradientes de cálculo: gradiente(), error de cálculo: costo() y creación de mini lotes: create_mini_batches(). La función del controlador inicializa los parámetros, calcula el mejor conjunto de parámetros para el modelo y devuelve estos parámetros junto con una lista que contiene un historial de errores a medida que se actualizan los parámetros.
Ejemplo
Python3
# linear regression using "mini-batch" gradient descent # function to compute hypothesis / predictions def hypothesis(X, theta): return np.dot(X, theta) # function to compute gradient of error function w.r.t. theta def gradient(X, y, theta): h = hypothesis(X, theta) grad = np.dot(X.transpose(), (h - y)) return grad # function to compute the error for current values of theta def cost(X, y, theta): h = hypothesis(X, theta) J = np.dot((h - y).transpose(), (h - y)) J /= 2 return J[0] # function to create a list containing mini-batches def create_mini_batches(X, y, batch_size): mini_batches = [] data = np.hstack((X, y)) np.random.shuffle(data) n_minibatches = data.shape[0] // batch_size i = 0 for i in range(n_minibatches + 1): mini_batch = data[i * batch_size:(i + 1)*batch_size, :] X_mini = mini_batch[:, :-1] Y_mini = mini_batch[:, -1].reshape((-1, 1)) mini_batches.append((X_mini, Y_mini)) if data.shape[0] % batch_size != 0: mini_batch = data[i * batch_size:data.shape[0]] X_mini = mini_batch[:, :-1] Y_mini = mini_batch[:, -1].reshape((-1, 1)) mini_batches.append((X_mini, Y_mini)) return mini_batches # function to perform mini-batch gradient descent def gradientDescent(X, y, learning_rate=0.001, batch_size=32): theta = np.zeros((X.shape[1], 1)) error_list = [] max_iters = 3 for itr in range(max_iters): mini_batches = create_mini_batches(X, y, batch_size) for mini_batch in mini_batches: X_mini, y_mini = mini_batch theta = theta - learning_rate * gradient(X_mini, y_mini, theta) error_list.append(cost(X_mini, y_mini, theta)) return theta, error_list
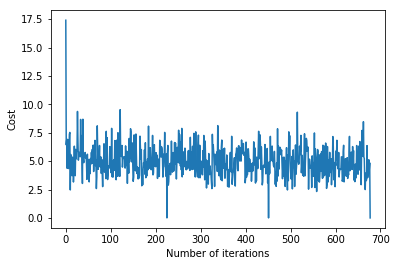
Llamar a la función gradientDescent() para calcular los parámetros del modelo (theta) y visualizar el cambio en la función de error.
Python3
theta, error_list = gradientDescent(X_train, y_train)
print("Bias = ", theta[0])
print("Coefficients = ", theta[1:])
# visualising gradient descent
plt.plot(error_list)
plt.xlabel("Number of iterations")
plt.ylabel("Cost")
plt.show()
Salida: Sesgo = [0,81830471] Coeficientes = [[1,04586595]]
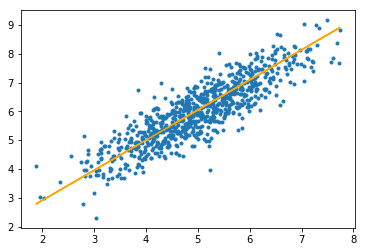
Paso #3: Finalmente, hacemos predicciones sobre el conjunto de prueba y calculamos el error absoluto medio en las predicciones.
Python3
# predicting output for X_test y_pred = hypothesis(X_test, theta) plt.scatter(X_test[:, 1], y_test[:, ], marker='.') plt.plot(X_test[:, 1], y_pred, color='orange') plt.show() # calculating error in predictions error = np.sum(np.abs(y_test - y_pred) / y_test.shape[0]) print(& quot Mean absolute error = & quot , error)
Producción:
Error absoluto medio = 0,4366644295854125
La línea naranja representa la función de hipótesis final: theta[0] + theta[1]*X_test[:, 1] + theta[2]*X_test[:, 2] = 0
Publicación traducida automáticamente
Artículo escrito por savyakhosla y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA