Requisitos previos: regularización L2 y L1
Este artículo tiene como objetivo implementar la regularización L2 y L1 para la regresión lineal utilizando los módulos Ridge y Lasso de la biblioteca Sklearn de Python.
Conjunto de datos: conjunto de datos de precios de la vivienda .
Paso 1: Importación de las bibliotecas requeridas
Python3
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.linear_model import LinearRegression, Ridge, Lasso from sklearn.model_selection import train_test_split, cross_val_score from statistics import mean
Paso 2: Cargar y limpiar los datos
Python3
# Changing the working location to the location of the data
cd C:\Users\Dev\Desktop\Kaggle\House Prices
# Loading the data into a Pandas DataFrame
data = pd.read_csv('kc_house_data.csv')
# Dropping the numerically non-sensical variables
dropColumns = ['id', 'date', 'zipcode']
data = data.drop(dropColumns, axis = 1)
# Separating the dependent and independent variables
y = data['price']
X = data.drop('price', axis = 1)
# Dividing the data into training and testing set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25)
Paso 3: Construcción y evaluación de los diferentes modelos
a) Regresión lineal:
Python3
# Building and fitting the Linear Regression model linearModel = LinearRegression() linearModel.fit(X_train, y_train) # Evaluating the Linear Regression model print(linearModel.score(X_test, y_test))
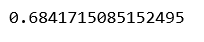
b ) Regresión de la cresta (L2):
Python3
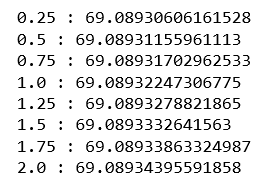
# List to maintain the different cross-validation scores cross_val_scores_ridge = [] # List to maintain the different values of alpha alpha = [] # Loop to compute the different values of cross-validation scores for i in range(1, 9): ridgeModel = Ridge(alpha = i * 0.25) ridgeModel.fit(X_train, y_train) scores = cross_val_score(ridgeModel, X, y, cv = 10) avg_cross_val_score = mean(scores)*100 cross_val_scores_ridge.append(avg_cross_val_score) alpha.append(i * 0.25) # Loop to print the different values of cross-validation scores for i in range(0, len(alpha)): print(str(alpha[i])+' : '+str(cross_val_scores_ridge[i]))

Del resultado anterior, podemos concluir que el mejor valor de alfa para los datos es 2.
Python3
# Building and fitting the Ridge Regression model ridgeModelChosen = Ridge(alpha = 2) ridgeModelChosen.fit(X_train, y_train) # Evaluating the Ridge Regression model print(ridgeModelChosen.score(X_test, y_test))

c ) Regresión Lasso(L1):
Python3
# List to maintain the cross-validation scores cross_val_scores_lasso = [] # List to maintain the different values of Lambda Lambda = [] # Loop to compute the cross-validation scores for i in range(1, 9): lassoModel = Lasso(alpha = i * 0.25, tol = 0.0925) lassoModel.fit(X_train, y_train) scores = cross_val_score(lassoModel, X, y, cv = 10) avg_cross_val_score = mean(scores)*100 cross_val_scores_lasso.append(avg_cross_val_score) Lambda.append(i * 0.25) # Loop to print the different values of cross-validation scores for i in range(0, len(alpha)): print(str(alpha[i])+' : '+str(cross_val_scores_lasso[i]))
Del resultado anterior, podemos concluir que el mejor valor de lambda es 2.
Python3
# Building and fitting the Lasso Regression Model lassoModelChosen = Lasso(alpha = 2, tol = 0.0925) lassoModelChosen.fit(X_train, y_train) # Evaluating the Lasso Regression model print(lassoModelChosen.score(X_test, y_test))
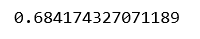
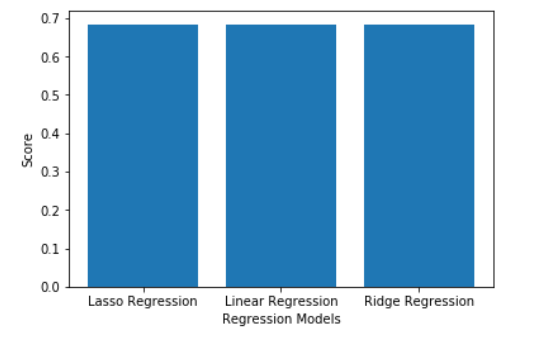
Paso 4: Comparar y visualizar los resultados
Python3
# Building the two lists for visualization
models = ['Linear Regression', 'Ridge Regression', 'Lasso Regression']
scores = [linearModel.score(X_test, y_test),
ridgeModelChosen.score(X_test, y_test),
lassoModelChosen.score(X_test, y_test)]
# Building the dictionary to compare the scores
mapping = {}
mapping['Linear Regression'] = linearModel.score(X_test, y_test)
mapping['Ridge Regression'] = ridgeModelChosen.score(X_test, y_test)
mapping['Lasso Regression'] = lassoModelChosen.score(X_test, y_test)
# Printing the scores for different models
for key, val in mapping.items():
print(str(key)+' : '+str(val))

Python3
# Plotting the scores
plt.bar(models, scores)
plt.xlabel('Regression Models')
plt.ylabel('Score')
plt.show()
Publicación traducida automáticamente
Artículo escrito por AlindGupta y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA