En Machine Learning y Data Science, uno de los trabajos más difíciles es comprender los datos sin procesar y adaptarlos para aplicar diferentes modelos sobre ellos para hacer predicciones. Para fines de comprensión, utilizamos diferentes procesos, como verificar cifras estadísticas como la media, la mediana, la moda, encontrar la relación entre características, observar la distribución de ciertas características, etc. Todo esto a menudo se clasifica bajo el término Análisis exploratorio de datos. (EDA) . Según los profesionales experimentados de ML y DS, EDA es una de las tareas más valiosas y su importancia no puede pasarse por alto cuando se trata de analizar el conjunto de datos. Ayuda a los profesionales a elegir las técnicas de preprocesamiento de datos adecuadas.
Verificar las cifras estadísticas está muy bien, pero qué es mejor que visualizar estas estadísticas pictóricamente, a menudo se dice que las imágenes son una herramienta más poderosa para comprender en lugar de solo cifras numéricas. Podemos llegar a una comprensión más clara de los datos visualmente haciendo diferentes gráficos. En el aprendizaje automático y la ciencia de datos, utilizamos diferentes tipos de gráficos/gráficos para visualizar diferentes patrones entre las funciones, algunas de las cuales son: Histograma, gráficos de barras, gráficos de caja, gráficos de pares, gráficos circulares, gráficos de violín, etc. Pero escribir Los códigos manualmente para todas estas parcelas/gráficos pueden parecer un proceso agotador y también somos más propensos a imprecisiones y errores/errores en el código. Entonces, aquí viene nuestro salvavidas, un paquete de python que realiza las tareas de trazar estos gráficos de manera fácil y eficiente sin tales errores en el código.
En este artículo, leeremos sobre la creación de diagramas/gráficos interactivos utilizando el paquete pywedge python. Pywedge es un paquete de Python de código abierto que se puede usar para automatizar la mayor parte de la tarea de resolución de problemas de aprendizaje automático. También nos ofrece funciones para trazar gráficos interactivos utilizando tan solo unas pocas líneas de código.
La biblioteca Pywedge tiene un método make_charts que nos ofrece crear 8 tipos diferentes de gráficos que se nombran de la siguiente manera:
- Gráfico de dispersión
- Gráfico circular
- Parcela de barra
- Trama de violín
- diagrama de caja
- Parcela de distribución
- Histograma
- Gráfica de correlación
Veamos un ejemplo de cómo podemos usar la biblioteca pywedge para dibujar gráficos interactivos:
Importación de bibliotecas y carga del conjunto de datos:
Python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
df = pd.read_csv("https://www.shortto.com/WineDataset",sep=";")
Después de cargar el conjunto de datos, veremos cómo se ve el conjunto de datos, esto se puede ver usando el método head para imprimir las 5 filas superiores en el conjunto de datos:
Python
df.head()

Python
print("Shape of our dataframe is: ",df.shape)
Shape of our dataframe is: (1599, 12)
Entonces, como podemos notar, tenemos un total de 1599 filas y 11 características en el conjunto de datos junto con una característica objetivo llamada ‘calidad’.
Siempre es mejor revisar algunas estadísticas sobre nuestro conjunto de datos y podemos hacerlo usando el método describe() como:
Python
df.describe()
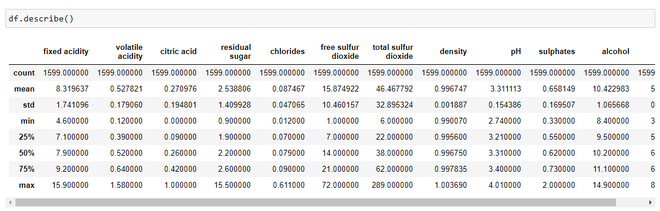
Estadísticas sobre el conjunto de datos
Mirando solo las estadísticas, podemos inferir
- El valor medio es mayor que el valor de la mediana en cada una de las columnas, por ejemplo, el valor medio del pH es 3,311113 mientras que el valor de la mediana es 3,310000. De manera similar, la media del alcohol es 10,422 en comparación con la mediana que es 10,20.
- Podemos notar una gran diferencia entre el valor del percentil 75 y los valores máximos de los predictores «azúcar residual», «dirust de azufre libre», «dirust de azufre total». Esto indica que algunos valores de estas 3 variables se encuentran mucho más alejados del rango general de valores (hasta el 75.º porcentaje). Por lo tanto, podemos concluir que hay valores extremos, es decir, valores atípicos en nuestro conjunto de datos.
Cambio de nombre de la columna y división del conjunto de datos:
Python
df.rename(columns={'ficxed acidity':'fixed_acidity','citric acid':'citric_acid',
'volatile acidity':'volatile_acidity','residual sugar':'residual_sugar',
'free sulphur dioxide':'free_sulphur_dioxide',
'total sulphur dioxide': 'total_sulphur_dioxide'},inplace=True)
# Splitting data into features and labels set
X = df.iloc[:,:11]
y = df.iloc[:,-1]
Usando la biblioteca Pywedge para hacer gráficos:
Python
import pywedge as pw charts = pw.Pywedge_Charts(df, c=None, y = 'quality') # Calling the make_charts method plots = charts.make_charts()
El método ‘make_charts’ en la ejecución produce una ventana que nos brinda 8 tipos diferentes de opciones de gráficos y podemos seleccionar las funciones requeridas para trazar el gráfico y visualizar los resultados.
Haciendo un diagrama de dispersión:
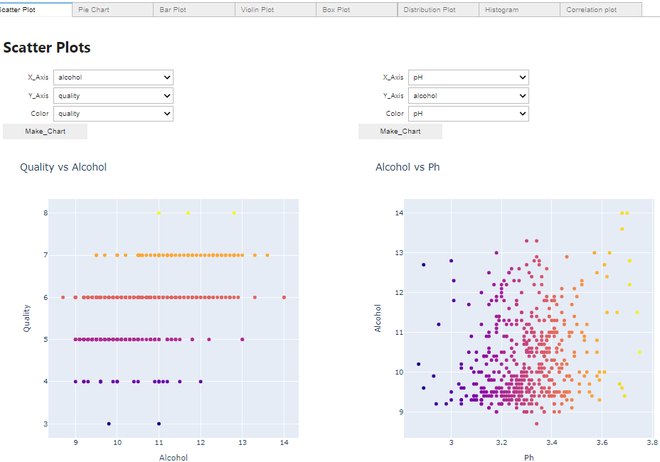
Gráfico de dispersión
Haciendo una trama de violín:
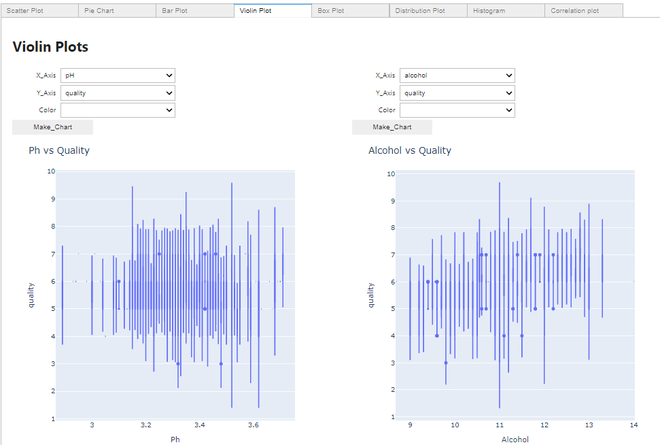
Trama de violín
Hacer un gráfico de distribución:
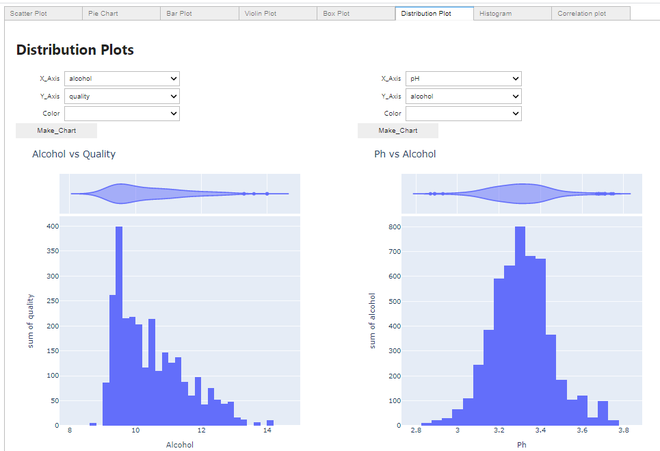
Parcela de distribución
Haciendo un histograma:
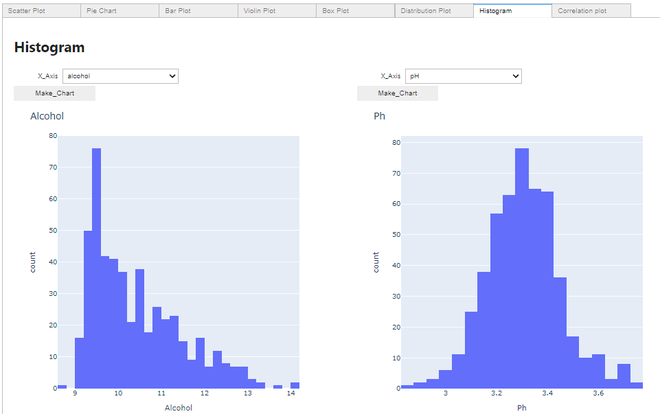
Histograma
Hacer un gráfico de correlación:
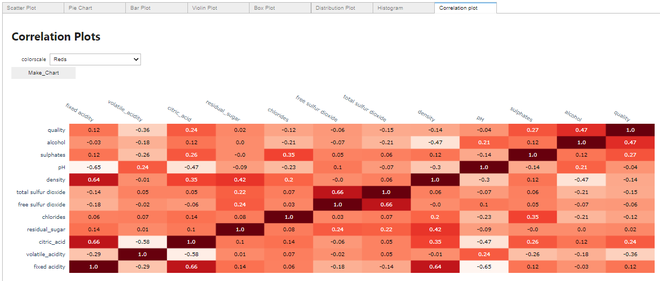
Gráfica de correlación
Por lo tanto, podemos ver cuán eficientemente podemos trazar estos diversos gráficos usando solo unas pocas líneas de código usando el paquete pywedge sin escribir códigos explícitamente para todos estos gráficos.
Publicación traducida automáticamente
Artículo escrito por saurabh48782 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA