FaceNet es el nombre del sistema de reconocimiento facial que propusieron los investigadores de Google en 2015 en el documento titulado FaceNet: A Unified Embedding for Face Recognition and Clustering . Logró resultados de vanguardia en muchos conjuntos de datos de reconocimiento facial de referencia, como Labeled Faces in the Wild (LFW) y Youtube Face Database.
Propusieron un enfoque en el que genera un mapeo facial de alta calidad a partir de las imágenes utilizando arquitecturas de aprendizaje profundo como ZF-Net e Inception Network . Luego usó un método llamado triplete loss como función de pérdida para entrenar esta arquitectura. Veamos la arquitectura con más detalle.
La arquitectura es la siguiente:

Arquitectura FaceNet
FaceNet emplea el aprendizaje de extremo a extremo en su arquitectura. Utiliza ZF-Net o Inception Network como su arquitectura subyacente. También agrega varias circunvoluciones 1*1 para disminuir el número de parámetros. Estos modelos de aprendizaje profundo generan una incrustación de la imagen f(x) con la normalización L 2 realizada en ella. Estas incrustaciones luego se pasan a la función de pérdida para calcular la pérdida. El objetivo de esta función de pérdida es hacer que la distancia al cuadrado entre dos incrustaciones de imágenes (independientemente de la condición y la pose de la imagen) de la misma identidad sea pequeña, mientras que la distancia al cuadrado entre dos imágenes de diferentes identidades sea grande. Por lo tanto, una nueva función de pérdida llamada Triplet lossse usa La idea de usar pérdida de triplete en nuestra arquitectura es que ayuda al modelo a imponer un margen entre caras de diferentes identidades.
Pérdida de triplete:
La incrustación de una imagen está representada por f(x) como x  . Esta incrustación tiene forma de vector de tamaño 128 y está normalizada de tal manera que
. Esta incrustación tiene forma de vector de tamaño 128 y está normalizada de tal manera que

Queremos asegurarnos de que la imagen ancla (  ) de una persona esté más cerca de una imagen positiva ( ) (imagen de la misma persona) en comparación con una imagen negativa ( ) (imagen de otra persona), de modo que:
) de una persona esté más cerca de una imagen positiva ( ) (imagen de la misma persona) en comparación con una imagen negativa ( ) (imagen de otra persona), de modo que:


donde  es el margen que se impone para diferenciar entre pares positivos y negativos y
es el margen que se impone para diferenciar entre pares positivos y negativos y  son el espacio de la imagen.
son el espacio de la imagen.
Por lo tanto, la función de pérdida se define de la siguiente manera:
![L = \sum_{i}^{N}\left [ \left \| f\left ( x_i^a \right ) - f\left ( x_i^p \right ) \right \|_{2}^{2} - \left \| f\left ( x_i^a \right ) - f\left ( x_i^n \right ) \right \|_{2}^{2} +\alpha \right ]](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-8b82f356ed725e2724718428e171d0bc_l3.png "Rendered by QuickLaTeX.com")
Cuando entrenamos el modelo, si elegimos trillizos que satisfagan fácilmente la propiedad anterior, no ayudaría a mejorar el entrenamiento del modelo, por lo que es importante tener los trillizos que violen la ecuación anterior.
Selección de trillizos:
Para asegurar un aprendizaje más rápido, necesitamos tomar trillizos que violen la ecuación anterior. Esto significa que, dado  que necesitamos seleccionar trillizos, de modo que
que necesitamos seleccionar trillizos, de modo que  sea máximo y
sea máximo y  mínimo. Es computacionalmente costoso generar tripletes basados en un conjunto de entrenamiento completo. Hay dos métodos para generar trillizos.
mínimo. Es computacionalmente costoso generar tripletes basados en un conjunto de entrenamiento completo. Hay dos métodos para generar trillizos.
- Generar trillizos en cada paso sobre la base de puntos de control anteriores y calcular el mínimo y el máximo
en un subconjunto de datos. - Selección de positivo duro (
 ) y negativo duro ( ) mediante el uso de mínimo y máximo en un mini lote.
) y negativo duro ( ) mediante el uso de mínimo y máximo en un mini lote.

Triplete-pérdida y aprendizaje
Capacitación:
Este modelo se entrena utilizando Stochastic Gradient Descent (SGD) con retropropagación y AdaGrad. Este modelo se entrena en un clúster de CPU durante 1k-2k horas . La disminución constante de la pérdida (y el aumento de la precisión) se observó después de 500 horas de entrenamiento. Este modelo se entrena utilizando dos redes:
- ZF-Net: La siguiente visualización indica las diferentes capas de ZF-Net utilizadas en esta arquitectura con su requisito de memoria:

Arquitectura ZF-Net en FaceNet
Como notamos, hay 140 millones de parámetros en la arquitectura y se requieren 1600 millones de FLOPS de memoria para entrenar este modelo.
Red de inicio:
La siguiente visualización indica las diferentes capas del modelo Inception utilizadas en esta arquitectura con su requisito de memoria:
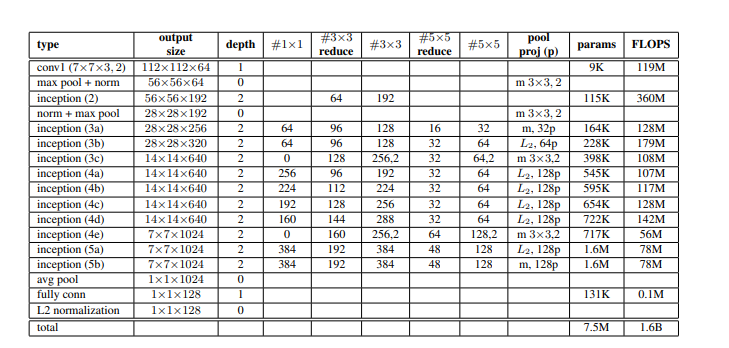
Arquitectura de inicio utilizada en FaceNet
- Como notamos que solo hay 7,5 millones de parámetros en la arquitectura, pero se requieren 1,6 mil millones de FLOPS de memoria para entrenar este modelo (que es similar a ZF-Net).
Resultados: este modelo utiliza 4 tipos diferentes de arquitectura en Labeled Faces in the wild y el conjunto de datos Youtube Face DB.
Rostros etiquetados en el conjunto de datos salvaje:
Esta arquitectura utiliza un protocolo estándar no restringido en el conjunto de datos LFW. En primer lugar, este modelo utiliza 9 divisiones de entrenamiento para establecer el valor del umbral de distancia L 2 y luego, en la décima división, clasifica las dos imágenes como iguales o diferentes .
Hay dos métodos de preprocesamiento de las imágenes del conjunto de datos sobre los que se informa la precisión:
- Recorte central fijo de la imagen proporcionada en LFW
- Se usa un detector de rostros en las imágenes LFW si eso falla, entonces se usa la alineación de rostros LFW
Este modelo logra una precisión de clasificación de 98,87% de precisión con 0,15% de error estándar y en el segundo caso 99,63% de precisión con 0,09% de error estándar. Esto reduce la tasa de error informada por DeepFace en un factor de más de 7 y otros DeepId de última generación en un 30 % .
Base de datos de rostros de Youtube:
En Youtube Face Dataset informó una precisión del 95,12 % con un error estándar de 0,39 utilizando los primeros 100 fotogramas. Es mejor que el 91,4 % de precisión propuesto por DeepFace y el 93,5 % informado por DeepId en 100 fotogramas.

Agrupación de rostros usando FaceNet
Un resultado de Face clustering (agrupación de imágenes de la misma persona) del papel FaceNet muestra que el modelo es invariable a la oclusión, la pose, la iluminación e incluso la edad, etc.
Referencias: papel FaceNet