Support Vector Machine (SVM) es un algoritmo de aprendizaje automático supervisado que se utiliza tanto para la clasificación como para la regresión. Aunque decimos que los problemas de regresión también son los más adecuados para la clasificación. El objetivo del algoritmo SVM es encontrar un hiperplano en un espacio N-dimensional que clasifique claramente los puntos de datos. La dimensión del hiperplano depende del número de características. Si el número de entidades de entrada es dos, entonces el hiperplano es solo una línea. Si el número de entidades de entrada es tres, el hiperplano se convierte en un plano 2D. Se vuelve difícil de imaginar cuando el número de funciones supera las tres.
Consideremos dos variables independientes x1, x2 y una variable dependiente que es un círculo azul o un círculo rojo.
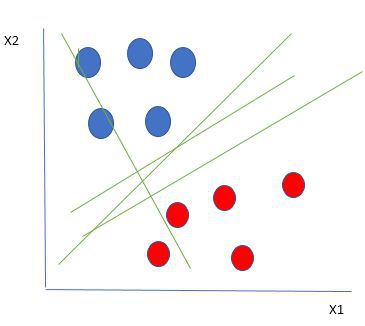
Puntos de datos linealmente separables
De la figura anterior queda muy claro que hay múltiples líneas (nuestro hiperplano aquí es una línea porque estamos considerando solo dos características de entrada x1, x2) que segregan nuestros puntos de datos o clasifican entre círculos rojos y azules. Entonces, ¿cómo elegimos la mejor línea o, en general, el mejor hiperplano que segrega nuestros puntos de datos?
Selección del mejor hiperavión:
Una elección razonable como mejor hiperplano es la que representa la mayor separación o margen entre las dos clases.
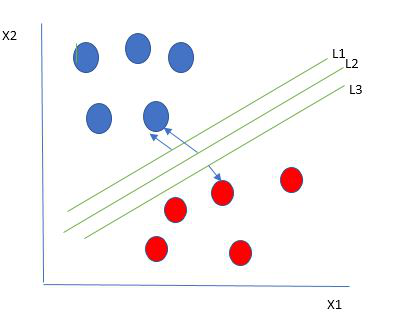
Entonces, elegimos el hiperplano cuya distancia desde él hasta el punto de datos más cercano en cada lado se maximiza. Si tal hiperplano existe, se conoce como hiperplano de margen máximo/margen rígido. Entonces, de la figura anterior, elegimos L2.
Consideremos un escenario como el que se muestra a continuación
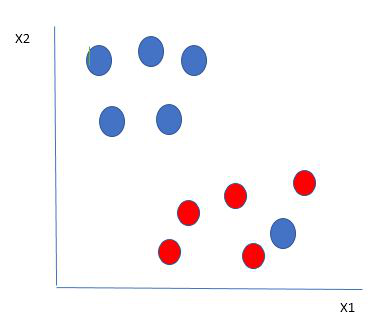
Aquí tenemos una bola azul en el límite de la bola roja. Entonces, ¿cómo clasifica SVM los datos? ¡Es simple! La bola azul en el límite de las rojas es un valor atípico de las bolas azules. El algoritmo SVM tiene las características de ignorar el valor atípico y encuentra el mejor hiperplano que maximiza el margen. SVM es robusto a los valores atípicos.
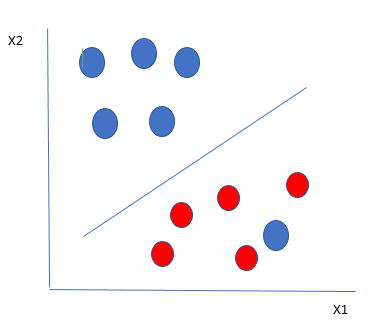
Entonces, en este tipo de puntos de datos, lo que hace SVM es encontrar el margen máximo como se hizo con los conjuntos de datos anteriores y agrega una penalización cada vez que un punto cruza el margen. Entonces, los márgenes en este tipo de casos se llaman margen suave. Cuando hay un margen suave para el conjunto de datos, SVM intenta minimizar (1/margin+∧(∑penalty)) . La pérdida de bisagra es una penalización comúnmente utilizada. Si no hay violaciones, no hay pérdida de bisagra. Si hay violaciones, la pérdida de bisagra es proporcional a la distancia de la violación.
Hasta ahora, hablábamos de datos linealmente separables (el grupo de bolas azules y bolas rojas son separables por una línea recta/línea lineal). ¿Qué hacer si los datos no son linealmente separables?
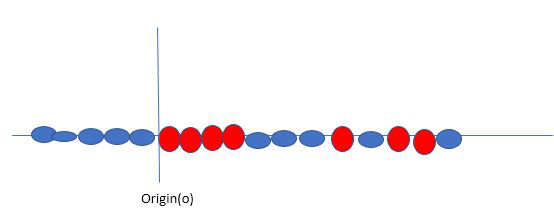
Digamos que nuestros datos son como se muestran en la figura anterior. SVM resuelve esto creando una nueva variable usando un kernel. Llamamos a un punto x i en la línea y creamos una nueva variable y i en función de la distancia desde el origen o. Entonces, si trazamos esto, obtenemos algo como lo que se muestra a continuación.
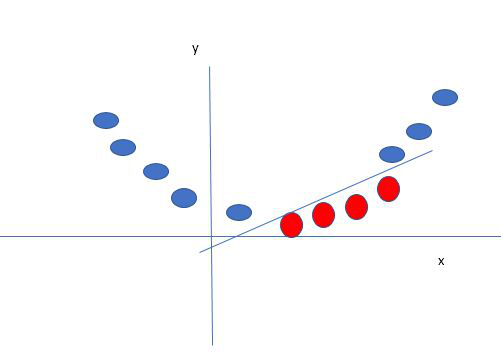
En este caso, la nueva variable y se crea en función de la distancia desde el origen. Una función no lineal que crea una nueva variable se conoce como kernel.
Núcleo SVM:
El núcleo SVM es una función que toma un espacio de entrada de baja dimensión y lo transforma en un espacio de mayor dimensión, es decir, convierte un problema no separable en un problema separable. Es principalmente útil en problemas de separación no lineal. Simplemente ponga el kernel, hace algunas transformaciones de datos extremadamente complejas y luego descubre el proceso para separar los datos en función de las etiquetas o salidas definidas.
Ventajas de SVM:
- Eficaz en casos de grandes dimensiones.
- Su memoria es eficiente ya que utiliza un subconjunto de puntos de entrenamiento en la función de decisión llamados vectores de soporte.
- Se pueden especificar diferentes funciones del kernel para las funciones de decisión y es posible especificar kernels personalizados
Implementación de SVM en Python:
Objetivo: Predecir si el cáncer es benigno o maligno.
Usando datos históricos sobre pacientes diagnosticados con cáncer, permita a los médicos diferenciar casos malignos y benignos dados los atributos independientes.
Conjunto de datos: https://archive.ics.uci.edu/ml/datasets/Breast+Cancer+Wisconsin+(Original)
Python
# import libraries
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
# Importing Data file
data = pd.read_csv('bc2.csv')
dataset = pd.DataFrame(data)
dataset.columns
Producción:
Index(['ID', 'ClumpThickness', 'Cell Size', 'Cell Shape', 'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Normal Nucleoli', 'Bland Chromatin', 'Mitoses', 'Class'], dtype='object')
Python
dataset.info()
Producción:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 699 entries, 0 to 698 Data columns (total 11 columns): ID 699 non-null int64 ClumpThickness 699 non-null int64 Cell Size 699 non-null int64 Cell Shape 699 non-null int64 Marginal Adhesion 699 non-null int64 Single Epithelial Cell Size 699 non-null int64 Bare Nuclei 699 non-null object Normal Nucleoli 699 non-null int64 Bland Chromatin 699 non-null int64 Mitoses 699 non-null int64 Class 699 non-null int64 dtypes: int64(10), object(1) memory usage: 60.1+ KB
Python
dataset.describe().transpose()
Producción:
| contar | significar | estándar | min | 25% | 50% | 75% | máximo | |
| IDENTIFICACIÓN | 699 | 1.071704e+06 | 617095.729819 | 61634.0 | 870688.5 | 1171710.0 | 1238298.0 | 13454352.0 |
| Espesor del grupo | 699 | 4.417740e+00 | 2.815741 | 1.0 | 2.0 | 4.0 | 6.0 | 10.0 |
| Tamaño de celda | 699.0 | 4.417740e+00 | 2.815741 | 1.0 | 1.0 | 1.0 | 5.0 | 10.0 |
| Forma de celda | 699.0 | 3.134478e+00 | 3.051459 | 1.0 | 1.0 | 1.0 | 5.0 | 10.0 |
| Adhesión marginal | 699.0 | 2.806867e+00 | 2.971913 | 1.0 | 1.0 | 1.0 | 4.0 | 10.0 |
| Tamaño de célula epitelial única | 699.0 | 3.216023e+00 | 2.855379 | 1.0 | 2.0 | 2.0 | 4.0 | 10.0 |
| Nucléolos normales | 699.0 | 3.437768e+00 | 2.214300 | 1.0 | 2.0 | 3.0 | 5.0 | 10.0 |
| cromatina blanda | 699.0 | 2.866953e+00 | 2.438364 | 1.0 | 1.0 | 1.0 | 4.0 | 10.0 |
| mitosis | 699.0 | 1.589413e+00 | 3.053634 | 1.0 | 1.0 | 1.0 | 1.0 | 10.0 |
| clase | 699.0 | 2.689557e+00 | 1.715078 | 2.0 | 2.0 | 2.0 | 4.0 | 4.0 |
Python
dataset = dataset.replace('?', np.nan)
dataset = dataset.apply(lambda x: x.fillna(x.median()),axis=0)
# converting the hp column from object 'Bare Nuclei'/ string type to float
dataset['Bare Nuclei'] = dataset['Bare Nuclei'].astype('float64')
dataset.isnull().sum()
Producción:
ID 0 ClumpThickness 0 Cell Size 0 Cell Shape 0 Marginal Adhesion 0 Single Epithelial Cell Size 0 Bare Nuclei 0 Normal Nucleoli 0 Bland Chromatin 0 Mitoses 0 Class 0 dtype: int64
Python
from sklearn.model_selection import train_test_split # To calculate the accuracy score of the model from sklearn.metrics import accuracy_score, confusion_matrix target = dataset["Class"] features = dataset.drop(["ID","Class"], axis=1) X_train, X_test, y_train, y_test = train_test_split(features,target, test_size = 0.2, random_state = 10) from sklearn.svm import SVC # Building a Support Vector Machine on train data svc_model = SVC(C= .1, kernel='linear', gamma= 1) svc_model.fit(X_train, y_train) prediction = svc_model .predict(X_test) # check the accuracy on the training set print(svc_model.score(X_train, y_train)) print(svc_model.score(X_test, y_test))
Producción:
0.9749552772808586 0.9642857142857143
Python
print("Confusion Matrix:\n",confusion_matrix(prediction,y_test))
Producción:
Confusion Matrix: [[95 2] [ 3 40]]
Python
# Building a Support Vector Machine on train data svc_model = SVC(kernel='rbf') svc_model.fit(X_train, y_train)
Producción:
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto_deprecated', kernel='rbf', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)
Python
print(svc_model.score(X_train, y_train)) print(svc_model.score(X_test, y_test))
Producción:
0.998211091234347 0.9571428571428572
Python
#Building a Support Vector Machine on train data(changing the kernel) svc_model = SVC(kernel='poly') svc_model.fit(X_train, y_train) prediction = svc_model.predict(X_test) print(svc_model.score(X_train, y_train)) print(svc_model.score(X_test, y_test))
Producción:
1.0 0.9357142857142857
Python
svc_model = SVC(kernel='sigmoid') svc_model.fit(X_train, y_train) prediction = svc_model.predict(X_test) print(svc_model.score(X_train, y_train)) print(svc_model.score(X_test, y_test))
Producción:
0.3434704830053667 0.32857142857142857
Publicación traducida automáticamente
Artículo escrito por aswathisasidharan y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA