DATOS: Puede ser cualquier hecho, valor, texto, sonido o imagen sin procesar que no está siendo interpretado y analizado. Los datos son la parte más importante de todos los análisis de datos, aprendizaje automático e inteligencia artificial. Sin datos, no podemos entrenar ningún modelo y toda la investigación y automatización modernas serán en vano. Las grandes empresas están gastando mucho dinero solo para recopilar la mayor cantidad posible de datos.
Ejemplo: ¿Por qué Facebook adquirió WhatsApp pagando un precio enorme de $19 mil millones?
La respuesta es muy simple y lógica, es tener acceso a la información de los usuarios que quizás Facebook no tenga pero sí WhatsApp. Esta información de sus usuarios es de suma importancia para Facebook ya que le facilitará la tarea de mejora en sus servicios.
INFORMACIÓN: Datos que han sido interpretados y manipulados y ahora tienen alguna inferencia significativa para los usuarios.
CONOCIMIENTO: Combinación de información inferida, experiencias, aprendizaje e ideas. Da como resultado la creación de conciencia o concepto para un individuo u organización.

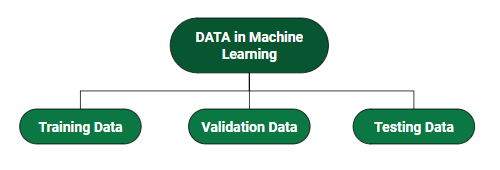
¿Cómo dividimos los datos en Machine Learning?
- Datos de entrenamiento: la parte de los datos que usamos para entrenar nuestro modelo. Estos son los datos que su modelo realmente ve (tanto de entrada como de salida) y de los que aprende.
- Datos de validación: la parte de los datos que se utiliza para realizar una evaluación frecuente del modelo, encajar en el conjunto de datos de entrenamiento junto con la mejora de los hiperparámetros involucrados (establecer inicialmente los parámetros antes de que el modelo comience a aprender). Estos datos juegan su papel cuando el modelo está realmente entrenando.
- Datos de prueba: una vez que nuestro modelo está completamente entrenado, los datos de prueba proporcionan una evaluación imparcial. Cuando ingresamos las entradas de los datos de prueba, nuestro modelo predecirá algunos valores (sin ver la salida real). Después de la predicción, evaluamos nuestro modelo comparándolo con el resultado real presente en los datos de prueba. Así es como evaluamos y vemos cuánto ha aprendido nuestro modelo de las experiencias que se alimentan como datos de entrenamiento, establecidos en el momento del entrenamiento.
Considere un ejemplo:
hay un propietario de un centro comercial que realizó una encuesta para la cual tiene una larga lista de preguntas y respuestas que les había pedido a los clientes, esta lista de preguntas y respuestas es DATOS . Ahora, cada vez que quiere inferir algo y no puede simplemente revisar todas y cada una de las preguntas de miles de clientes para encontrar algo relevante, ya que llevaría mucho tiempo y no sería útil. Con el fin de reducir esta sobrecarga y pérdida de tiempo y facilitar el trabajo, los datos se manipulan a través de software, cálculos, gráficos, etc. Según su propia conveniencia, esta inferencia a partir de datos manipulados es Información . Por lo tanto, los datos son imprescindibles para la información. Ahora conocimientotiene su papel en la diferenciación entre dos individuos que tienen la misma información. El conocimiento en realidad no es un contenido técnico, sino que está vinculado al proceso de pensamiento humano.
Diferentes formas de datos
- Datos numéricos : si una característica representa una característica medida en números, se denomina característica numérica.
- Datos categóricos: Una característica categórica es un atributo que puede tomar uno de los valores posibles limitados, y generalmente fijos, sobre la base de alguna propiedad cualitativa. Una característica categórica también se denomina característica nominal.
- Datos ordinales : Esto denota una variable nominal con categorías que caen en una lista ordenada. Los ejemplos incluyen tallas de ropa como pequeña, mediana y grande, o una medida de la satisfacción del cliente en una escala de «nada contento» a «muy contento».
Propiedades de los datos –
- Volumen: Escala de Datos. Con la creciente población mundial y la tecnología expuesta, se generan enormes datos cada milisegundo.
- Variedad: diferentes formas de datos: atención médica, imágenes, videos, recortes de audio.
- Velocidad: tasa de transmisión y generación de datos.
- Valor: Significado de los datos en términos de información que los investigadores pueden inferir de ellos.
- Veracidad: Certeza y corrección en los datos que estamos trabajando.
Algunos datos sobre los datos:
- En comparación con 2005, se generarán 300 veces, es decir, 40 Zettabytes (1ZB=10^21 bytes) de datos para 2020.
- Para el 2011, el sector salud tiene un dato de 161 Billones de Gigabytes
- 400 millones de tweets son enviados por unos 200 millones de usuarios activos por día
- Cada mes, los usuarios realizan más de 4 mil millones de horas de transmisión de video.
- El usuario comparte cada mes 30 mil millones de tipos diferentes de contenido.
- Se informa que alrededor del 27 % de los datos son inexactos y, por lo tanto, 1 de cada 3 idealistas o líderes empresariales no confía en la información sobre la que toma decisiones.
Los hechos mencionados anteriormente son solo un vistazo de las enormes estadísticas de datos realmente existentes. Cuando hablamos en términos de escenarios del mundo real, el tamaño de los datos que se presentan actualmente y se generan en cada momento está más allá de nuestros horizontes mentales para imaginar.
Publicación traducida automáticamente
Artículo escrito por Mohit Gupta_OMG 🙂 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA