En este artículo, haremos un proyecto a través del lenguaje Python que también utilizará algunos algoritmos de aprendizaje automático. Será emocionante ya que después de este proyecto comprenderá los conceptos del uso de AI y ML con un lenguaje de secuencias de comandos. Las siguientes bibliotecas/paquetes se utilizarán en este proyecto:
- numpy : es una biblioteca de Python que se emplea para la computación científica. Contiene, entre otras cosas, un sólido objeto de array, herramientas matemáticas y estadísticas para la integración con el código de otros lenguajes, es decir, código C/C++ y Fortran.
- pandas : es un paquete de Python que proporciona estructuras de datos rápidas, flexibles y expresivas diseñadas para trabajar con datos «relacionales» o «etiquetados» de forma fácil e intuitiva.
- matplotlib : Matplotlib es una biblioteca de gráficos para el lenguaje de programación Python que produce gráficos 2D para representar la visualización y ayuda a explorar los conjuntos de información. matplotlib.pyplot podría ser una colección de funciones de estilo de comando que hacen que matplotlib funcione como MATLAB.
- nacido del mar : . Seaborn es una biblioteca Python de código abierto construida sobre matplotlib. Se utiliza para la visualización de datos y el análisis exploratorio de datos. Seaborn funciona fácilmente con marcos de datos y también con la biblioteca Pandas.
Python3
# Checking for any warning
import warnings
warnings.filterwarnings('ignore')
Después de este paso, instalaremos algunas dependencias : Las dependencias son todos los componentes de software requeridos por su proyecto para que funcione según lo previsto y evite errores de tiempo de ejecución. Necesitaremos las bibliotecas/dependencias numpy, pandas, matplotlib y seaborn. Como necesitaremos un archivo CSV para realizar las operaciones, para este proyecto usaremos un archivo CSV que contiene datos de Tumor (enfermedad cerebral). Entonces, en este proyecto, por fin, seremos capaces de predecir si un sujeto (candidato) tiene una gran posibilidad de sufrir un tumor o no.
Paso 1: preprocesamiento de los datos:
Python3
# Importing dependencies
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Including & Reading the CSV file:
df = pd.read_csv("https://raw.githubusercontent.com/ingledarshan/AIML-B2/main/data.csv")
Ahora comprobaremos que el archivo CSV se ha leído correctamente o no. Así que usaremos el método head : el método head() se usa para devolver las primeras n (5 por defecto) filas de un marco de datos o serie.
Python3
df.head()
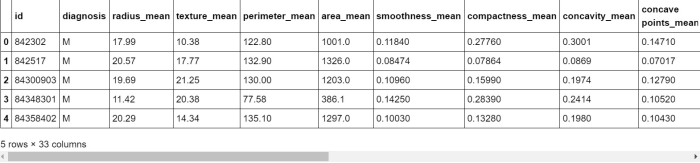
Python3
# Check the names of all columns df.columns
Entonces este comando obtendrá los nombres de encabezado de la columna. La salida será esta:

Ahora, para comprender brevemente el conjunto de datos al obtener una descripción general rápida del conjunto de datos, usaremos el método info(). Este método maneja muy bien el análisis exploratorio de los conjuntos de datos.
Python3
df.info()
Salida para el comando anterior:

En el archivo CSV, puede haber algunos campos en blanco que pueden dañar el proyecto (es decir, dificultarán la predicción).
Python3
df['Unnamed: 32']
Producción:
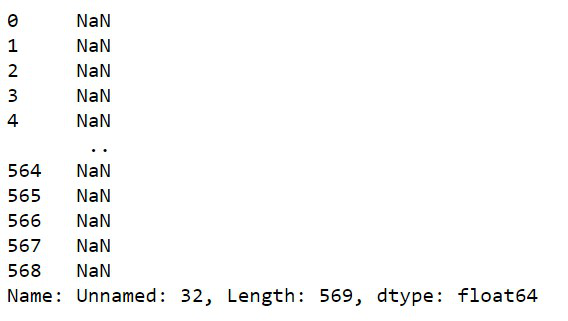
Ahora que hemos encontrado con éxito los espacios vacantes en el conjunto de datos, ahora los eliminaremos.
Python3
df = df.drop("Unnamed: 32", axis=1)
# to check whether those values are
# deleted or not:
df.head()
# also check the columns after this
# process:
df.columns
df.drop('id', axis=1, inplace=True)
# we can do this also: df = df.drop('id', axis=1)
# To see the change, again go through
# the columns
df.columns
Ahora comprobaremos el tipo de clase de las columnas con la ayuda del método type(). Devuelve el tipo de clase del argumento (objeto) pasado como parámetro.
Python3
type(df.columns)
Producción:
pandas.core.indexes.base.Index
Tendremos que recorrer y ordenar los datos por sus columnas, por lo que guardaremos las columnas en una variable.
Python3
l = list(df.columns) print(l)
Ahora accederemos a los datos con diferentes puntos de inicio. Digamos que categorizaremos las columnas del 1 al 11 en una variable llamada características_promedio y así sucesivamente.
Python3
features_mean = l[1:11] features_se = l[11:21] features_worst = l[21:]

Python3
df.head (2)

En la columna ‘Diagnóstico’ del archivo CSV, hay dos opciones, una es M = Maligno y B = Comenzar , que básicamente indica la etapa del Tumor. Pero lo mismo vamos a verificar desde el código.
Python3
# To check what value does the Diagnosis field have df['diagnosis'].unique() # M stands for Malignant, B stands for Begin
Producción:
array(['M', 'B'], dtype=object)
Entonces verifica que solo hay dos valores en el campo Diagnóstico.
Ahora, para tener una idea clara de cuántos casos tienen tumores malignos y quiénes están en la etapa inicial, usaremos el método countplot().
Python3
sns.countplot(df['diagnosis'], label="Count",);
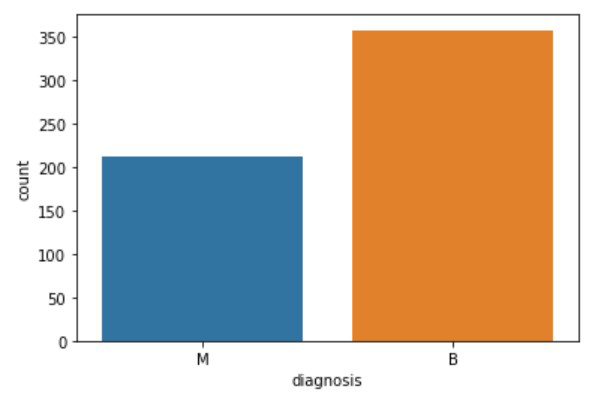
Si no tenemos que ver el gráfico de los valores, entonces puedo usar una función que devolverá los valores numéricos de las ocurrencias.
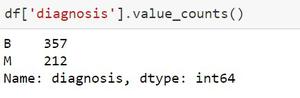
Ahora podremos usar el método shape(). Shape devuelve la forma de una array. La forma podría ser una tupla de enteros. Estos números indican las longitudes de la dimensión de array correspondiente. En otras palabras: la “forma” de una array puede ser una tupla con el número de elementos por eje (dimensión). Por ejemplo, la forma es adecuada a (6, 3), es decir, tenemos 6 líneas y tres columnas.
Python3
df.shape
Producción:
(539, 31)
lo que significa que en el conjunto de datos hay 539 líneas y 31 columnas.
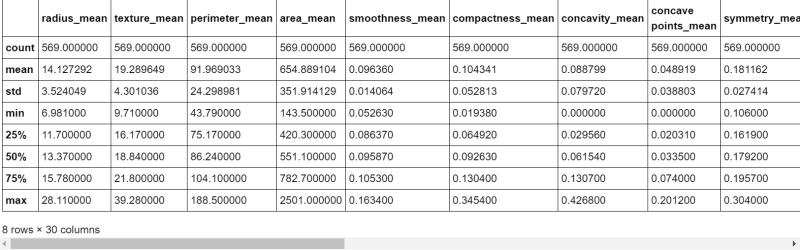
A partir de ahora, estamos listos con el conjunto de datos que se procesará, por lo que podremos usar el método describe() que se emplea para observar algunos detalles estadísticos básicos como percentil, media, std, etc. de un marco de conocimiento o una serie de valores numéricos.
Python3
# Summary of all numeric values df.decsbibe()
Después de todo, estaremos usando el método corr() para encontrar la correlación entre diferentes campos. Corr() se usa para encontrar la correlación por pares de todas las columnas en el marco de datos. Cualquier valor de nan se excluye automáticamente. Para cualquier columna de tipo de datos no numérico en el marco de datos, se ignora.
Python3
# Correlation Plot corr = df.corr() corr
Este comando proporcionará una tabla de 30 filas * 30 columnas que tendrá filas como radius_mean, texture_se, etc.
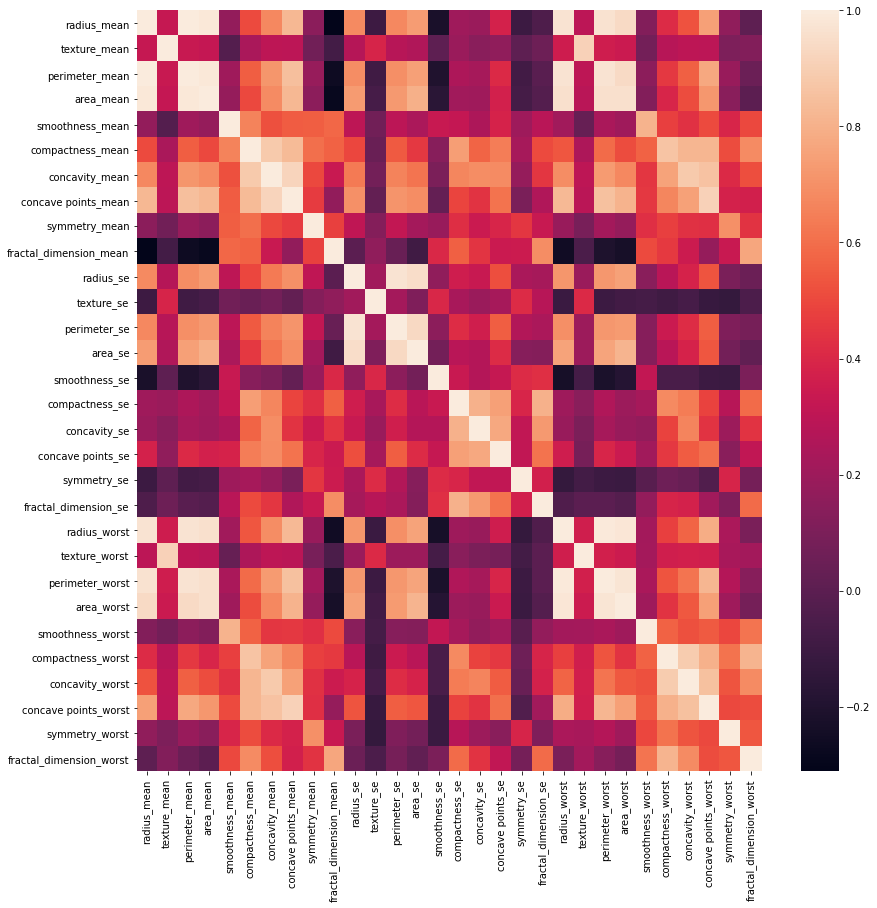
El comando corr.shape( ) devolverá (30, 30). El siguiente paso es trazar las estadísticas a través de un mapa de calor. Un mapa de calor podría incluso ser una representación gráfica bidimensional de información donde los valores individuales que están contenidos en una array se representan como colores. El paquete seaborn permite la creación de mapas de calor anotados que se pueden cambiar un poco usando las herramientas de Matplotlib según los requisitos del creador.
Python3
# making a heatmap plt.figure(figsize=(14, 14)) sns.heatmap(corr)
Nuevamente, revisaremos el conjunto de datos CSV para asegurarnos de que las columnas estén bien y no se hayan visto afectadas por las operaciones.
Python3
df.head()
Esto devolverá una tabla a través de la cual uno puede estar seguro de que el conjunto de datos está bien ordenado o no. En los próximos comandos, estaremos segregando los datos.
Python3
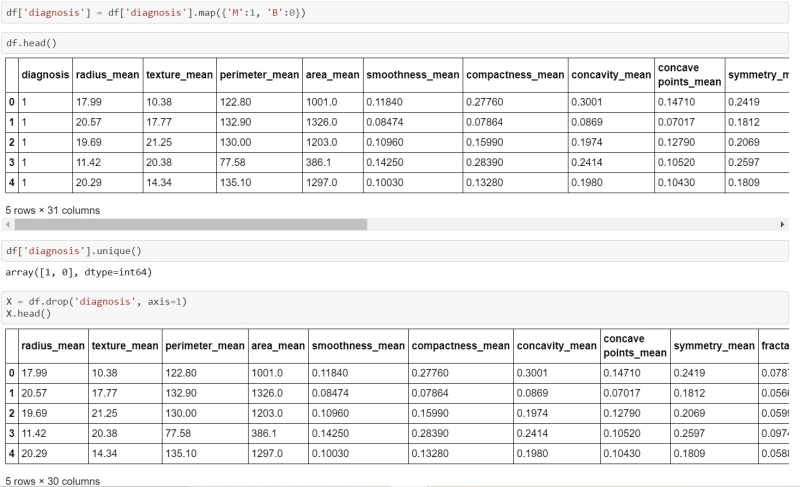
df['diagnosis'] = df['diagnosis'].map({'M': 1, 'B': 0})
df.head()
df['diagnosis'].unique()
X = df.drop('diagnosis', axis=1)
X.head()
y = df['diagnosis']
y.head()
Nota: como hemos preparado un modelo de predicción que se puede usar con cualquiera de los modelos de aprendizaje automático, ahora usaremos uno por uno para mostrarle el resultado del modelo de predicción con cada uno de los algoritmos de aprendizaje automático.
Paso 2: Comprobación de prueba o entrenamiento del conjunto de datos
- Usando el modelo de regresión logística:
Python3
# divide the dataset into train and test set from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) df.shape # o/p: (569, 31) X_train.shape # o/p: (398, 30) X_test.shape # o/p: (171, 30) y_train.shape # o/p: (398,) y_test.shape # o/p: (171,) X_train.head(1) # will return the top 5 rows (if exists) ss = StandardScaler() X_train = ss.fit_transform(X_train) X_test = ss.transform(X_test) X_train
Producción:
Después de realizar el entrenamiento básico del modelo, podemos probarlo utilizando uno de los modelos de aprendizaje automático. Por lo tanto, probaremos esto utilizando Regresión logística, Clasificador de árbol de decisión, Clasificador de bosque aleatorio y SVM.
Python3
# apply Logistic Regression from sklearn.linear_model import LogisticRegression lr = LogisticRegression() lr.fit(X_train, y_train) # implemented our model through logistic regression y_pred = lr.predict(X_test) y_pred # array containing the actual output y_test
Producción:
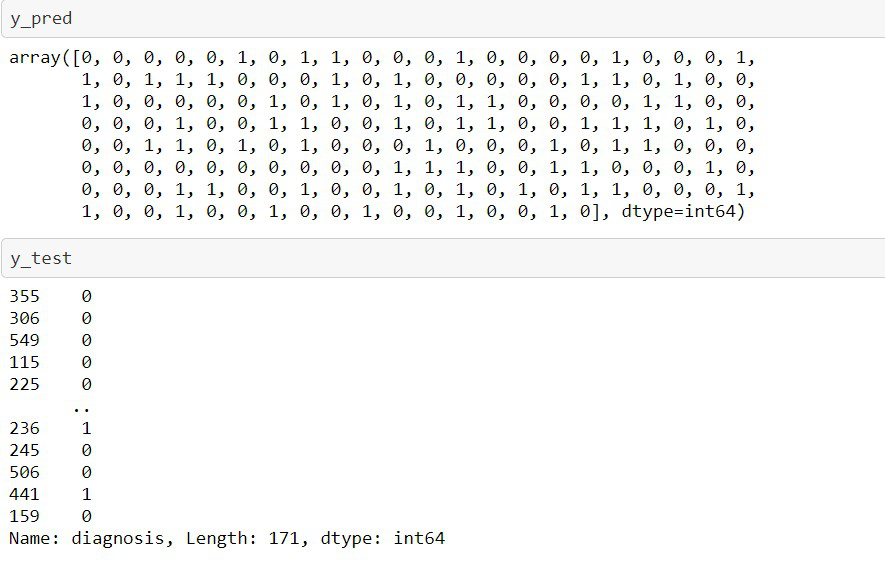
Para comprobar matemáticamente en qué medida el modelo ha predicho el valor correcto:
Python3
from sklearn.metrics import accuracy_score print(accuracy_score(y_test, y_pred))
Producción:
0.9883040935672515
Ahora enmarquemos los resultados en forma de tabla.
Python3
tempResults = pd.DataFrame({'Algorithm':['Logistic Regression Method'], 'Accuracy':[lr_acc]})
results = pd.concat( [results, tempResults] )
results = results[['Algorithm','Accuracy']]
results
Producción:

- Uso del modelo de árbol de decisión:
Python3
# apply Decision Tree Classifier
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
dtc = DecisionTreeClassifier()
dtc.fit(X_train, y_train)
y_pred = dtc.predict(X_test)
y_pred
print(accuracy_score(y_test, y_pred))
# Tabulating the results
tempResults = pd.DataFrame({'Algorithm': ['Decision tree Classifier Method'],
'Accuracy': [dtc_acc]})
results = pd.concat([results, tempResults])
results = results[['Algorithm', 'Accuracy']]
results
Producción:


- Usando el modelo de bosque aleatorio:
Python3
# apply Random Forest Classifier
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
y_pred = rfc.predict(X_test)
y_pred
print(accuracy_score(y_test, y_pred))
# tabulating the results
tempResults = pd.DataFrame({'Algorithm': ['Random Forest Classifier Method'],
'Accuracy': [rfc_acc]})
results = pd.concat([results, tempResults])
results = results[['Algorithm', 'Accuracy']]
results
Producción:

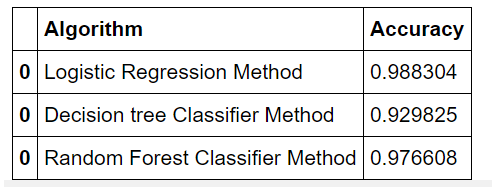
- Usando SVM:
Python3
# apply Support Vector Machine from sklearn import svm svc = svm.SVC() svc.fit(X_train,y_train y_pred = svc.predict(X_test) y_pred from sklearn.metrics import accuracy_score print(accuracy_score(y_test, y_pred))
Producción:

Así que ahora podemos verificar qué modelo efectivamente produjo una mayor cantidad de predicciones correctas a través de esta tabla:
Python3
# Tabulating the results
tempResults = pd.DataFrame({'Algorithm': ['Support Vector Classifier Method'],
'Accuracy': [svc_acc]})
results = pd.concat([results, tempResults])
results = results[['Algorithm', 'Accuracy']]
results
Producción:
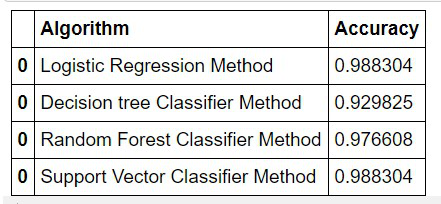
Después de revisar la precisión de los algoritmos de aprendizaje automático utilizados anteriormente, puedo concluir que estos algoritmos darán el mismo resultado cada vez que se alimenta el mismo conjunto de datos. También puedo decir que estos algoritmos proporcionan principalmente el mismo resultado de precisión de predicción, incluso si se cambia el conjunto de datos.
De la tabla anterior, podemos concluir que a través del modelo SVM y el modelo de regresión logística fueron los modelos más adecuados para mi proyecto.
Publicación traducida automáticamente
Artículo escrito por versatile1990 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA