Los datos se transforman de maneras que son ideales para la extracción de datos. La transformación de datos implica pasos que son:
1. Suavizado:
es un proceso que se utiliza para eliminar el ruido del conjunto de datos utilizando algunos algoritmos. Permite resaltar características importantes presentes en el conjunto de datos. Ayuda a predecir los patrones. Al recopilar datos, se pueden manipular para eliminar o reducir cualquier variación o cualquier otra forma de ruido.
El concepto detrás del suavizado de datos es que podrá identificar cambios simples para ayudar a predecir diferentes tendencias y patrones. Esto sirve como una ayuda para los analistas o comerciantes que necesitan ver una gran cantidad de datos que a menudo pueden ser difíciles de digerir para encontrar patrones que de otro modo no verían.
2. Agregación:
la recopilación o agregación de datos es el método de almacenar y presentar datos en un formato de resumen. Los datos se pueden obtener de múltiples fuentes de datos para integrar estas fuentes de datos en una descripción de análisis de datos. Este es un paso crucial ya que la precisión de los conocimientos del análisis de datos depende en gran medida de la cantidad y la calidad de los datos utilizados. Es necesario recopilar datos precisos de alta calidad y en una cantidad suficientemente grande para producir resultados relevantes.
La recopilación de datos es útil para todo, desde decisiones sobre financiamiento o estrategia comercial del producto, fijación de precios, operaciones y estrategias de marketing.
Por ejemplo , los datos de Ventas pueden agregarse para calcular los montos totales mensuales y anuales.
3. Discretización:
Es un proceso de transformación de datos continuos en un conjunto de pequeños intervalos. La mayoría de las actividades de minería de datos en el mundo real requieren atributos continuos. Sin embargo, muchos de los marcos de minería de datos existentes no pueden manejar estos atributos.
Además, incluso si una tarea de minería de datos puede administrar un atributo continuo, puede mejorar significativamente su eficiencia al reemplazar un atributo de calidad constante con sus valores discretos.
Por ejemplo , (1-10, 11-20) (edad: joven, mediana edad, mayor).
4. Construcción de atributos:
donde se crean y aplican nuevos atributos para ayudar al proceso de minería a partir del conjunto de atributos dado. Esto simplifica los datos originales y hace que la minería sea más eficiente.
5. Generalización:
convierte atributos de datos de bajo nivel en atributos de datos de alto nivel utilizando la jerarquía de conceptos. Por ejemplo, la edad inicialmente en forma numérica (22, 25) se convierte en valor categórico (joven, viejo).
Por ejemplo , los atributos categóricos, como direcciones de casas, pueden generalizarse a definiciones de nivel superior, como ciudad o país.
6. Normalización: la normalización de datos implica convertir todas las variables de datos en un rango determinado.
Las técnicas que se utilizan para la normalización son:
- Normalización mín-máx:
- Esto transforma los datos originales linealmente.
- Supongamos que: min_A es el mínimo y max_A es el máximo de un atributo, P
Tenemos la fórmula:

- Donde v es el valor que desea trazar en el nuevo rango.
- v’ es el nuevo valor que obtiene después de normalizar el valor anterior.
Ejemplo resuelto :
suponga que el valor mínimo y máximo para un atributo de beneficio (P) son Rs. 10, 000 y Rs. 100, 000. Queremos trazar la ganancia en el rango [0, 1]. Usando la normalización min-max, el valor de Rs. 20, 000 para el beneficio de atributo se pueden representar en: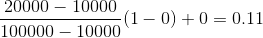
Y por lo tanto, obtenemos el valor de v’ como 0.11
- Normalización de puntuación Z:
- En la normalización de puntuación z (o normalización de media cero), los valores de un atributo (A) se normalizan en función de la media de A y su desviación estándar.
- Un valor, v, del atributo A se normaliza a v’ calculando

Por ejemplo :
Sea la media de un atributo P = 60, 000, Desviación estándar = 10, 000, para el atributo P. Usando la normalización del puntaje z, un valor de 85000 para P se puede transformar en: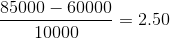
Y por lo tanto obtenemos que el valor de v’ es 2.5
-
Escala decimal:
- Normaliza los valores de un atributo cambiando la posición de sus puntos decimales
- El número de puntos por los que se mueve el punto decimal se puede determinar por el valor máximo absoluto del atributo A.
- Un valor, v, del atributo A se normaliza a v’ calculando
- donde j es el entero más pequeño tal que Max(|v’|) < 1.
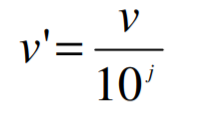
Por ejemplo :
- Supongamos: Los valores de un atributo P varían de -99 a 99.
- El valor absoluto máximo de P es 99.
- Para normalizar los valores, dividimos los números por 100 (es decir, j = 2) o (número de enteros en el número más grande) para que los valores resulten ser 0.98, 0.97 y así sucesivamente.