En el aprendizaje por refuerzo, el agente o el tomador de decisiones genera sus datos de entrenamiento al interactuar con el mundo. El agente debe aprender las consecuencias de sus acciones a través de prueba y error, en lugar de que se le diga explícitamente la acción correcta.
Problema de bandido con múltiples brazos
En el Aprendizaje por Refuerzo, usamos el Problema del Bandido con Armas Múltiples para formalizar la noción de toma de decisiones bajo incertidumbre usando bandidos con brazos k. Un tomador de decisiones o un agente está presente en el Problema del bandido con múltiples brazos para elegir entre k acciones diferentes y recibe una recompensa según la acción que elija. El problema del bandido se utiliza para describir conceptos fundamentales en el aprendizaje por refuerzo, como recompensas, intervalos de tiempo y valores.

La imagen de arriba representa una máquina tragamonedas también conocida como bandido con dos palancas. Suponemos que cada palanca tiene una distribución separada de recompensas y hay al menos una palanca que genera la recompensa máxima.
La distribución de probabilidad de la recompensa correspondiente a cada palanca es diferente y desconocida para el jugador (tomador de decisiones). Por lo tanto, el objetivo aquí es identificar qué palanca tirar para obtener la máxima recompensa después de un conjunto determinado de pruebas.
Por ejemplo:
imagine una prueba de publicidad en línea en la que un anunciante desea medir la tasa de clics de tres anuncios diferentes para el mismo producto. Cada vez que un usuario visita el sitio web, el anunciante muestra un anuncio al azar. Luego, el anunciante supervisa si el usuario hace clic en el anuncio o no. Después de un tiempo, el anunciante nota que un anuncio parece estar funcionando mejor que los demás. El anunciante ahora debe decidir entre quedarse con el anuncio de mejor rendimiento o continuar con el estudio aleatorio.
Si el anunciante solo muestra un anuncio, ya no puede recopilar datos sobre los otros dos anuncios. Tal vez uno de los otros anuncios es mejor, solo parece peor debido al azar. Si los otros dos anuncios son peores, continuar con el estudio puede afectar negativamente la tasa de clics. Este ensayo publicitario ejemplifica la toma de decisiones bajo incertidumbre.
En el ejemplo anterior, el papel del agente lo desempeña un anunciante. El anunciante tiene que elegir entre tres acciones diferentes para mostrar el primer, segundo o tercer anuncio. Cada anuncio es una acción. Elegir ese anuncio produce una recompensa desconocida. Finalmente, la ganancia del anunciante después del anuncio es la recompensa que recibe el anunciante.
Valores de acción:
Para que el anunciante decida qué acción es mejor, debemos definir el valor de realizar cada acción. Definimos estos valores usando la función acción-valor usando el lenguaje de la probabilidad. El valor de seleccionar una acción q * (a) se define como la recompensa esperada R t que recibimos al realizar una acción a del conjunto de acciones posibles.

The goal of the agent is to maximize the expected reward by selecting the action that has the highest action-value.
Estimación del valor de la acción:
Dado que el agente no conoce el valor de seleccionar una acción, es decir, Q * (a) , utilizaremos el método del promedio de la muestra para estimarlo.
Exploración vs Explotación:
- Acción codiciosa : cuando un agente elige una acción que actualmente tiene el mayor valor estimado. El agente explota su conocimiento actual eligiendo la acción codiciosa.
- Acción no codiciosa : cuando el agente no elige el valor estimado más grande y sacrifica la recompensa inmediata con la esperanza de obtener más información sobre las otras acciones.
- Exploración : Permite al agente mejorar su conocimiento sobre cada acción. Con suerte, conducirá a un beneficio a largo plazo.
- Explotación : permite al agente elegir la acción codiciosa para tratar de obtener la mayor recompensa por un beneficio a corto plazo. Una selección de acción puramente codiciosa puede conducir a un comportamiento subóptimo.
Se presenta un dilema entre exploración y explotación porque un agente no puede elegir explorar y explotar al mismo tiempo. Por lo tanto, usamos el algoritmo Upper Confidence Bound para resolver el dilema de exploración-explotación
Selección de acción con límite de confianza superior:
la selección de acción con límite de confianza superior utiliza la incertidumbre en las estimaciones del valor de la acción para equilibrar la exploración y la explotación. Dado que existe una incertidumbre inherente en la precisión de las estimaciones del valor de la acción cuando utilizamos un conjunto de recompensas de muestra, UCB utiliza la incertidumbre en las estimaciones para impulsar la exploración.
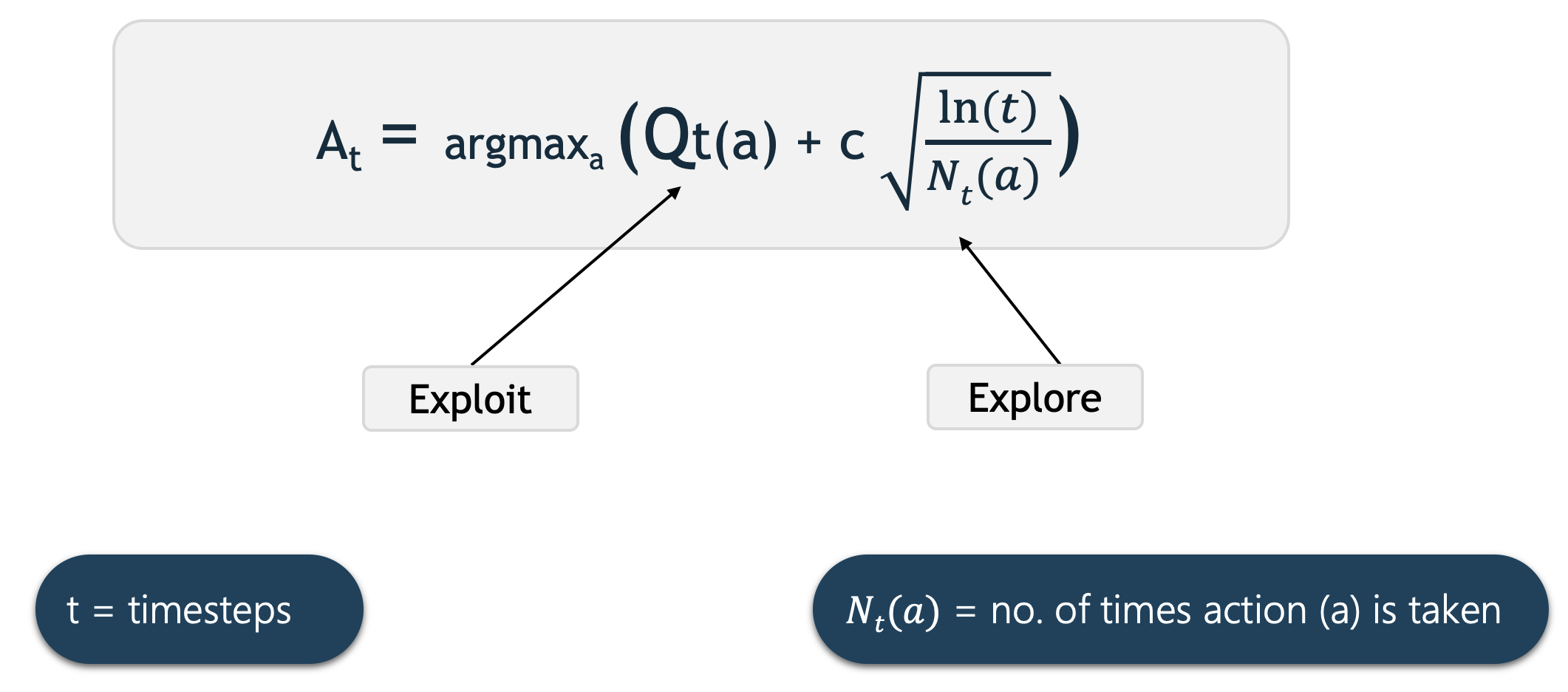
Q t (a) aquí representa la estimación actual para la acción a en el tiempo t . Seleccionamos la acción que tiene el valor de acción estimado más alto más el término de exploración límite de confianza superior.
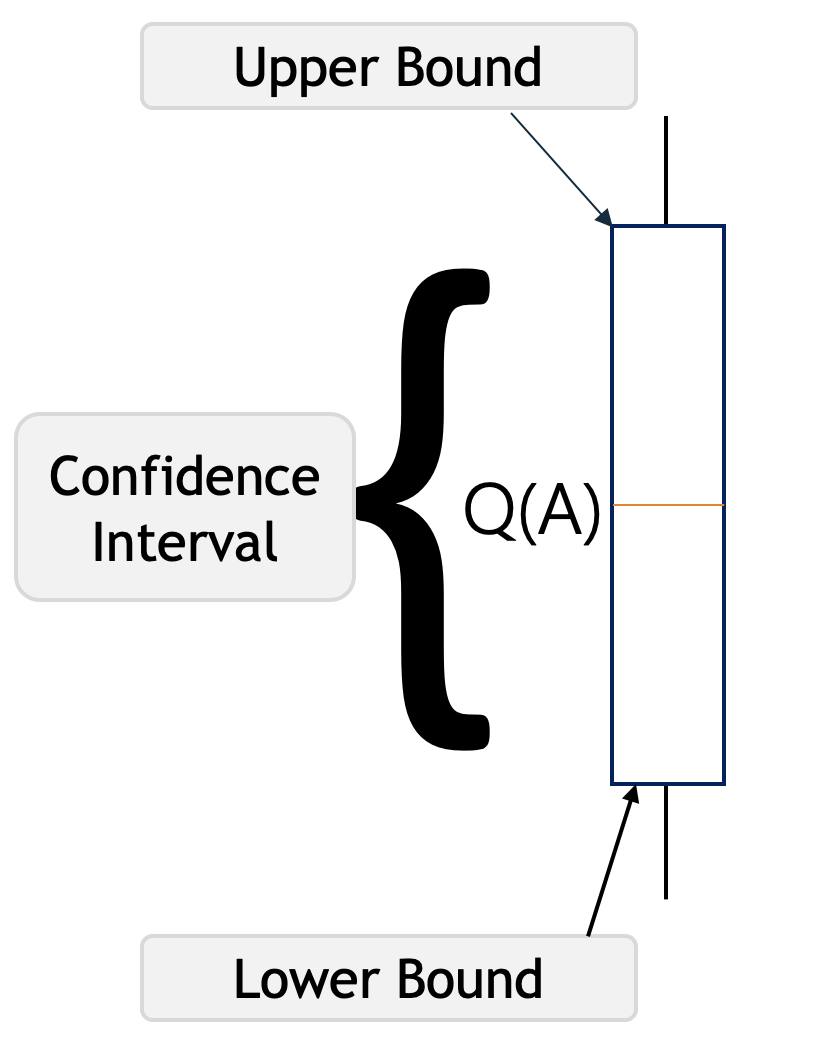
Q(A) en la imagen de arriba representa la estimación actual del valor de la acción para la acción A . Los corchetes representan un intervalo de confianza alrededor de Q * (A) que dice que estamos seguros de que el valor de acción real de la acción A se encuentra en algún lugar de esta región.
El corchete inferior se llama límite inferior y el corchete superior es el límite superior. La región entre paréntesis es el intervalo de confianza que representa la incertidumbre en las estimaciones. Si la región es muy pequeña, entonces estamos muy seguros de que el valor real de la acción A está cerca de nuestro valor estimado. Por otro lado, si la región es grande, no estamos seguros de que el valor de la acción A esté cerca de nuestro valor estimado.
El límite superior de confianza sigue el principio de optimismo frente a la incertidumbre, lo que implica que si no estamos seguros acerca de una acción, debemos asumir con optimismo que es la acción correcta.
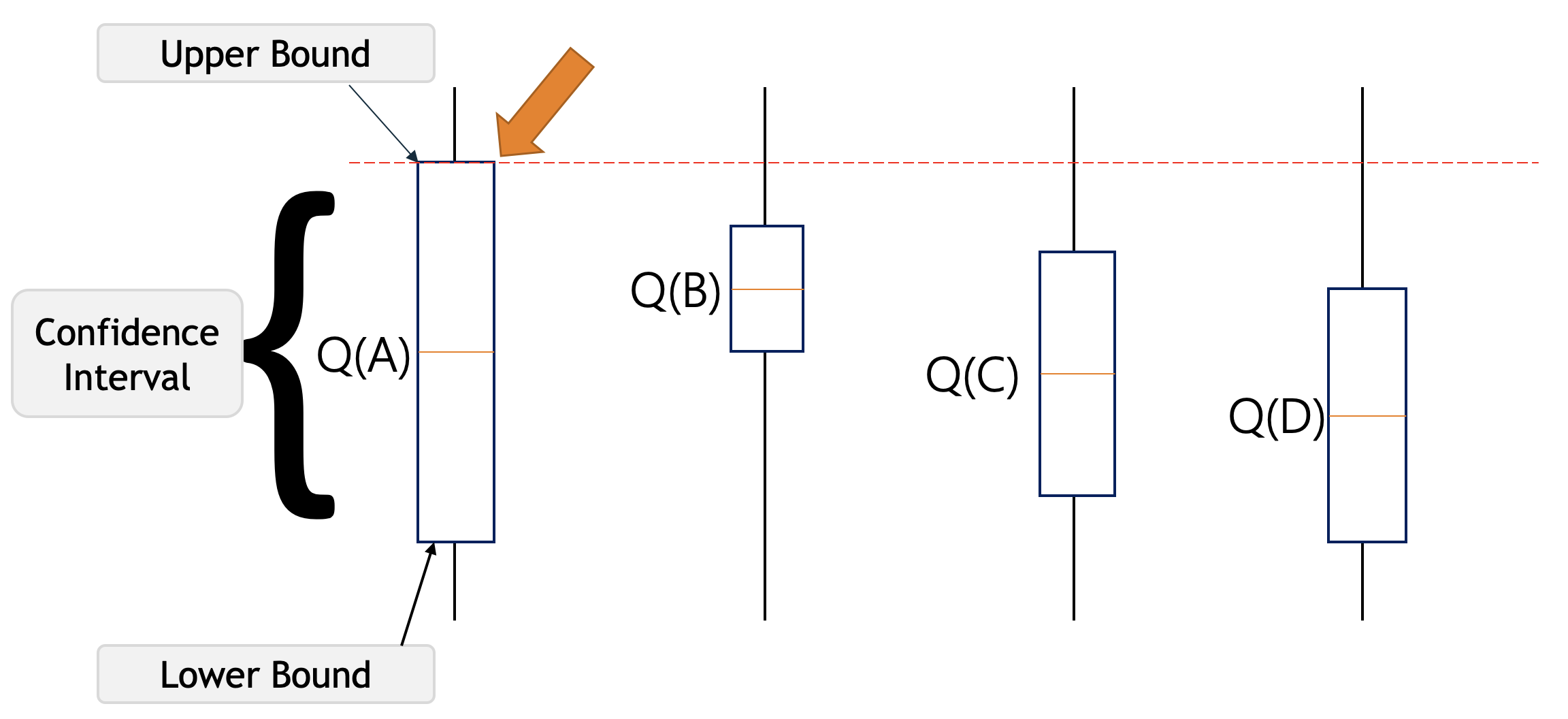
Por ejemplo, digamos que tenemos estas cuatro acciones con incertidumbres asociadas en la imagen a continuación, nuestro agente no tiene idea de cuál es la mejor acción. Entonces, de acuerdo con el algoritmo UCB, elegirá de manera optimista la acción que tenga el límite superior más alto, es decir, A . Al hacer esto, tendrá el valor más alto y obtendrá la recompensa más alta, o al tomar eso, aprenderemos sobre una acción de la que sabemos menos.
Supongamos que después de seleccionar la acción A terminamos en el estado que se muestra en la imagen a continuación. Esta vez UCB seleccionará la acción B ya que Q(B) tiene el límite de confianza superior más alto porque su estimación del valor de la acción es la más alta, aunque el intervalo de confianza es pequeño.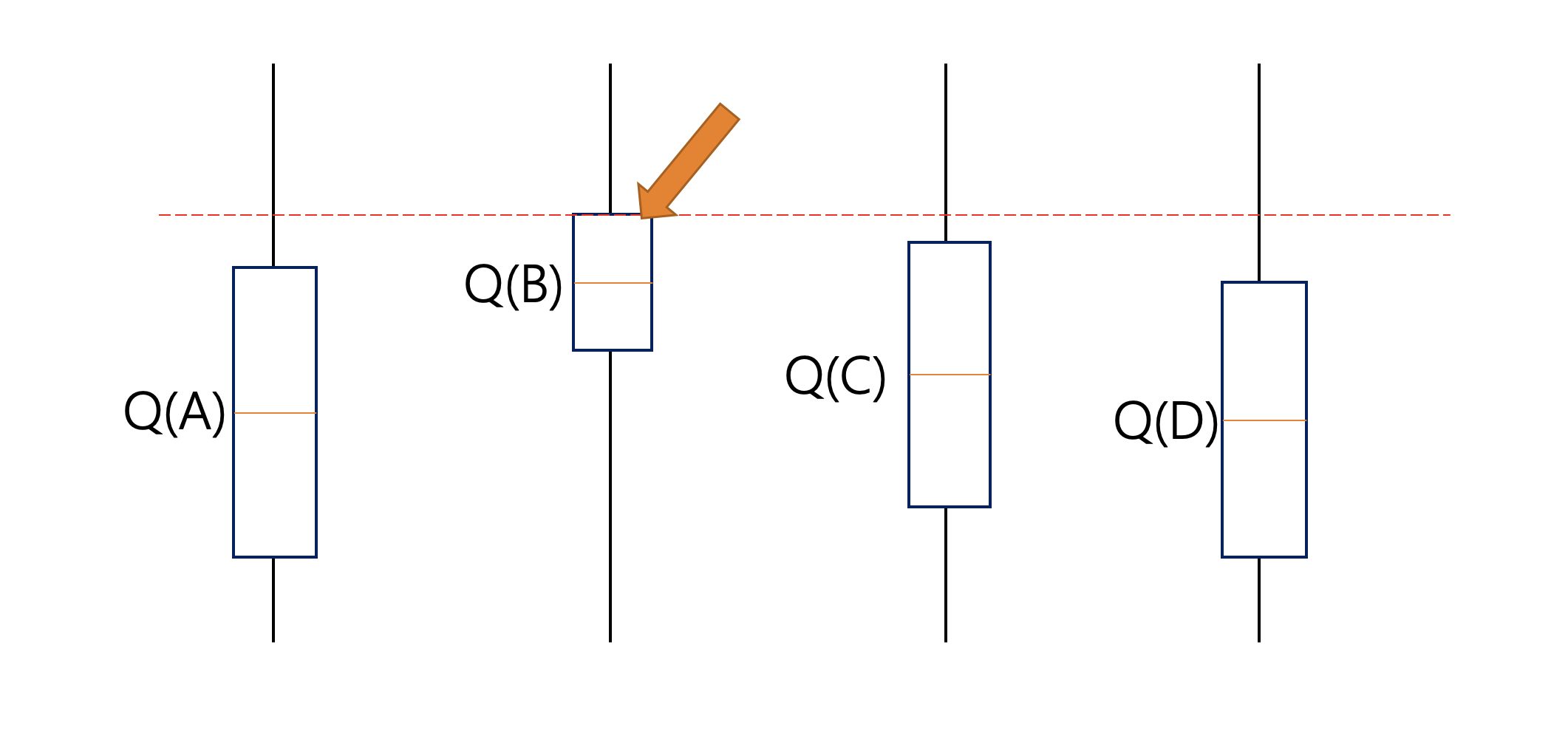
Inicialmente, UCB explora más para reducir sistemáticamente la incertidumbre, pero su exploración se reduce con el tiempo. Así podemos decir que UCB obtiene mayor recompensa en promedio que otros algoritmos como Epsilon-greedy, Optimistic Initial Values, etc.