En este artículo, discutiremos las fases del ciclo de vida de Big Data Analytics. Se diferencia del análisis de datos tradicional, principalmente por el hecho de que en Big Data, el volumen, la variedad y la velocidad forman la base de los datos.
El ciclo de vida de Big Data Analytics se divide en nueve fases, nombradas como:
- Caso de negocio/Definición de problema
- Identificación de datos
- Adquisición y filtración de datos
- Extracción de datos
- Munging de datos (validación y limpieza)
- Agregación y representación de datos (almacenamiento)
- Análisis exploratorio de datos
- Visualización de datos (Preparación para modelado y evaluación)
- Utilización de los resultados del análisis.
Analicemos cada fase:
- Fase I Definición del Problema de Negocio –
En esta etapa, el equipo aprende sobre el dominio de negocio, que presenta la motivación y los objetivos para realizar el análisis. En esta etapa, se identifica el problema y se hacen suposiciones sobre la ganancia potencial que obtendrá una empresa después de realizar el análisis. Las actividades importantes en este paso incluyen enmarcar el problema comercial como un desafío de análisis que se puede abordar en las fases posteriores. Ayuda a los responsables de la toma de decisiones a comprender los recursos comerciales que se requerirán para ser utilizados, determinando así el presupuesto subyacente requerido para llevar a cabo el proyecto.
Además, se puede determinar si el problema identificado es un problema de Big Data o no, en función de los requisitos comerciales en el caso comercial. Para calificar como un problema de big data, el caso de negocios debe estar directamente relacionado con una (o más) de las características de volumen, velocidad o variedad.
- Definición de datos de fase II:
una vez que se identifica el caso comercial, ahora es el momento de encontrar los conjuntos de datos apropiados para trabajar. En esta etapa se hace un análisis para ver qué han hecho otras empresas por un caso similar.
Según el caso de negocio y el alcance del análisis del proyecto que se aborda, las fuentes de los conjuntos de datos pueden ser externas o internas de la empresa. En el caso de conjuntos de datos internos, los conjuntos de datos pueden incluir datos recopilados de fuentes internas, como formularios de comentarios, de software existente. Por otro lado, para conjuntos de datos externos, la lista incluye conjuntos de datos de proveedores externos.
- Fase III Adquisición y filtración
de datos: una vez que se identifica la fuente de datos, ahora es el momento de recopilar los datos de dichas fuentes. Este tipo de datos en su mayoría no está estructurado. Luego se somete a filtración, como la eliminación de datos corruptos o datos irrelevantes, que no tienen alcance para el objetivo del análisis. Aquí, datos corruptos significa datos que pueden tener registros faltantes, o aquellos que incluyen tipos de datos incompatibles.
Después de la filtración, una copia de los datos filtrados se almacena y comprime, ya que puede ser útil en el futuro, para algún otro análisis.
- Extracción de datos de fase IV:
ahora los datos se filtran, pero puede existir la posibilidad de que algunas de las entradas de los datos sean incompatibles. Para corregir este problema, se crea una fase separada, conocida como la fase de extracción de datos. En esta fase, los datos, que no coinciden con el alcance subyacente del análisis, se extraen y transforman de esa forma.
- Fase V Munging de datos:
como se mencionó en la fase III, los datos se recopilan de varias fuentes, lo que da como resultado que los datos no estén estructurados. Puede existir la posibilidad de que los datos tengan restricciones, que no sean adecuadas, lo que puede dar lugar a resultados falsos. Por lo tanto, existe la necesidad de limpiar y validar los datos.
Incluye la eliminación de datos no válidos y el establecimiento de reglas de validación complejas. Hay muchas formas de validar y limpiar los datos. Por ejemplo, un conjunto de datos puede contener pocas filas, con entradas nulas. Si hay un conjunto de datos similar, esas entradas se copian de ese conjunto de datos; de lo contrario, esas filas se eliminan.
- Fase VI Agregación y representación de
datos: los datos se limpian y validan, según ciertas reglas establecidas por la empresa. Pero los datos pueden estar distribuidos en varios conjuntos de datos y no es recomendable trabajar con varios conjuntos de datos. Por lo tanto, los conjuntos de datos se unen. Por ejemplo: si hay dos conjuntos de datos, a saber, la sección Académica del estudiante y la sección Detalles personales del estudiante, ambos pueden unirse a través de campos comunes, es decir, el número de registro.
Esta fase requiere un funcionamiento intensivo ya que la cantidad de datos puede ser muy grande. Se puede considerar la automatización, de modo que estas cosas se ejecuten, sin ninguna intervención humana.
- Análisis de datos exploratorios de la fase VII:
aquí viene el paso real, la tarea de análisis. Dependiendo de la naturaleza del problema de big data, se lleva a cabo el análisis. El análisis de datos se puede clasificar como análisis confirmatorio y análisis exploratorio. En el análisis confirmatorio, se analiza antes la causa de un fenómeno. La suposición se llama hipótesis. Los datos se analizan para aprobar o desaprobar la hipótesis.
Este tipo de análisis proporciona respuestas definitivas a algunas preguntas específicas y confirma si una suposición era cierta o no. En un análisis exploratorio, se exploran los datos para obtener información sobre por qué ocurrió un fenómeno. Este tipo de análisis responde “por qué” ocurrió un fenómeno. Este tipo de análisis no proporciona datos definitivos, mientras tanto, proporciona el descubrimiento de patrones.
- Fase VIII Visualización de datos:
ahora tenemos la respuesta a algunas preguntas, utilizando la información de los datos en los conjuntos de datos. Pero estas respuestas todavía están en una forma que no se puede presentar a los usuarios comerciales. Se requiere una especie de representación para obtener valor o alguna conclusión del análisis. Por lo tanto, se utilizan varias herramientas para visualizar los datos en forma gráfica, que los usuarios comerciales pueden interpretar fácilmente.
Se dice que la visualización influye en la interpretación de los resultados. Además, permite a los usuarios descubrir respuestas a preguntas que aún no se han formulado.
- Fase IX Utilización de los resultados del
análisis: se realiza el análisis, se visualizan los resultados, ahora es el momento de que los usuarios comerciales tomen decisiones para utilizar los resultados. Los resultados se pueden utilizar para la optimización, para refinar el proceso comercial. También se puede utilizar como entrada para que los sistemas mejoren el rendimiento.
El diagrama de bloques del ciclo de vida se muestra a continuación:
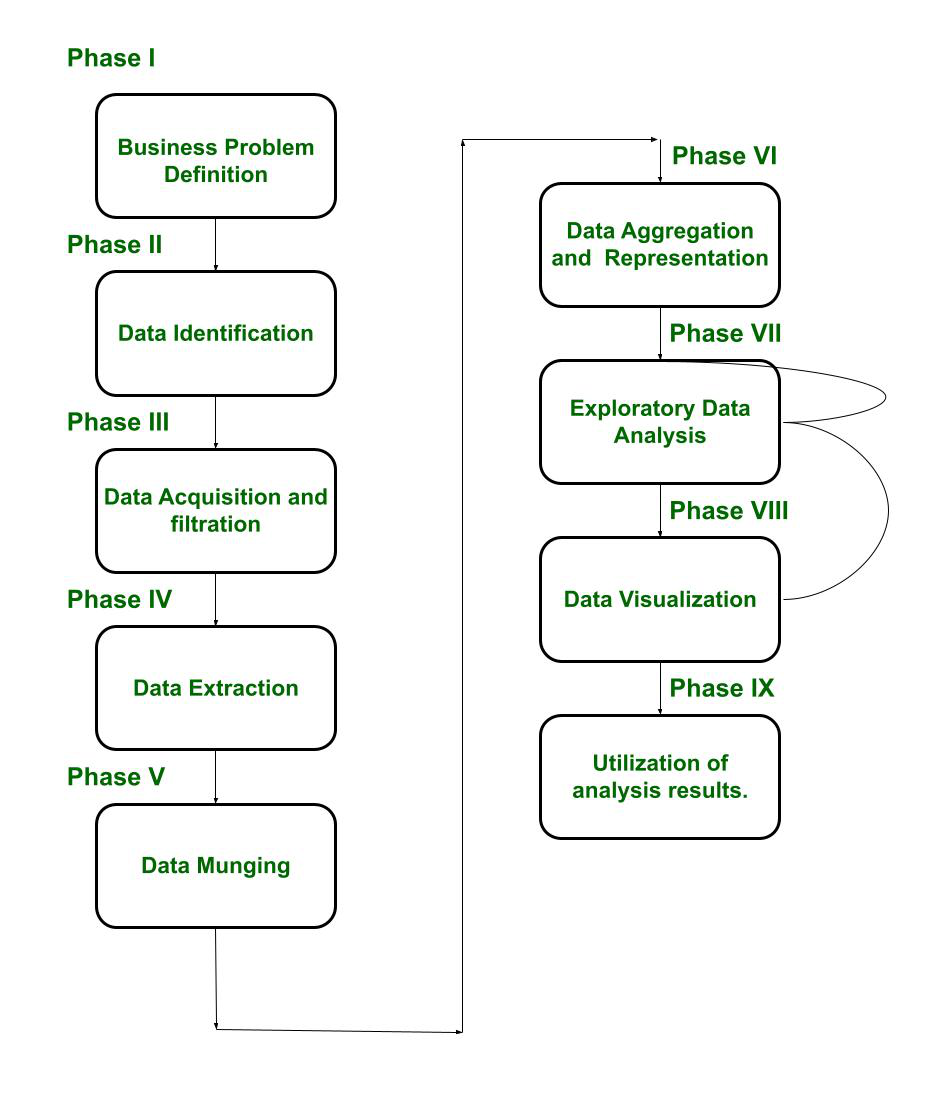
Es evidente del diagrama de bloques que la Fase VII, es decir, el análisis exploratorio de Datos, se modifica sucesivamente hasta que se realiza satisfactoriamente. Se pone énfasis en la corrección de errores. Además, se puede retroceder de la Fase VIII a la Fase VII, si no se logra un resultado satisfactorio. De esta manera, se asegura que los datos se analicen correctamente.
Publicación traducida automáticamente
Artículo escrito por duttabhishek0 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA