Se utilizan diferentes métricas de rendimiento para evaluar diferentes algoritmos de aprendizaje automático. En caso de problemas de clasificación, tenemos una variedad de medidas de rendimiento para evaluar qué tan bueno es nuestro modelo. Para el análisis de conglomerados, la pregunta análoga es cómo evaluar la «bondad» de los conglomerados resultantes.
¿Por qué necesitamos índices de validez de conglomerados?
- Comparar algoritmos de agrupamiento.
- Para comparar dos conjuntos de conglomerados.
- Para comparar dos clústeres, es decir, cuál es mejor en términos de compacidad y conectividad.
- Para determinar si existe una estructura aleatoria en los datos debido al ruido.
En general, las medidas de validez de conglomerados se clasifican en 3 clases, son:
- Validación interna del clúster : el resultado del agrupamiento se evalúa en función de los propios datos agrupados (información interna) sin referencia a información externa.
- Validación de clúster externa : los resultados de la agrupación se evalúan en función de algún resultado conocido externamente, como las etiquetas de clase proporcionadas externamente.
- Validación relativa de grupos : los resultados de la agrupación se evalúan variando diferentes parámetros para el mismo algoritmo (p. ej., cambiando el número de grupos).
Además del término índice de validez de grupo, necesitamos saber acerca de la distancia entre grupos d(a, b) entre dos grupos a, b y el índice intragrupo D(a) del grupo a .
La distancia entre grupos d(a, b) entre dos grupos a y b puede ser:
- Distancia de enlace simple: Distancia más cercana entre dos objetos pertenecientes a a y b respectivamente.
- Distancia de enlace completa: Distancia entre dos objetos más remotos pertenecientes a a y b respectivamente.
- Distancia media de enlace: Distancia media entre todos los objetos pertenecientes a a y b respectivamente.
- Distancia de enlace centroide : Distancia entre el centroide de los dos grupos a y b respectivamente.
La distancia dentro del grupo D(a) de un grupo a puede ser:
- Distancia de enlace de diámetro completo: Distancia entre dos objetos más lejanos pertenecientes al grupo a.
- Distancia de enlace de diámetro promedio: Distancia promedio entre todos los objetos pertenecientes al grupo a.
- Distancia de enlace del diámetro del centroide : el doble de la distancia promedio entre todos los objetos y el centroide del grupo a.
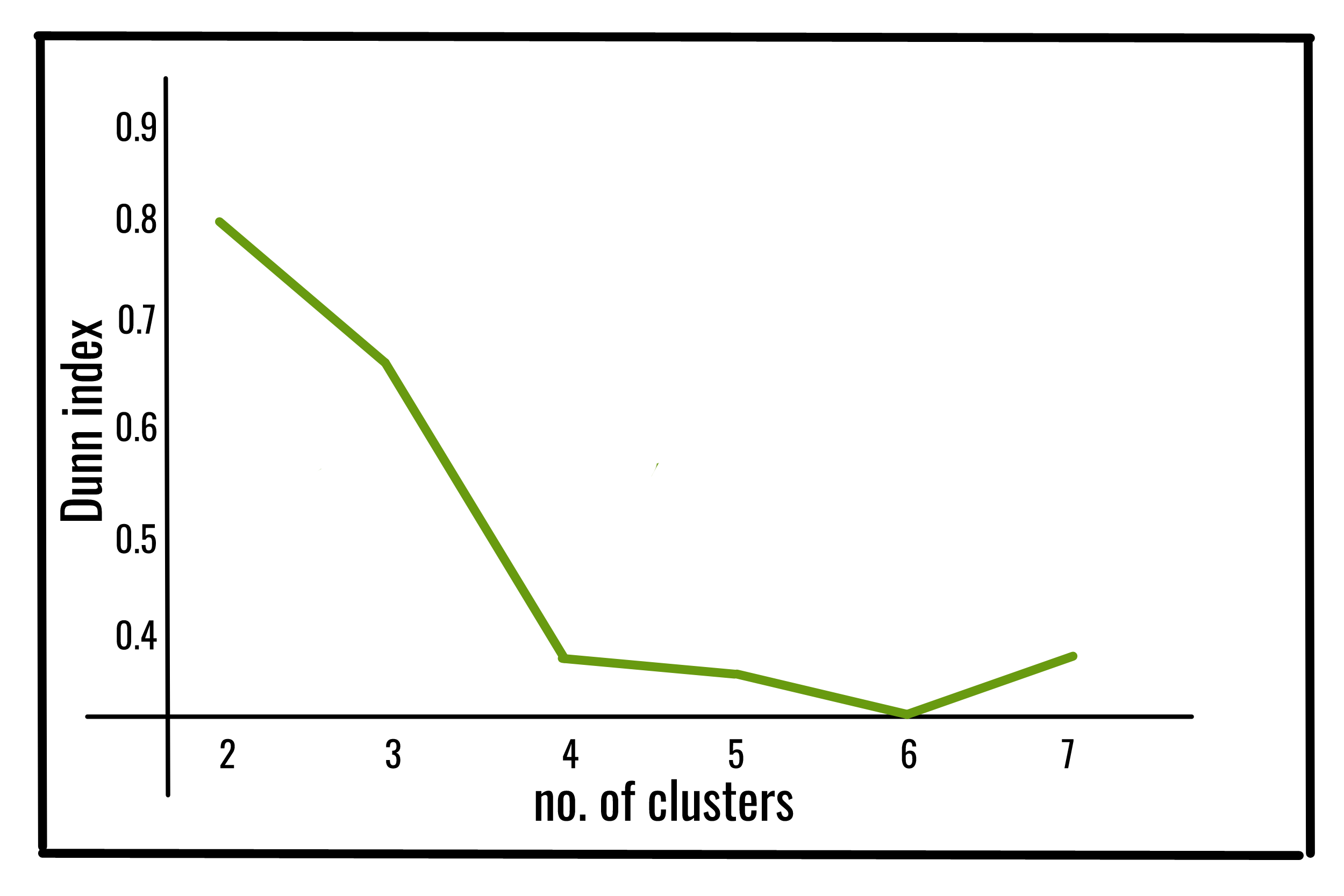
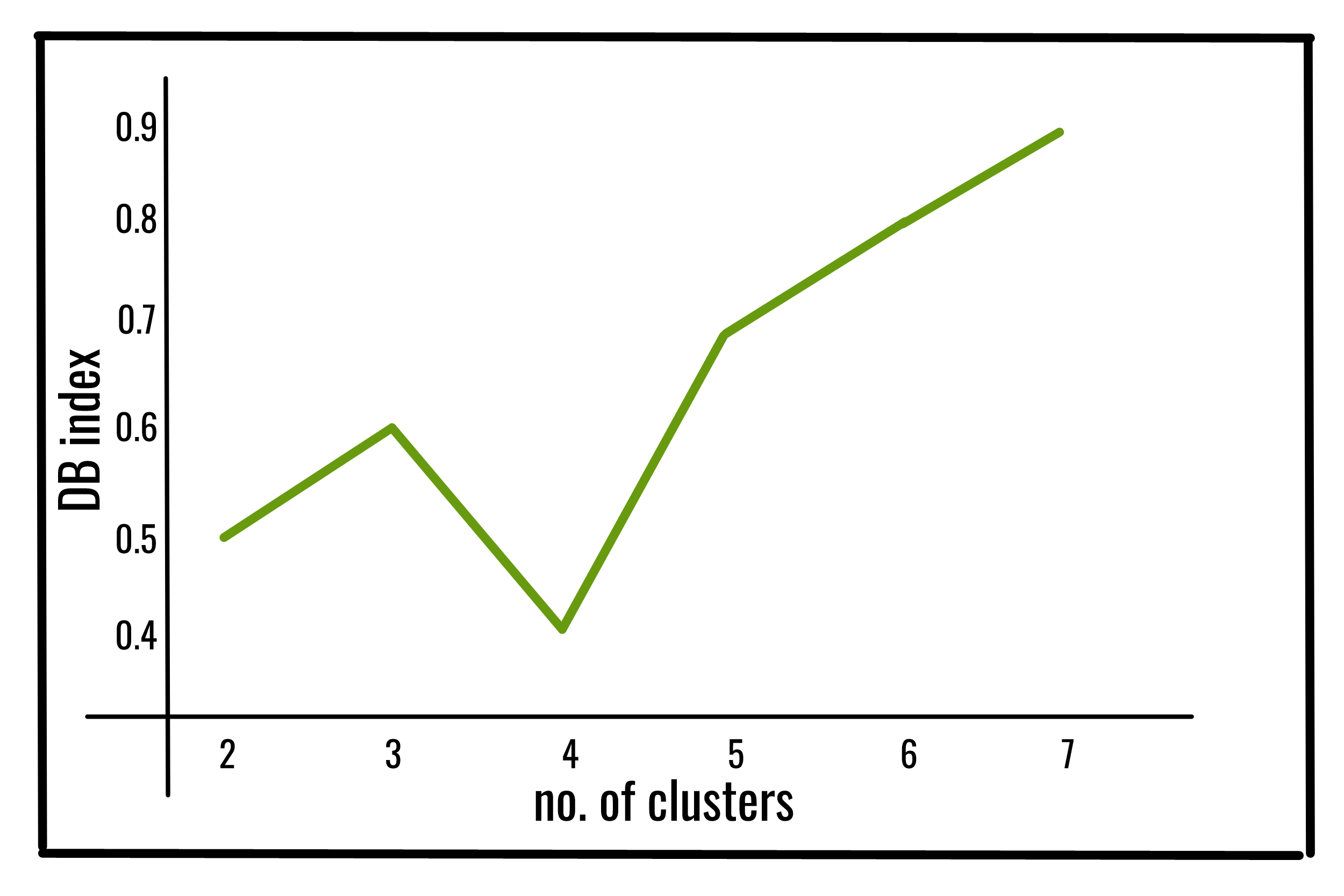
Ahora, analicemos 2 índices de validez de clúster internos, a saber, el índice de Dunn y el índice DB .
Índice de Dunn:
El índice de Dunn (DI) (introducido por JC Dunn en 1974), una métrica para evaluar algoritmos de agrupamiento, es un esquema de evaluación interno, donde el resultado se basa en los propios datos agrupados. Como todos los demás índices de este tipo, el objetivo de este índice de Dunn es identificar conjuntos de conglomerados que son compactos, con una pequeña variación entre los miembros del conglomerado y bien separados, donde las medias de diferentes conglomerados están lo suficientemente separadas, en comparación con el dentro de la varianza del conglomerado.
Cuanto mayor sea el valor del índice de Dunn, mejor es la agrupación. El número de conglomerados que maximiza el índice de Dunn se toma como el número óptimo de conglomerados k. También tiene algunos inconvenientes. A medida que aumenta el número de clústeres y la dimensionalidad de los datos, también aumenta el costo computacional.
El índice de Dunn para c número de grupos se define como:

dónde,

A continuación se muestra la implementación de Python del índice de Dunn anterior utilizando la biblioteca jqmcvi :
Python3
import pandas as pd from sklearn import datasets from jqmcvi import base # loading the dataset X = datasets.load_iris() df = pd.DataFrame(X.data) # K-Means from sklearn import cluster k_means = cluster.KMeans(n_clusters=3) k_means.fit(df) #K-means training y_pred = k_means.predict(df) # We store the K-means results in a dataframe pred = pd.DataFrame(y_pred) pred.columns = ['Type'] # we merge this dataframe with df prediction = pd.concat([df, pred], axis = 1) # We store the clusters clus0 = prediction.loc[prediction.Species == 0] clus1 = prediction.loc[prediction.Species == 1] clus2 = prediction.loc[prediction.Species == 2] cluster_list = [clus0.values, clus1.values, clus2.values] print(base.dunn(cluster_list))
Producción:
0.67328051
Índice de base de datos:
El índice de Davies-Bouldin (DBI) (introducido por David L. Davies y Donald W. Bouldin en 1979), una métrica para evaluar algoritmos de agrupamiento, es un esquema de evaluación interno, donde se realiza la validación de qué tan bien se ha realizado el agrupamiento. utilizando cantidades y características inherentes al conjunto de datos.
Baje el valor del índice DB, mejor es la agrupación. También tiene un inconveniente. Un buen valor reportado por este método no implica la mejor recuperación de la información.
El índice DB para k número de clústeres se define como:
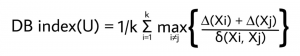
dónde,
A continuación se muestra la implementación de Python del índice DB anterior utilizando la biblioteca sklearn:
Python3
from sklearn import datasets from sklearn.cluster import KMeans from sklearn.metrics import davies_bouldin_score from sklearn.datasets.samples_generator import make_blobs # loading the dataset X, y_true = make_blobs(n_samples=300, centers=4, cluster_std=0.50, random_state=0) # K-Means kmeans = KMeans(n_clusters=4, random_state=1).fit(X) # we store the cluster labels labels = kmeans.labels_ print(davies_bouldin_score(X, labels))
Producción:
0.36628770
Referencias:
http://cs.joensuu.fi/sipu/pub/qinpei-thesis.pdf
https://en.wikipedia.org/wiki/Davies%E2%80%93Bouldin_index
https://en.wikipedia.org/ wiki/Dunn_index
https://pyshark.com/davies-bouldin-index-for-k-means-clustering-evaluation-in-python/
Publicación traducida automáticamente
Artículo escrito por Debomit Dey y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA