Procesamiento de datosse refiere a extraer o extraer conocimiento de grandes cantidades de datos. El término es en realidad un nombre inapropiado. Por lo tanto, la minería de datos debería haber sido nombrada más apropiadamente como minería de conocimiento que enfatiza la extracción de grandes cantidades de datos. Es un proceso computacional de descubrimiento de patrones en grandes conjuntos de datos que involucra métodos en la intersección de inteligencia artificial, aprendizaje automático, estadísticas y sistemas de bases de datos. El objetivo general del proceso de minería de datos es extraer información de un conjunto de datos y transformarla en una estructura comprensible para su uso posterior. También se define como la extracción de patrones o conocimientos interesantes (no triviales, implícitos, previamente desconocidos y potencialmente útiles) a partir de una gran cantidad de datos.Nombres alternativos para minería de datos:
1. Knowledge discovery (mining) in databases (KDD) 2. Knowledge extraction 3. Data/pattern analysis 4. Data archaeology 5. Data dredging 6. Information harvesting 7. Business intelligence
Minería de datos e inteligencia comercial: 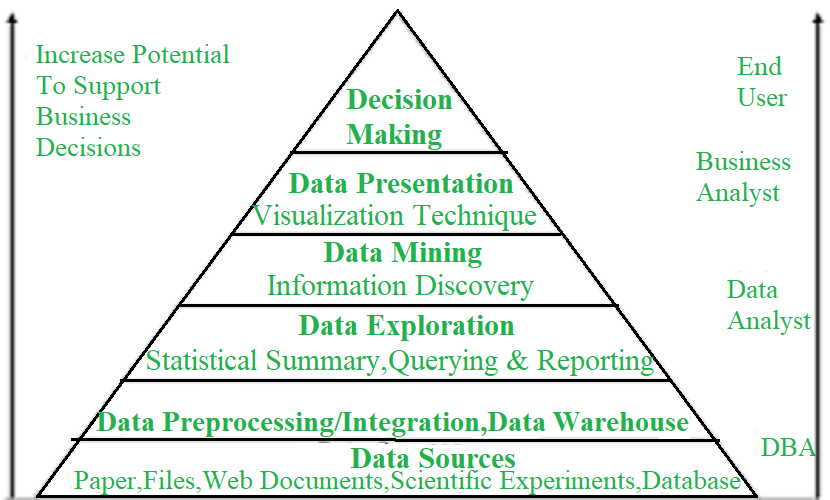 propiedades clave de la minería de datos:
propiedades clave de la minería de datos:
1. Automatic discovery of patterns 2. Prediction of likely outcomes 3. Creation of actionable information 4. Focus on large datasets and databases
Minería de datos: Confluencia de múltiples disciplinas – 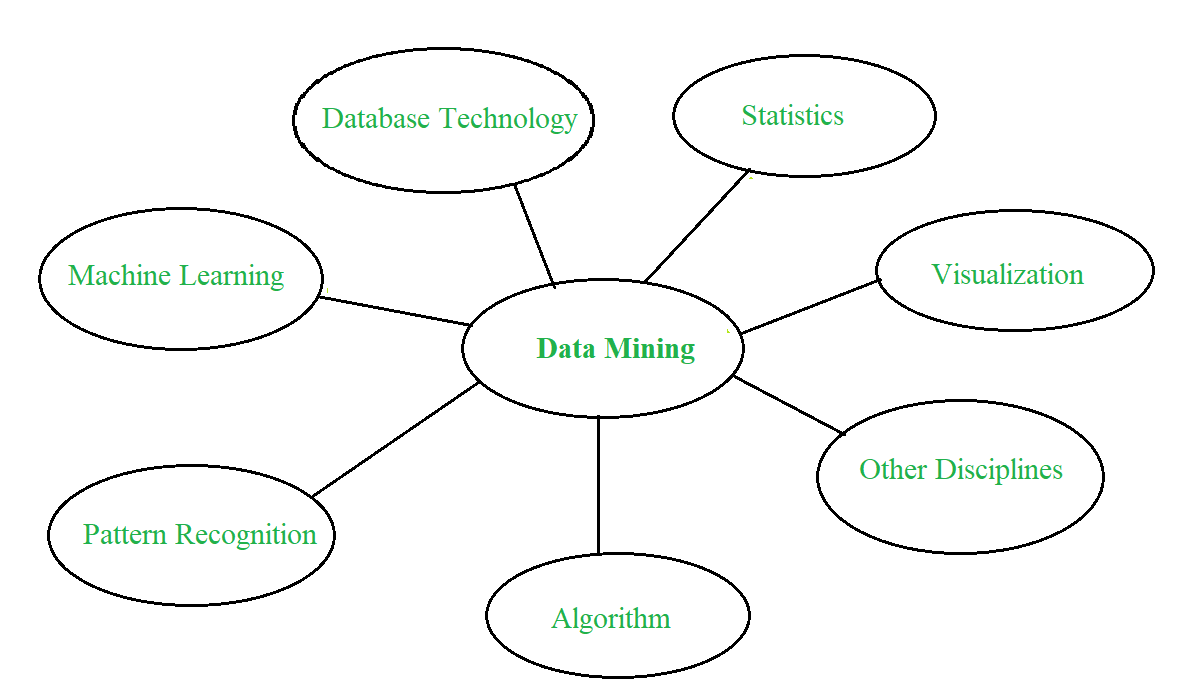 Proceso de minería de datos: La minería de datos es un proceso de descubrimiento de varios modelos, resúmenes y valores derivados de una colección de datos determinada. El procedimiento experimental general adaptado al problema de la minería de datos implica los siguientes pasos:
Proceso de minería de datos: La minería de datos es un proceso de descubrimiento de varios modelos, resúmenes y valores derivados de una colección de datos determinada. El procedimiento experimental general adaptado al problema de la minería de datos implica los siguientes pasos:
- Plantear el problema y formular la hipótesis: en este paso, un modelador generalmente especifica un grupo de variables para la dependencia desconocida y, si es posible, un tipo general de esta dependencia como hipótesis inicial. También podría haber varias hipótesis formuladas para un problema en esta etapa. El paso principal requiere experiencia combinada de un dominio de aplicación y un modelo de minería de datos. En la práctica, siempre significa una interacción profunda entre el experto en minería de datos y el experto en aplicaciones. En aplicaciones exitosas de minería de datos, esta cooperación no se detiene en la fase inicial. Continúa durante todo el proceso de minería de datos.
- Recolectar datos –Este paso se preocupa por cómo se genera y se recoge la información. En general, hay dos posibilidades distintas. El principal es cuando el proceso de generación de datos está bajo el control de un experto (modelador). Este enfoque se entiende como un experimento diseñado. La segunda posibilidad es cuando el experto no puede influir en el proceso de generación de datos. Esto a menudo se denomina enfoque observacional. En la mayoría de las aplicaciones de minería de datos se supone un entorno de observación, es decir, la generación aleatoria de datos. Por lo general, la distribución del muestreo se desconoce por completo después de recopilar los datos, o se proporciona parcial e implícitamente dentro del procedimiento de recopilación de datos. Sin embargo, es vital saber cómo la recopilación de datos afecta su distribución teórica, ya que dicho conocimiento previo suele ser útil para modelar y, posteriormente, para la interpretación final de los resultados. También, es importante estar seguro de que la información utilizada para estimar un modelo y, por lo tanto, los datos utilizados posteriormente para probar y aplicar un modelo provienen de una distribución muestral desconocida equivalente. Si este no suele ser el caso, el modelo estimado no se puede utilizar con éxito en una aplicación final de los resultados.
- Preprocesamiento de datos : en el entorno de observación, los datos generalmente se «recopilan» de las bases de datos, almacenes de datos y mercados de datos predominantes. El preprocesamiento de datos suele incluir un mínimo de dos tareas comunes:
- (i) Detección de valores atípicos (y eliminación): Los valores atípicos son valores de datos inusuales que no concuerdan con la mayoría de las observaciones. Comúnmente, los valores atípicos son el resultado de errores de medición, codificación y errores de registro y, a veces, son valores anormales naturales. Tales muestras no representativas pueden afectar seriamente el modelo producido posteriormente. Hay dos estrategias para manejar los valores atípicos: Detectar y eventualmente eliminar los valores atípicos como parte de la fase de preprocesamiento. Y Desarrollar métodos de modelado robustos que sean insensibles a los valores atípicos.
- (ii) Funciones de escalado, codificación y selección: el preprocesamiento de datos incluye varios pasos, como escalado variable y diferentes tipos de codificación. Por ejemplo, una característica con rango [0, 1] y otra con rango [100, 1000] no tendrán un peso equivalente dentro de la técnica aplicada. También influirán de manera diferente en los resultados finales de la minería de datos. Por lo tanto, se recomienda escalarlos y trasladar ambas características a un peso equivalente para su posterior análisis. Además, los métodos de codificación específicos de la aplicación generalmente logran una reducción de la dimensionalidad al proporcionar una cantidad menor de características informativas para el modelado de datos posterior.
- Modelo de estimación: la selección e implementación de una técnica de minería de datos aceptable es la tarea principal durante esta fase. Este proceso no es sencillo. Por lo general, en la práctica, la implementación se basa en varios modelos, y seleccionar el más simple es una tarea adicional.
- Interprete el modelo y saque conclusiones: en la mayoría de los casos, los modelos de minería de datos deberían ayudar a decidir. Por lo tanto, dichos modelos deben ser interpretables para que sean útiles porque es poco probable que los humanos basen sus decisiones en modelos complejos de «caja negra». Tenga en cuenta que los objetivos de precisión del modelo y precisión de su interpretación son algo contradictorios. Por lo general, los modelos simples son más interpretables, pero también son menos precisos. Se espera que los métodos modernos de minería de datos produzcan resultados muy precisos utilizando modelos de alta dimensión. El tema de la interpretación de estos modelos, también vital, se considera una tarea aparte, con técnicas específicas para validar los resultados.
 Clasificación de los sistemas de minería de datos:
Clasificación de los sistemas de minería de datos:
1. Database Technology 2. Statistics 3. Machine Learning 4. Information Science 5. Visualization
- Problemas principales en la minería de datos:
- Extracción de diferentes tipos de conocimiento en bases de datos: la necesidad de diferentes usuarios no es la misma. Diferentes usuarios pueden estar interesados en diferentes tipos de conocimiento. Por lo tanto, es necesario que la minería de datos cubra una amplia gama de tareas de descubrimiento de conocimiento.
- Extracción interactiva de conocimiento en múltiples niveles de abstracción: el proceso de extracción de datos debe ser interactivo porque permite a los usuarios centrarse en la búsqueda de patrones, proporcionando y refinando las requests de extracción de datos en función de los resultados devueltos.
- Incorporación de conocimientos previos: para guiar el proceso de descubrimiento y expresar patrones descubiertos, los conocimientos previos se pueden utilizar para expresar patrones descubiertos no solo en términos concisos sino en múltiples niveles de abstracción.
- Lenguajes de consulta de minería de datos y minería de datos ad-hoc: el lenguaje de consulta de minería de datos que permite al usuario describir tareas de minería ad-hoc debe integrarse con un lenguaje de consulta de almacén de datos y optimizarse para una minería de datos eficiente y flexible.
- Presentación y visualización de los resultados de la minería de datos: una vez que se descubren los patrones, es necesario expresarlos en lenguajes de alto nivel, representaciones visuales. Estas representaciones deben ser fácilmente comprensibles para los usuarios.
- Manejo de datos ruidosos o incompletos: se requieren métodos de limpieza de datos que puedan manejar objetos ruidosos e incompletos mientras se extraen regularidades de datos. Si no existen métodos de limpieza de datos, la precisión de los patrones descubiertos será deficiente.
- Evaluación de patrones: se refiere al interés del problema. Los patrones descubiertos deberían ser interesantes porque representan conocimiento común o falta de novedad.
- Eficiencia y escalabilidad de los algoritmos de minería de datos: para extraer información de manera efectiva de una gran cantidad de datos en las bases de datos, el algoritmo de minería de datos debe ser eficiente y escalable.
- Algoritmos de minería de datos paralelos, distribuidos e incrementales: factores como el gran tamaño de las bases de datos, la amplia distribución de los datos y la complejidad de los métodos de minería de datos motivan el desarrollo de algoritmos de minería de datos paralelos y distribuidos. Estos algoritmos dividen los datos en particiones que luego se procesan en paralelo. Luego, los resultados de las particiones se fusionan. Los algoritmos incrementales actualizan bases de datos sin tener que volver a minar datos desde cero.
Publicación traducida automáticamente
Artículo escrito por sriashi0397 y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA