En el artículo anterior, discutimos la prueba de hipótesis, que es la columna vertebral de la estadística inferencial. Anteriormente discutimos la prueba de hipótesis básica, incluida la hipótesis nula y alternativa, la prueba z, etc. Ahora, en esto discutimos más errores de tipo I y tipo II, nivel de significación (alfa) y potencia (beta).
Valor P:
El valor p se define como la probabilidad de obtener un resultado más extremo que el que realmente se observó en la distribución normal. En general, tomamos el nivel de significación = 0.05, lo que significa que si el valor p observado es menor que el nivel de significación, rechazamos la hipótesis nula.
Para calcular el valor p, necesitamos las estadísticas de prueba particulares de la tabla (prueba t, prueba z, prueba f) y si es una prueba de una o dos colas.
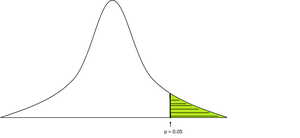
valor p
Prueba Alfa y Beta:
| La hipótesis nula es VERDADERA | La hipótesis nula es FALSA | |
|---|---|---|
| Rechazar hipótesis nula |
Error tipo I
|
decisión correcta
|
| No rechazar la hipótesis nula |
decisión correcta
|
Error tipo II
|




- Error tipo I (alfa): ahora, si rechazamos la hipótesis nula con base en los cálculos del valor p del nivel de significancia, existe la posibilidad de que las muestras, en realidad, pertenezcan a la misma distribución (nula), y rechazamos incorrectamente esto, esto se llama error Tipo I y se denota por alfa
- Error de tipo II (Beta) : ahora, sobre la base del nivel de significación y el valor p, si aceptamos una muestra que en realidad no pertenece a la misma distribución, se denomina error de tipo II.
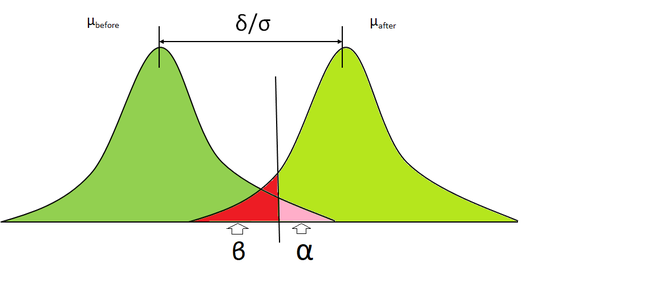
Intervalo de confianza y potencia:
- La confianza restando alfa y 1

- la

Cuanto mayor sea la potencia, menor será la probabilidad de cometer un error de tipo II. Una potencia más baja significa un mayor riesgo de cometer un error de tipo II y viceversa. En general, una potencia de 0,80 se considera lo suficientemente buena. El poder también depende de los siguientes factores:
- Tamaño del efecto: el tamaño del efecto es simplemente la forma de medir la fuerza de la relación entre dos variables. Hay muchas formas de calcular los tamaños del efecto, como las correlaciones de Pearson para calcular las correlaciones entre dos variables, la prueba d de Cohen para medir la diferencia entre grupos o simplemente calculando la diferencia entre las medias de diferentes grupos.
- Tamaño de la muestra: el número de observaciones que se incluyen en la muestra estadística.
- Significancia : Nivel de significancia utilizado en la prueba (alfa).
Pasos para realizar un análisis de potencia
- Enuncie la Hipótesis Nula (H 0 ) y la Hipótesis Alternativa (H A ).
- Indique el nivel de riesgo alfa (nivel de significancia).
- Elija la prueba estadística adecuada.
- Decide el tamaño del efecto.
- Cree planes de muestreo y determine el tamaño de la muestra. Después de eso, recolecte la muestra.
- Calcule la estadística de prueba determinando el valor p.
- Si p-value < alfa, entonces rechazamos la hipótesis nula.
- Repita los pasos anteriores varias veces.
Ejemplos
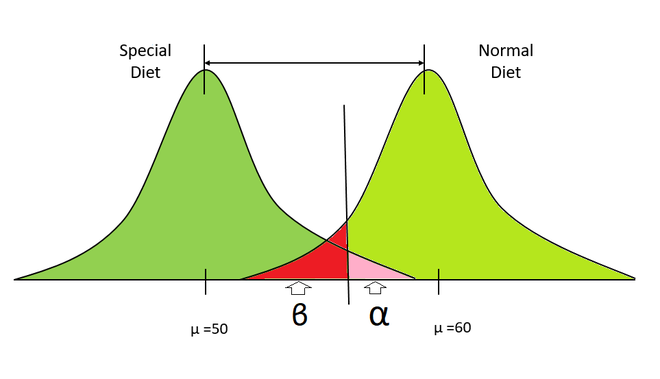
Distribución de dieta especial vs Distribución de dieta normal
- Supongamos que hay dos distribuciones que representan los pesos de dos grupos de personas, la izquierda representa a las personas que siguen una dieta y la derecha representa a las personas que consumen alimentos normales.
- Tomamos algunas muestras de ambas distribuciones y calculamos sus medias.
- Aquí, nuestra hipótesis nula será que ambas muestras pertenecen a la misma distribución (sin efecto del plan de dieta) y la hipótesis alternativa será que ambas muestras pertenecen a una distribución diferente.
- Ahora, calculamos el valor p de estas muestras.
- Si nuestro valor p es más pequeño que el nivel de significancia, entonces rechazamos correctamente la hipótesis nula de que ambas muestras pertenecen a la misma distribución.
- de lo contrario, no rechazamos la hipótesis nula.
- Ahora, repetimos los pasos anteriores varias veces (es decir, 1000, 10000), etc. y calculamos la probabilidad de rechazar correctamente la hipótesis nula, es decir, Potencia.
Implementación:
Python3
# Necessary Imports
import numpy as np
from statsmodels.stats.power import TTestIndPower
import matplotlib.pyplot as plt
# here effect size is taken as (u1-u2) /sd
effect_size = (60-50)/10
alpha = 0.05
samples =20
p_analysis = TTestIndPower()
power = p_analysis.solve_power(effect_size=effect_size, alpha=alpha, nobs1 = samples, ratio =1)
print("Power is ",power)
0.8689530131730794