La clasificación es la tarea en la que los objetos de varias categorías se clasifican en sus respectivas clases utilizando las propiedades de las clases. Un modelo de clasificación se utiliza típicamente para,
- Predecir la etiqueta de clase para un nuevo objeto de datos sin etiqueta
- Proporcione un modelo descriptivo que explique qué características caracterizan los objetos en cada clase
Existen varios tipos de técnicas de clasificación tales como,
- Regresión logística
- Árbol de decisión
- K-vecinos más cercanos
- Clasificador bayesiano ingenuo
- Máquinas de vectores de soporte (SVM)
- Clasificación aleatoria de bosques
Clasificadores de árboles de decisión en programación R
Un árbol de decisión es una estructura de árbol similar a un diagrama de flujo en el que el Node interno representa una función (o atributo), la rama representa una regla de decisión y cada Node hoja representa el resultado. Un árbol de decisión consta de,
- Nodes: prueba el valor de un determinado atributo.
- Edges/Branch: Representa una regla de decisión y se conecta al siguiente Node.
- Nodes hoja: Nodes terminales que representan etiquetas de clase o distribución de clase.
Y este algoritmo se puede implementar fácilmente en el lenguaje R. Algunos puntos importantes sobre los clasificadores de árboles de decisión son,
- es mas interpretable
- Maneja automáticamente la toma de decisiones
- Divide el espacio en espacios más pequeños
- Propenso al sobreajuste
- Se puede entrenar en un pequeño conjunto de entrenamiento.
- Mayormente afectado por el ruido
Implementación en R
El conjunto de datos:
Una población de muestra de 400 personas compartió su edad, género y salario con una empresa de productos, y si compraron el producto o no (0 significa no, 1 significa sí). Descargue el conjunto de datos Advert.csv .
R
# Importing the dataset
dataset = read.csv('Advertisement.csv')
head(dataset, 10)
Producción:
| ID de usuario | Género | Años | Salario Estimado | comprado | |
|---|---|---|---|---|---|
| 0 | 15624510 | Masculino | 19 | 19000 | 0 |
| 1 | 15810944 | Masculino | 35 | 20000 | 0 |
| 2 | 15668575 | Femenino | 26 | 43000 | 0 |
| 3 | 15603246 | Femenino | 27 | 57000 | 0 |
| 4 | 15804002 | Masculino | 19 | 76000 | 0 |
| 5 | 15728773 | Masculino | 27 | 58000 | 0 |
| 6 | 15598044 | Femenino | 27 | 84000 | 0 |
| 7 | 15694829 | Femenino | 32 | 150000 | 1 |
| 8 | 15600575 | Masculino | 25 | 33000 | 0 |
| 9 | 15727311 | Femenino | 35 | 65000 | 0 |
Entrenar los datos
Para entrenar los datos, dividiremos el conjunto de datos en un conjunto de prueba y luego crearemos clasificadores de árboles de decisión con el paquete rpart.
R
# Encoding the target feature as factor
dataset$Purchased = factor(dataset$Purchased,
levels = c(0, 1))
# Splitting the dataset into
# the Training set and Test set
# install.packages('caTools')
library(caTools)
set.seed(123)
split = sample.split(dataset$Purchased,
SplitRatio = 0.75)
training_set = subset(dataset, split == TRUE)
test_set = subset(dataset, split == FALSE)
# Feature Scaling
training_set[-3] = scale(training_set[-3])
test_set[-3] = scale(test_set[-3])
# Fitting Decision Tree Classification
# to the Training set
# install.packages('rpart')
library(rpart)
classifier = rpart(formula = Purchased ~ .,
data = training_set)
# Predicting the Test set results
y_pred = predict(classifier,
newdata = test_set[-3],
type = 'class')
# Making the Confusion Matrix
cm = table(test_set[, 3], y_pred)
- El conjunto de entrenamiento contiene 300 entradas.
- El conjunto de prueba contiene 100 entradas.
Confusion Matrix: [[62, 6], [ 3, 29]]
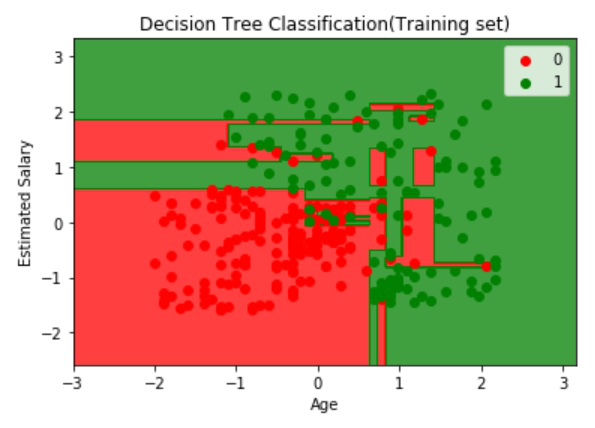
Visualización de los datos del tren:
R
# Visualising the Training set results
# Install ElemStatLearn if not present
# in the packages using(without hashtag)
# install.packages('ElemStatLearn')
library(ElemStatLearn)
set = training_set
# Building a grid of Age Column(X1)
# and Estimated Salary(X2) Column
X1 = seq(min(set[, 1]) - 1,
max(set[, 1]) + 1,
by = 0.01)
X2 = seq(min(set[, 2]) - 1,
max(set[, 2]) + 1,
by = 0.01)
grid_set = expand.grid(X1, X2)
# Give name to the columns of matrix
colnames(grid_set) = c('Age',
'EstimatedSalary')
# Predicting the values and plotting them
# to grid and labelling the axes
y_grid = predict(classifier,
newdata = grid_set,
type = 'class')
plot(set[, -3],
main = 'Decision Tree
Classification (Training set)',
xlab = 'Age', ylab = 'Estimated Salary',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid),
length(X1),
length(X2)),
add = TRUE)
points(grid_set, pch = '.',
col = ifelse(y_grid == 1,
'springgreen3',
'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1,
'green4',
'red3'))
Producción:
Visualización de los datos de prueba:
R
# Visualising the Test set results
library(ElemStatLearn)
set = test_set
# Building a grid of Age Column(X1)
# and Estimated Salary(X2) Column
X1 = seq(min(set[, 1]) - 1,
max(set[, 1]) + 1,
by = 0.01)
X2 = seq(min(set[, 2]) - 1,
max(set[, 2]) + 1,
by = 0.01)
grid_set = expand.grid(X1, X2)
# Give name to the columns of matrix
colnames(grid_set) = c('Age',
'EstimatedSalary')
# Predicting the values and plotting them
# to grid and labelling the axes
y_grid = predict(classifier,
newdata = grid_set,
type = 'class')
plot(set[, -3], main = 'Decision Tree
Classification (Test set)',
xlab = 'Age', ylab = 'Estimated Salary',
xlim = range(X1), ylim = range(X2))
contour(X1, X2, matrix(as.numeric(y_grid),
length(X1),
length(X2)),
add = TRUE)
points(grid_set, pch = '.',
col = ifelse(y_grid == 1,
'springgreen3',
'tomato'))
points(set, pch = 21, bg = ifelse(set[, 3] == 1,
'green4',
'red3'))
Producción:
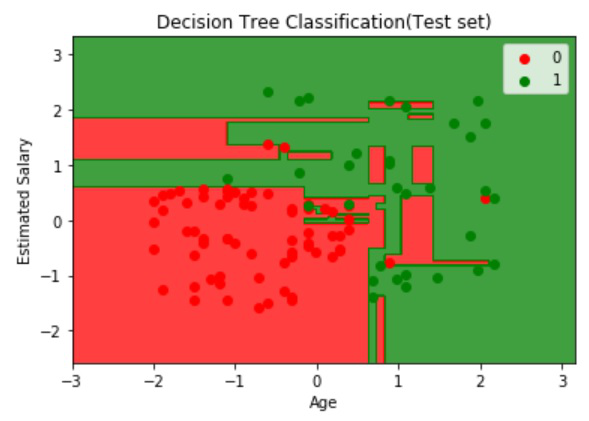
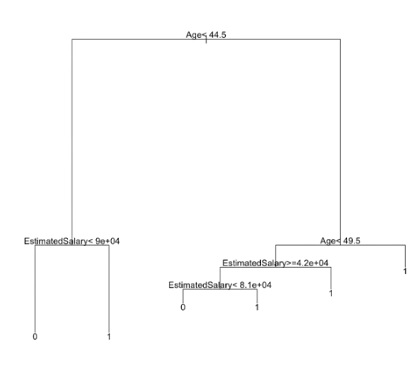
Diagrama de árbol de decisión:
R
# Plotting the tree plot(classifier) text(classifier)
Producción: