Introducción:
suponiendo que ya sabemos cómo funcionan los modelos Vanilla Seq2Seq o Encoder-Decoder, centrémonos en cómo llevarlo un paso más allá y mejorar la precisión de nuestras predicciones. Consideraremos el buen ejemplo antiguo de la traducción automática.
Motivación:
en un modelo Seq2Seq, el codificador lee la oración de entrada una vez y la codifica. En cada paso de tiempo, el decodificador usa esta incrustación y produce una salida. Pero los humanos no traducen una oración como esta. No memorizamos la entrada y tratamos de recrearla, es probable que olvidemos ciertas palabras si lo hacemos. Además, ¿es importante la oración completa en cada paso de tiempo, mientras se produce cada palabra? No. Solo ciertas palabras son importantes. Idealmente, necesitamos alimentar solo información relevante (codificación de palabras relevantes) al decodificador.
“Aprende a prestar atención solo a ciertas partes importantes de la oración”.
Objetivo:
Nuestro objetivo es llegar a una distribución de probabilidad, que diga, en cada paso de tiempo, cuánta importancia o atención se debe prestar a las palabras de entrada.
Cómo funciona:
Considere la siguiente arquitectura Codificador-Decodificador con Atención.
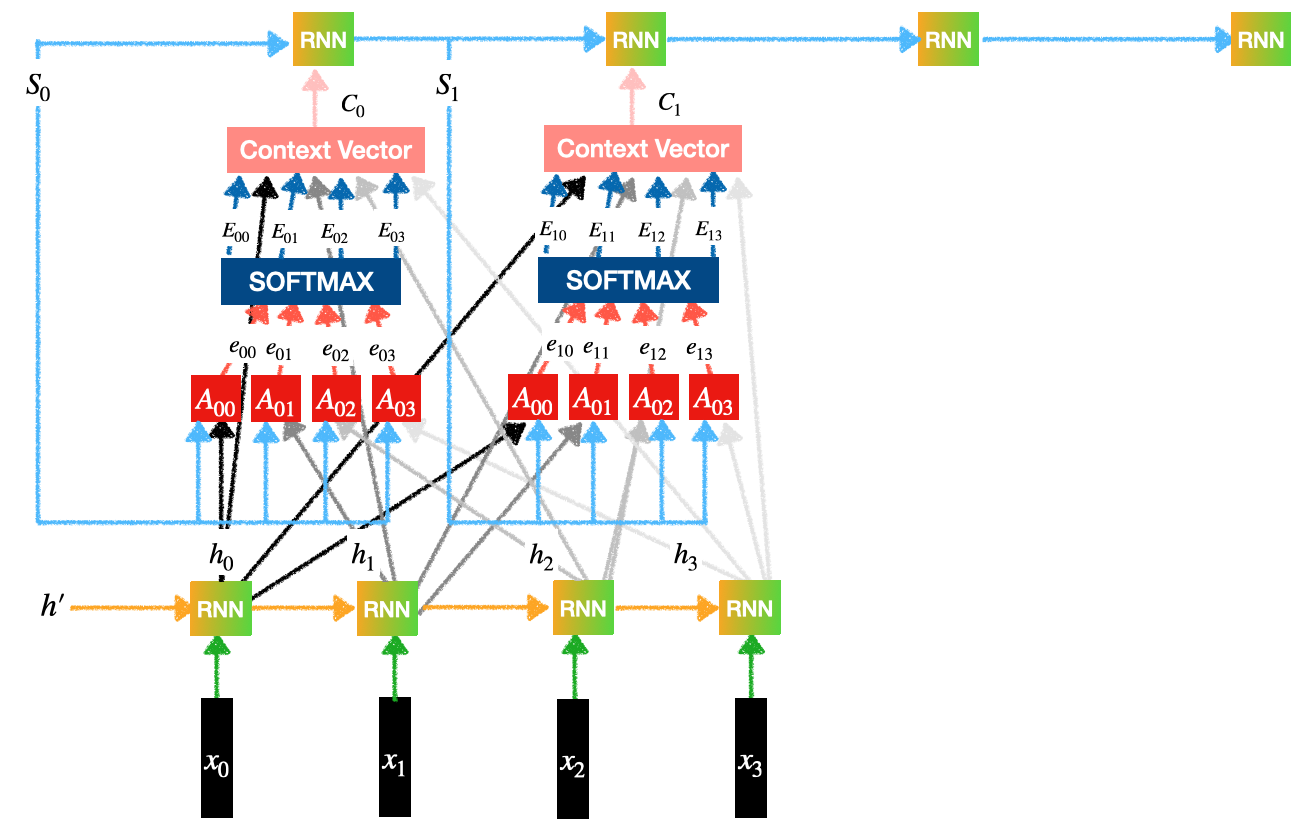
Codificador-Decodificador con Atención
Podemos observar 3 subpartes/componentes en el diagrama anterior:
- codificador
- Atención
- Descifrador
Codificador:
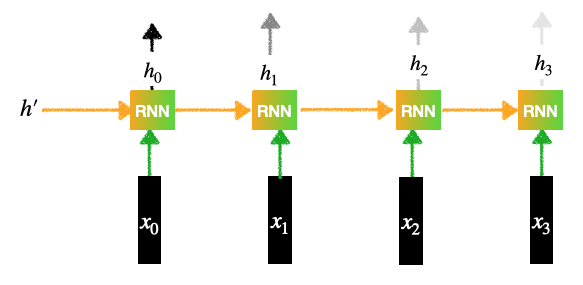
codificador
Contiene una capa RNN (pueden ser LSTM o GRU):
- Hay 4 entradas:

- Cada entrada pasa por una capa de incrustación.
- Cada una de las entradas genera una representación oculta.
- Esto genera las salidas para el codificador:

Atención:
- Nuestro objetivo es generar los vectores de contexto.
- Por ejemplo, el vector de contexto
 nos dice cuánta importancia/atención se debe dar a las entradas: .
nos dice cuánta importancia/atención se debe dar a las entradas: . - Esta capa a su vez contiene 3 subpartes:
- Red de avance
- Cálculo Softmax
- Generación de vectores de contexto
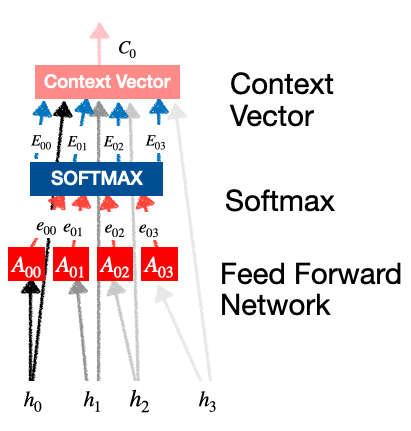
atención
Red de avance:
Feed-Forward-Network
Cada

es una red neuronal de avance simple con una capa oculta. La entrada para esta red de retroalimentación es:
- Estado anterior del decodificador
- Salida de estados del codificador.
Cada unidad genera salidas:  .
.  .
.  puede ser cualquier función de activación como sigmoid, tanh o ReLu.
puede ser cualquier función de activación como sigmoid, tanh o ReLu.
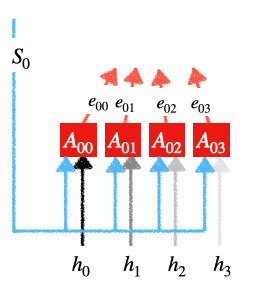
Cálculo Softmax:
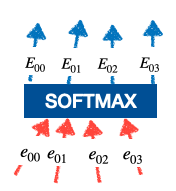
calculo softmax

Estas

se llaman los pesos de atención. Esto es lo que decide cuánta importancia se debe dar a las entradas.
.
Generación de vectores de contacto:
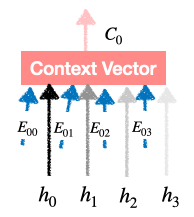
generación de vectores de contexto

.
Encontramos

de la misma manera y alimentarlo a diferentes unidades RNN de la capa Decoder.
Entonces, este es el vector final que es el producto de (Distribución de probabilidad) y (Salida del codificador) que no es más que la atención prestada a las palabras de entrada.
Decodificador:
alimentamos estos vectores de contexto a los RNN de la capa del decodificador. Cada decodificador produce una salida que es la traducción de las palabras de entrada.
Observación:
si conocemos los verdaderos pesos  de atención, habría sido más fácil calcular el error y luego ajustar los parámetros para minimizar esta pérdida. Pero en la práctica, no tendremos esto. Necesitamos que alguien anote manualmente cada palabra en un conjunto de palabras contribuyentes. Eso no es posible.
de atención, habría sido más fácil calcular el error y luego ajustar los parámetros para minimizar esta pérdida. Pero en la práctica, no tendremos esto. Necesitamos que alguien anote manualmente cada palabra en un conjunto de palabras contribuyentes. Eso no es posible.
Entonces, ¿por qué debería funcionar este modelo?
Este es un mejor modelo en comparación con los demás porque le estamos pidiendo al modelo que tome una decisión informada. Con suficientes datos, el modelo debería poder aprender estos pesos de atención tal como lo hacen los humanos. Y, de hecho, estos funcionan mejor que los modelos Vanilla Codificador-Decodificador.
Publicación traducida automáticamente
Artículo escrito por KeshavBalachandar y traducido por Barcelona Geeks. The original can be accessed here. Licence: CCBY-SA